1. 引言
商业预测是商业智能研究的重要问题之一。对于现代成熟企业而言,准确的预测商品的销售趋势能够很好的把握市场需求,为企业提供库存及营销方案的参考。随着新零售的发展,自动售卖机成为目前饱受关注的新领域。时间序列分析是自动售卖机销量预测的重要工具,在实际应用中,由于数据获取的限制,只能获得有限长度的历史数据,在这种情况下,能否建立可靠的预测模型还有待探讨。如何解决上述问题成为目前亟待解决的需求。
在自动售卖机的销量预测上,目前已经有了一定的研究。Tomas [1] 提出了监控系统获取产品的销售信息,通过不断对销售不佳的产品进行替换达到销售方案的优化。Feng-Cheng Lin [2] 等人将产品根据起销售业绩进行聚类,并通过决策树提取受欢迎产品的关键属性,最后用贝叶斯网络过滤销售产品。Hidetaka Sakai [3] 等人通过组合逻辑和多元回归预测模型来动态修正售货机销量预测的精度,已介于售货机制冷所消耗的能量。洪鹏,余世明 [4] 提出通过ARMA模型预测售货机受制约销量来补偿实际销量,再通过RBF神经网络进行销量预测。孙娜 [5] 等人通过考虑不同地理位置的影响,提出了基于灰色模型的销量预测研究。王庆阳 [6] 通过考虑间断性预测以及连续性预测对自动售卖机销量进行组合预测。
以上研究大部分是基于所有能获得的历史销售数据进行预测,而没有考虑影响自动售货机销量的外在因素以及不同时间序列长度对预测结果的影响,对于饮品自动售卖机而言,商品的销量往往受到强烈的温度、节假日、等因素影响,销量数据波动性较强。并且由于机器大小、故障等因素导致自动售卖机的销量会存在部分异常值。因此本文将利用某企业的销量时间序列数据以及获取到的外部环境数据,采用离差系数和小波变化结合的方法对异常值进行处理 [7],并且基于不同时间序列长度采用prophet [8] 模型对自动售卖机进行单机预测以及总体预测,并将不同时序长度的预测结果进行对比评估。
2. 相关理论
2.1. 离差系数
离差系数能够反映样本的离散程度,为了体现距离中位数较大数据与较小数据的离散程度,本文提出上离差系数与下离差系数:
其中
表示中位数,
表示大于中位数的数据,
表示小于中位数的数据,
表示上离差系数,
表示
的个数。
1) 阈值确定
根据上述公式计算cv1以及cv2,设定安全系数k1、k2,得到上下阈值
,
。
2) 异常值识别
其中
表示原始序列的值,
表示中位数,当
不在上下阈值范围内则为异常值。
3) 异常值处理
采用所在周(weekday)的饮品销量的平均值进行替换。
2.2. 小波变换
对于销量数据,其时间序列常具有周期性以及趋势性,只采用上下离散系数阈值方法进行处理只能识别极端异常值,而采用小波变换相结合得方法能够挖掘出时序数据的周期性以及趋势性。
对任意的
,称:
为一维信号x(t)依赖于参数a和τ的一维连续小波变换。
小波逆变换:
经过小波变换和逆变换,可实现小波的分解与重构,从而达到去噪的目的。
1) 采用上述公式得到去噪后的时间序列
2) 阈值确定
采用局部计算上离差系数与下离差系数,利用左右相邻的15条数据进行离差系数的计算,当左右相邻数据一方不足15条时,则选取全部数据。中位数用重构后的序列替代。设定安全系数k1、k2。
3) 异常值识别
其中
表示原始序列的值,
表示重构后序列的值,当
不在上下阈值范围内则为异常值。
4) 异常值处理
采用小波分解与重构后得到的新时间序列对应的值替换。
2.3. Prophet模型
Prophet采用的也是时间序列趋势分解的模型,得到三个部分:trend (趋势项),seasonality (周期性,包括年周期,月周期,周周期以及日周期等),holidays (节假日影响因子),可以用以下式子表示:
其中
分别表示趋势项、周期项、节假日项,最后一项表示整个模型中的不适应的残差部分。Prophet也是对模型的三个部分分别建模,最后组合生成预测数据。
1) 趋势成分
趋势部分的实现主要应用两种模型,一种饱和增长模型,一种分段线性模型;
饱和增长模型公式:
分段线性模型公式:
其中k为增长率,
为增长率的变化量,m是偏置参数,在该模型中均为随时间t变化的函数。
2) 周期部分
Prophet对周期性因子部分的处理采用的是傅里叶级数,并且可以手动调整傅里叶级数的阶数N。
其中P表示时间序列的周期,当周期为年时,P的值一般为365.25,当周期为周时,P值一般为7。
3) 节假日部分
节假日部分采用自回归矩阵进行计算:
其中i表示每一个节日,
为每年这个节日的日期。V表示节假日灵活度参数,其值越大,表示节假日对模型的影响越大。
4) 额外回归量
对于额外回归量,可以使用Add_regressor()的方法将其添加到模型的线性部分。具有回归量的值的列需要添加到拟合和预测数据框中。Add_regressor()可以将另一个时间序列作为回归量,但是预测的值在另一个时间序列中必须是已知的,如果未知,可以先对该部分时间序列进行预测。
3. 数据准备
3.1. 实验数据
本文主要以国内某公司自动售卖机的销售数据为研究对象,涉及销售设备154台,覆盖该城市大部分区域,时间主要为201801~201812销售数据,该数据集覆盖地区较广,设备数目较多,数据量相对完整。原始数据集包含主要数据信息如表1所示。
由于自动售卖机的销量受到许多因素的影响,本次考虑的外部因素主要时气象数据,节假日等,因此本文爬取分析了可获得的外部环境数据,主要数据信息如表2所示。

Table 1. Main fields of vending machine sales data
表1. 自动售货机销售数据主要字段
Table 2. Main fields of external data of vending machine
表2. 自动售货机外部数据主要字段
3.2. 数据预处理
由于目前该企业正处于上升阶段,自动贩卖机设备的数量处于不断上升的过程,所产生的数据由于各种原因会存在部分、整体缺失或者不合理的情况,无法直接用于分析与预测研究,因此需要对数据进行预处理操作,主要包含以下步骤:
1) 数据归约:
由于销量数据太过庞大,并且每条销量数据记录之间的间隔并不确定,因此需要对销量数据进行聚合处理。提取出销售数据中的关键信息,按照合适的时间粒度对初始数据进行整理,完成数据归约操作,得到售卖机销量数据表,本次选取的预测时间粒度为一天,反映了一天内用户购买的饮品数量。
2) 数据清洗:
对于接入的数据,很多都包含了缺失、异常或者类型不一致的字段数据,此时需要对数据进行数据清洗,数据清洗就是发现这些类型的数据并纠正这些类型的数据,其中包含数据一致性、无效值以及缺失值的处理,处理方法有补全、删除等。本次由于自动售卖机机器损坏或数据为接入等原因导致销量存在较多的缺失值与部分异常值;对于该部分缺失值与异常值军进行异常处理,采用离散系数和小波分析相结合的方式进行识别,识别后采用对应方法处理。
3.3. 数据分析
依据主观分析,温度对饮品的销量会产生较大的影响,此次采用散点图的形式判断温度与销量之间是否存在相关关系。
图1 为2018年销量与温度对应的关系图表,其中纵坐标表示不同温度对应的平均日销量,从图中可以发现饮品的销量与温度之间存在明显的相关关系,尤其是当温度越高时,相关关系越明显。因此可以将温度作为销量预测的一个影响变量。
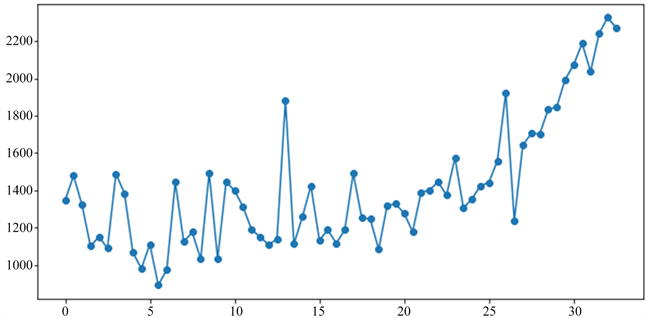
Figure 1. Relationship between sales and temperature
图1. 销量与温度关系图
4. 实验分析
由于机器故障、机器容量大小等原因,部分机器缺失值过多,因此本次选取缺失值较少的47台机器进行实验分析。分别采用时间长度为一年,半年,四个月,两个月,一个月的销量序列作为基础时间序列,采用prophet模型进行未来7天的单机以及总体销量预测,同时将温度因素作为变量之一。
为了更好的体现模型的优越性和实用性,本文采用平均百分比误差MAPE作为模型评估指标,定义如下:
4.1. 异常值识别
以10号站台01号机为例进行分析,如图2。
1) 上下离散系数初步检测:
图3中超出红线阈值部分为异常值,图4为采用周均值替代异常值之后的销量时序图。

Figure 2. Time sequence diagram of sales volume of station No. 01 on platform 10
图2. 10号站台01号机销量时序图

Figure 3. Initial detection of upper and lower thresholds
图3. 上下阈值初步检测

Figure 4. Sequence diagram after initial adjustment
图4. 初步调整之后序列图
2) 小波分析再次检测
图5为基于初步异常值检测及调整后的时间序列进行小波变换后得到的去噪时间序列;图6为计算得到的上下阈值,超出阈值曲线部分为异常值;图7中黑线为初步调整之后的时序图,红色点线为最终调整异常值之后得到时序图。
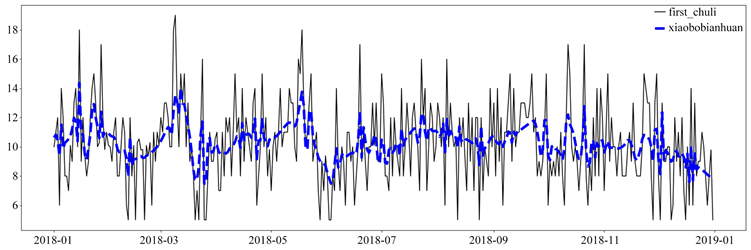
Figure 5. Sequence diagram after wavelet transform
图5. 小波变换后时序图
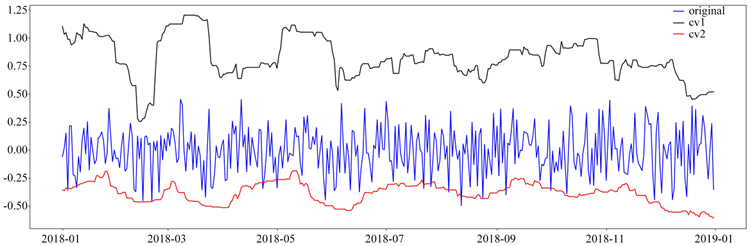
Figure 6. The upper and lower thresholds are tested again
图6. 上下阈值再次检测

Figure 7. Timing chart after adjusting again
图7. 再次调整之后时序图
4.2. 异常值调整前后时间序列预测评估
对47台机器进行异常值调整前后prophet预测结果进行指标评估,时间序列长度采取一年。
图8中橙色线图为异常值调整之前对47台机器预测的MAPE指标评估结果,蓝色波点线图为异常值调整之后对47台机器预测的MAPE指标评估结果,从图中可以发现异常值调整之后大部分机器的预测结果评估明显优于异常值调整之前。并且不同机器的评估指标值相较于之前较为平稳。
将47台机器的单台预测结果相加,得到47台机器总的预测结果。异常值调整前47台机器总预测结果MAPE评估指标为5.48%,调整之后MAPE为4.58%。
综上,不管是单机预测还是总体预测,异常值调整之后的指标评估结果均优于异常值调整之前,说明异常值处理结果合适。
4.3. 不同时间序列长度预测评估
1) 单机预测结果
对47台机器分别采用不同时间序列长度的prophet预测。MAPE评估指标结果如下表3。
从表3中我们可以发现对于不同的机器,最优的时间序列长度都不一样,因此对于单台机器需要具体分析,通过计算47台机器的平均MAPE指标值,一年、半年、四个月、两个月、一个月分别平均MAPE值为20.7%, 19.68%, 19.31%, 21.47%, 23.52%,并且对单机不同时间序列长度对应MAPE值比较结果进行综合分析,当时间序列长度为4个月或者6个月时,预测效果较好。
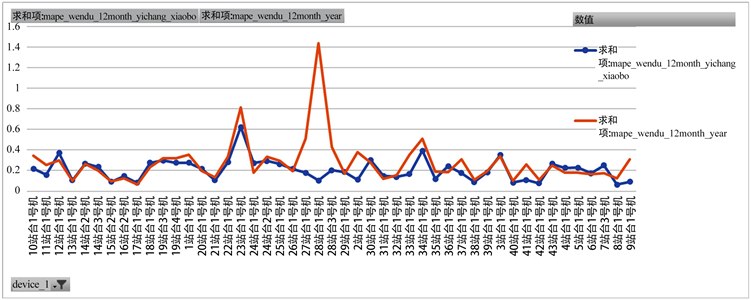
Figure 8. Time series prediction MAPE evaluation results before and after outlier adjustment
图8. 异常值调整前后时间序列预测MAPE评估结果
Table 3. Evaluate the MAPE value of the prediction results of a single machine under different time series lengths
表3. 不同时间序列长度下单台机器预测结果评估MAPE值
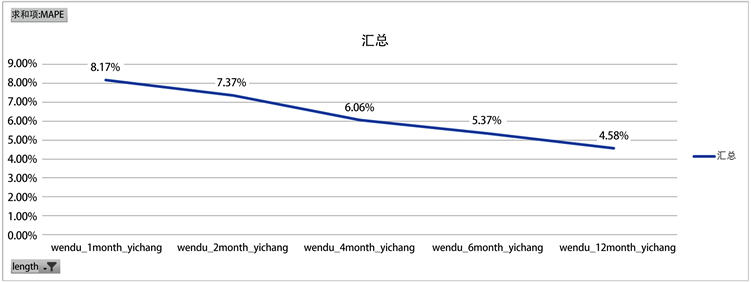
Figure 9. Cumulative forecast result MAPE indicator evaluation chart
图9. 累计预测结果MAPE指标评估图
2) 累计相加总体预测结果
对47台机器的预测结果进行累计相加,得到总体预测值。预测结果评估MAPE值如图9。
图9为不同时间序列长度对应的MAPE指标评估结果值,可以发现当时间序列长度为一年时,预测效果最好,因此对于总体预测,时间序列长度采取一年。
5. 结论
对于时间序列的预测而言,不同时间长度的销量序列与不同粒度的预测分析对预测结果都会产生一定的影响。对于本次的自动售卖机的销量预测而言,采用时间长度为一年的销量序列作为基础时间序列进行时,进行总体预测的预测精度是最优的,但是对于单机预测而言,需要单台机器进行具体分析,对于不同的机器可以适当的调整基础时间序列的长度来进行短期预测,但就单台机器的整体预测效果而言,当时间序列长度为4个月或者6个月时,预测精度最优。