1. 引言
近年来,随着计算机技术的日渐发展,计算机软件在我们的生活中扮演了一个重要的角色。由于人们的生活水平不断在提高,软件的需求程度也更高,因此其复杂度以及规模都有了很大的增加,随之而来的问题就是由于软件失效所造成的各种损失也开始变得严重起来。于是,作为一个评判软件质量的指标,软件可靠性受到了学者们的广泛关注 [1]。
软件自身是复杂的,会受到很多方面的影响,涉及到其开发过程、操作过程等很多因素,因此存在很多的不确定性。而通过已有的失效数据进行可靠性模型的构建,模拟软件失效的过程,是一种比较常见的方式。软件可靠性模型是对可靠性进行分析的经典方法。早在1964年,J. T. Duane就提出了Duane模型 [2],该模型认为单位时间内的失效次数是一个非齐次泊松过程。而在1972年,Jelinsk、Morand提出了一个软件可靠性模型J-M模型 [3],该模型做了一个最基本的假设也就是软件失效数是一个固定的常数且不会引入新的软件失效。这个模型直接推动了可靠性模型的发展,紧随其后涌现出了许多的软件可靠性模型,其中,以NHPP (Non-Homogeneous Poisson Process)模型为代表。而NHPP模型又有很多,在1975年由Schneidewind提出Schneidewind模型 [4],该模型认为不同的失效时间对应不同的分布函数,并提出了在软件失效的过程里,失效时间间隔可以看作一个随机过程,这也就是NHPP模型类模型的建模基本思路。1975年,J. D. Musa又提出了M-O模型 [5],并认为测试时间中的唯一有效的测度是执行时间。1979年Goel等人又提出了G-O模型 [6],假设能够在发现后立即处理软件失效,而不会因此引入新的失效。
随着科技的发展,越来越多的可靠性模型出现。然而到目前为止,依旧没有一种适应所有环境能够应对所有情况的最佳模型。即便某些模型在特定的数据集合上面有很好的预测效果,但是随着失效数的增多,也无法保证该模型依旧能有很好的表现。所以,模型的组合成为了一个值得研究的方向。ELC是最早被提出的一种模型组合方式,该模型简单地将基模型进行等权线性组合。但是这种方法考虑的太简单,由于主观上对权重进行均等划分,而并没有考虑任何失效时间所带的信息,所以使用起来的效果并不会很好。在这种模型线性组合思想的基础上,也出现了更多不同的加权方法 [7] [8] [9] [10]。本文通过对模型选择的不确定性进行考虑,并通过贝叶斯公式将其转换成一个递归问题从而求得各个模型的权重值。然后,在此基础上进行改进,将迭代次数设为一个常数而不是迭代到初始值,得到的权重值是只与最近几次的失效相关的,从而不会被久远以前的信息所影响,因此提高了模型的信息更新速度,并取得了不错的效果。
2. NHPP基本模型
2.1. 模型框架
不同的软件可靠性模型都有不同的形式以及不同的表达式,但是大多数的软件可靠性模型都是在一个框架之下建立的。对于不同类别的可靠性模型,根据他们不同的模型假设,推导出来的模型框架也是不同的。NHPP模型就是一类模型。他们的通用假设是一致的,对于不同的NHPP模型他们的区别在于一些特定假设的不同,这也决定了他们的结构特征的不同。NHPP模型的基本假设如下:
1) 在零时刻的软件失效数
,也就是
。
2)
是独立增量,
与先前的失效无关。
3) 在时间
一次失效发生的概率为
,其中
表示失效强度。
4) 在时间
产生的失效次数大于1的概率为
。
通过以上基本假设,可以推出软件失效数
是一个均值为
的泊松过程,表达式为:
其中,
是失效均值,与失效强度
的关系是:
。这就是NHPP模型的基本模型框架。对于不同的NHPP模型,他们的区别在于失效均值
的不同。表1给出了几个经典的NHPP模型的模型特征。
2.2. 参数估计
对于经典的软件可靠性模型的参数估计,估计方法有很多。在这里,对经典NHPP模型我们统一采用极大似然估计法来估计模型的参数。极大似然估计对于数据的要求分为失效时间间隔数据,以及失效计数数据。本文所使用的数据都是失效时间间隔数据,因此本文只给出数据类型为失效时间间隔数据的极大似然估计。
在NHPP模型基本假设下,似然函数为:
再求对数似然函数:
其中,
为待估计的参数向量,N为实际观测到的总失效数,
为第i次失效发生的时刻,并且
,
是由数据得到的失效时间间隔。由于单个NHPP模型都只有两个待估参数,使用极大似然估计比较容易得出合适的估计结果。但是在我们进行模型组合时,每增加一个基模型,所需要估计的参数量就增加了三个。而随着参数数量的增加,极大似然估计法的参数求解也就越来越困难。因此,对组合模型直接使用极大似然估计很难得出理想的效果,这也就是接下来我们要讨论的问题。
3. 模型组合
3.1. 模型组合方法
本文给出接下来几次的失效时间预测的组合模型,以下简称为COM模型。
将我们观测到的N次失效时间数据的失效时间间隔记为
。假设我们一共有M个基模型,对第i个基模型,将对其第m次失效时间的预测值记为记为
,那么第i个模型对第m次失效时间的预测误差是:
假设在我们的基模型中,预测效果最好的模型是第k个模型,那么,我们引入随机变量K来表示对第m次失效时间的预测模型的不确定性,定义如下:
由于k的取值为从1到M的正整数,所以根据贝叶斯公式,有:
不难观察得到:
第k个预测模型的预测误差也是一个随机变量
,也就是要求
如果我们能够获得随机变量
的分布,就能通过递归求出
的值了。对于随机变量
,我们通过基本模型的拟合,获得了N个样本,可以通过计算得到样本的期望
以及方差
。由于对总体我们没有已知的判断,所以这里我们使用最大熵原理(Maximum-Entropy Method),以求得的样本的期望和方差作为先验信息,获得随机变量
的分布。
对于连续型的随机变量,熵的计算表达式为:
通过最大熵原理,我们获得一个等式约束的最优化问题:
这个问题的解为:
,其中,
是归一化因子,
是拉格朗日乘子,通过:
计算得到。事实上,通过给定期望
以及方差
,由上面介绍的最大熵原理得到的密度函数就是正态分布
的密度函数。于是,对于第k个基模型,其预测误差服从正态分布
,其中
分别表示第k个基模型的误差样本的期望以及方差。于是,得到递推表达式:
于是我们可以计算出第k个模型在第m次预测的效果最好的概率,这个值也就是我们组合模型中第m次预测第k个模型所占的权重,也就是:
算法设计如下:
1) 通过观测到的失效时间数据求出各个基模型的参数
2) 令
3) 计算各个基模型的预测结果及误差,将其迭代至N,得出各个模型在第N次预测中所占的权重,并计算出组合模型的预测值。
3.2. 组合模型的改进
通过贝叶斯公式以及最大熵原理,我们得出了模型权重值的迭代式。但是,从表达式中可以看出来,无论时间过去多久,过去的信息都会对最新的预测结果产生影响。然而软件可靠性是逐渐变化的。目前的软件可靠性以及未来短期内的软件可靠性,更应该与最近几次的软件失效相关,而不应该被过去很久的失效信息大幅影响。
每个预测模型都有其独特的信息,可能在不同的时期会各有优劣。有些模型在数据波动较小的时候预测效果较好,而有些确在数据波动较大时有更好的预测效果。若是每一次预测都要与过去很久的预测信息有比较大的关系,很有可能会大幅度减少我们所获得的最近的失效所含有的信息。如果某个模型在前期的拟合效果不理想,而在最近几次的预测精度都很高,我们有理由相信这个模型在下几次的预测准度也会较高。但是如果前期的误差导致权重值
变得非常小,那么通过迭代,即使后期概率
很大,得到的权重值也会很小,也会需要很久的时间更新信息。通过以上的分析,本文提出一种基于时间步长的模型组合方法。
我们假设下一次失效的发生只与最近的T次失效有关系。对于大于T次的失效时间预测,我们将从第T次失效前开始进行迭代而不是从头开始。也就是说,在对第N次失效时间进行预测时,我们只迭代到第N-T次。此时,我们直接舍弃掉第N-T次失效之前的信息,令
,这样的方法能更好的掌控模型最近时间段的趋势,也更合理一些。改进后的算法设计如下:
1) 通过观测到的失效时间数据求出各个基模型的参数。
2) 若
,令
,计算各个基模型的预测结果及误差,将其迭代至N,得出各个模型在第N次预测中所占的权重,并计算出组合模型的预测值。
3) 若
,令
,将其迭代至N,得出各个模型在第N次预测中所占的权重,并计算出组合模型的预测值。
由该算法计算出的预测值,消除了在最近T次失效的失效时间之前的预测结果对现在的预测结果所产生的影响,更加符合真实情况,获得的权重值更加合理。我们将改进后基于时间步长的组合模型记为COM-T。
4. 实例分析
为了验证我们提出的组合模型COM-T的有效性,我们将改进后的与时间步长有关的模型COM-T跟考虑所有时间的信息的模型COM进行分析比较,这里分别取步长T = 3,4,5进行讨论。本文这里使用的基模型有三个,分别是G-O模型、M-O模型和Duane模型。将本文所提出的两个组合模型与基模型,以及等权重线性组合模型ELC模型进行比较,其中
,
是各失效时间预测函数。两个由前t次失效时间数据求出的组合模型COM-T、COM对第t + 1次失效的预测是:
其中
表示模型个数,
表示在对第t + 1次失效预测时第i个模型所占的权重值。
4.1. 评判指标
对于模型的好坏的评估,我们需要一些指标来进行比较评判。本文使用软件可靠性中常用的几个指标如下:
相对误差RE(relative error):
均方误差MSE(mean square error):
相对均方误差RMSE(relative mean square error):
其中,
表示数据的真实值,而
表示数据的预测值。这三个值越小,就说明预测值与真实值的差越小,也就是模型的预测效果更好。
4.2. 模型比较
本文使用来自文献 [11] 和文献 [12] 的两个失效时间间隔数据,对模型短时间的预测效果进行分析评判。其中数据集1有61个失效时间间隔数据,而数据集2有101个失效时间间隔数据。我们将最后五个数据作为测试集,将之前的所有数据作为训练集,分别对两组数据进行分析。
4.2.1
. 数据集1
对给定的失效时间间隔数据,先使用极大似然估计法求出各个基模型的参数值,如表2所示,再给出基模型以及ELC的失效数–失效时间在训练集上的拟合曲线,如图1所示。

Table 2. Parameters of basic models in dataset 1
表2. 数据集1的基模型参数

Figure 1. Fitting curve of failure numbers of basic models in dataset 1
图1. 数据集1基模型失效数拟合曲线
数据集1所得出的COM-T模型对于不同的T = 3,4,5以及COM模型接下来五次失效时间预测时的各个基模型的权重值如表3所示。
Table 3. The weights of basic models in five predictions in dataset 1
表3. 数据集1的基模型在五次预测中的权重值
再通过求得的权重得出各模型的预测值,并计算出各个评判指标。结果如图2以及表4所示。
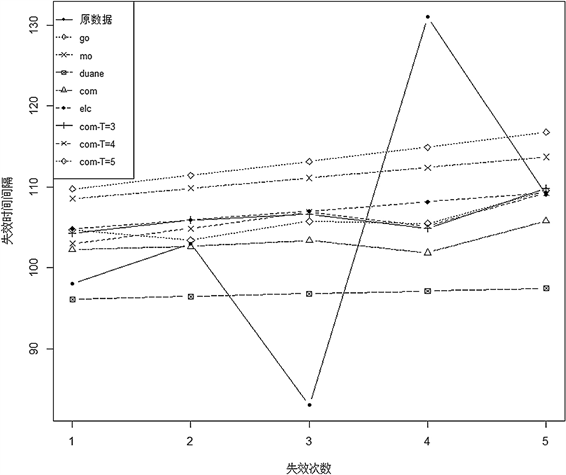
Figure 2. Predictions of failure times of basic models in dataset 1
图2. 数据集1中的各模型的失效时间预测结果
Table 4. Judge index of each model in dateset 1
表4. 数据集1中的各模型的评价指标
事实上,结合预测结果与判别指标,可以发现,对于本文所使用的的数据集1,组合模型的各个指标都是优于基模型的。在T = 3时,基于步长的组合模型在T = 3时的相对误差RE以及相对均方误差RMSE略高于原COM模型,但是在T = 5时却在三个指标上都优于COM模型。这说明选择的步长T的取值不同,其与COM模型的优劣也会不同。当T = 3时我们忽略了太多的信息以致于预测的效果不理想,所以在利用更多的信息时,预测的效果会有显著提升。对于ELC模型,明显能看出其相对误差RE相较于COM模型以及COM-T = 3模型表现较好,这是由其取值平均的特性导致的。而另外的两个指标上其表现就不如其他的组合模型了。
4.2.2
. 数据集2
与数据集1的方法相同,我们先求出基模型的参数如表5所示,再给出失效时间的拟合曲线如图3所示。
Table 5. Parameters of basic models in dataset 2
表5. 数据集2的基模型参数
我们通过观察拟合曲线,不难发现Duane模型在失效时间400~800时的拟合偏差较大,但是在接近我们测试集的时间终点时,它又有较高的拟合精度。从直觉上,如果我们使用COM组合模型,考虑所有过去的时间信息,很有可能会被这段时间的信息所影响从而较大的改变该模型所占的权重。表6也说明了这一点。
Table 6. The weights of basic models in five predictions in dataset 2
表6. 数据集2的基模型在五次预测中的权重值
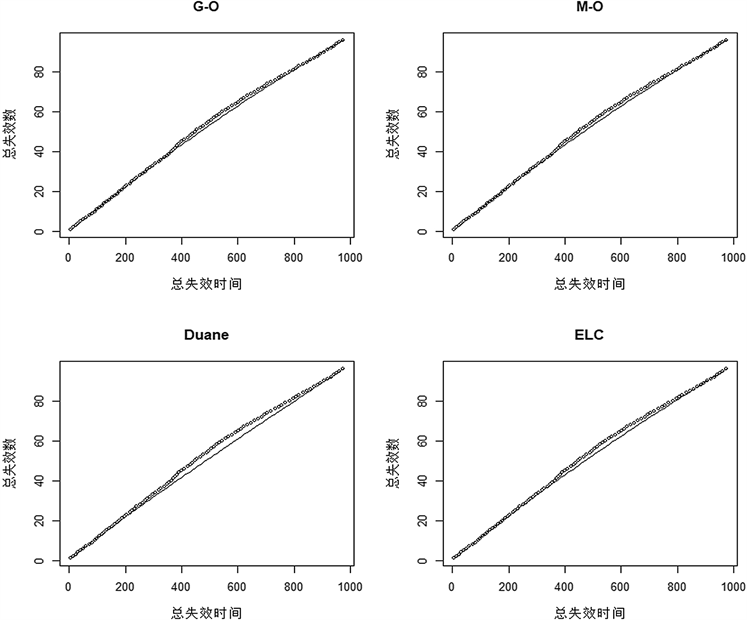
Figure 3. Fitting curve of failure numbers of basic models in dataset 2
图3. 数据集2基模型失效数拟合曲线
可以看出COM模型在预测过程中,基模型Duane模型的权重值基本上为0,也就是直接忽略掉了该模型所蕴含的信息。那么,我们通过预测效果图4以及评判指标表7来判断一下COM模型的预测效果:

Figure 4. Predictions of failure times of basic models in dataset 2
图4. 数据集2中的各模型的失效时间预测结果
Table 7. Judge index of each model in dataset 2
表7. 数据集2中的各模型的评价指标
显然,在忽略掉了Duane模型之后,COM模型的实质上变成了G-O模型以及M-O模型的组合。但是实际上在预测效果上Duane模型也有其自身的优势,COM模型由于其权重受长时间以前的影响较大,更新缓慢,导致了预测效果并不佳。对比考虑时间步长的COM-T模型,在T = 3,4,5的情况下,他们的三个评判指标RE,MSE,RMSE都是优于其他所有模型的。其中在T = 5时预测效果最好。这也印证了本文所提出的基于时间步长的改良组合模型的有效性。
5. 结论
本文提出了一种基于贝叶斯方法以及最大熵原理的模型组合方法来进行失效时间的短期预测,通过递归的形式求出每个失效时间预测时各个基模型所占的权重值,并在此基础上进行了改良,将递归的次数固定为步长T而不是递归到初始时间。实验证明了COM模型的有效性以及不足之处,而COM-T模型针对性地改进了原COM模型的不足,不考虑久远前信息,在预测精度上有很高的提升。结果说明,本文提出的COM-T模型的短期失效时间预测效果要优于传统的NHPP模型以及等权组合的ELC模型,是一种泛用性较强的组合模型。