1. 引言
目前自动电压控制系统中用来控制电压的阈值线是固定的,这种设定方法可能导致不必要的调压操作。本文希望提出一种能根据历史数据的变化,智能地设定阈值的方法,以提高电压调节的效率以及电压合格率。该方法的核心是对电压进行预测。本文利用历史数据中不同日期同一时刻的电压值作为输入变量,预测未来某时刻的电压值,然后根据电压值给出阈值设定方法。
2. 支持向量机回归
考虑样本如下
考虑线性拟合的情况,用下面的函数来拟合以上样本
(2.1)
假设函数(1)能够以精度
零误差地拟合样本,那么得到:
(2.2)
考虑到可能允许出现的拟合误差的情况,引入松弛变量
和
,(2.2)变成
(2.3)
通过最小化
来控制函数集的复杂度。再考虑到拟合误差的情况,线性回归问题转化成二次优化问题
(2.4)
其中,
,为一常数,作为超出拟合精度
的样本的惩罚因子。前一部分代表了函数的推广能力,后一部分代表了经验误差(即拟合函数对训练样本的误差),两个合起来就是统计学理论中提到的结构风险最小化。采用优化方法得到其对偶问题,在约束条件:
(2.5)
下,对拉格朗日因子
,最大化目标函数
(2.6)
可以求得回归函数
(2.7)
当函数
为非线性时,通过一种事先规定好的映射
,将样本投影到的一个特征空间(Hibert空间),进行线性回归。可以通过满足Mercer条件 [1] 的核函数
代替在其高维特征空间内积运算。公式(2.7)用核函数替换,得到特征空间的线性函数:
(2.8)
本文利用LIBSVM [2] 工具箱实现支持向量机回归算法。其中最重要的参数是SVM方法、核函数及其参数g,惩罚因子C,以及在本问题中输入变量的维度N。根据经验先采用ε-SVR及高斯径向核函数,C = 2,g = 1,N = 7,检验模型是否有效。得到结果如下图1、图2所示:

Figure 1. Comparison of forecast data and original data in the 8th day of 2012
图1. 2012年第8天预测数据及原始数据对比

Figure 2. Absolute error of forecast data on the 8th day of 2012
图2. 2012年第8天预测数据绝对误差
从图1、图2中结果看来,对于2012年第8天的电压预测,模型是有效的。我们定义一个绝对误差平均值来衡量对全年预测的效果。绝对平均误差:
(2.9)
其中,
为绝对误差平均值,是预测误差取绝对值后的平均值。
是每个预测点的绝对误差。
3. 对参数进行选择优化
对比不同SVM方法下,不同核函数的绝对误差平均值,我们得到表1、表2:

Table 1. Comparison of fitting effect of different kernel functions of ε-SVR method
表1. ε-SVR方法不同核函数的拟合效果对比
Table 2. Comparison of fitting effect of different kernel functions of v-SVM method
表2. v-SVM方法不同核函数的拟合效果对比
可以看出在v-SVM下,利用高斯径向核函数能取得最小的绝对误差平均值,因此模型SVM方法跟核函数就取为v-SVM及高斯径向核函数。
通过基于正交验证的网格寻优方法,将参数C和参数g在某区间内以某步长离散的取值,然后根据不同参数组合下的均方误差,取其最小值的组合作为我们模型的参数输入。先在大区间,利用大步长进行粗略的搜索,如图3所示。
其中,CVmse的定义如下:
(3.1)
其中,
为电压x矩阵中,电压
的预测值。m、n为要预测电压的行数和列数。
我们的目标是要找出CVmse最小的区域,然后进行精细搜索。观测CVmse等高线图,我们缩小搜索范围得到精细结果,如图4所示。
于是,得到目前最优的参数组合C = 0.125,g = 3.7321。

Figure 3. Rough selection of CVmse contour map with the lowest mean square error
图3. 粗略选择结果最低均方误差CVmse等高线图
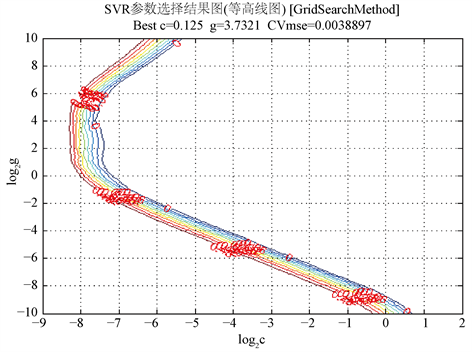
Figure 4. Precision selection of CVmse contour map with the lowest mean square error
图4. 精细选择结果最低均方误差CVmse等高线图
利用上面确定的SVM方法、核函数、参数C跟g,对比不同输入维度N下的绝对误差平均值,并画出其图形如图5所示。
从结果上看,维数7是区间[1, 8]中的一个极小值点,因此选择7天的电压数据作为输入变量,具有一定的合理性。但是纵观全局,在一个更大的区间[1, 200]内,存在一个最小值点在67处,其绝对平均误差为0.066766,相对于之前输入维数为7的时候的误差0.0674,取得了更进一步的优化。
至此,我们已经逐步将模型的所有参数进行了优化,同时,也确定了整个模型重要参数的最好选择方式,使得预测结果的误差得到不断地缩小,几次优化的结果如图6所示。

Figure 5. Graph of absolute mean error with respect to dimension of input data
图5. 绝对平均误差关于输入数据维数的关系图

Figure 6. Prediction error results of several parameter optimization
图6. 几次参数优化的预测误差结果
4. 模糊信息粒化
模糊信息粒化 [3] 就是以模糊集的形式表示信息粒子。用模糊集对时间序列进行信息粒化,主要步骤可以分为:粒化与模糊化。粒化就是将给定的时间序列划分为若干个小的子序列,每个小序列被称为一个窗口;而模糊化就是将粒化产生的每一个窗口进行模糊化,生成一个个模糊集也就是模糊粒子。将这两个步骤结合在一起,就是模糊信息化,称为f-粒化 [4]。
下面我们采用三角型模糊函数 [5] 以一个小时(即4个数据)为一个窗口的大小,一天共24个窗口(小序列)将2012年第一天电压数据的模糊信息粒化,提取主要特征:

Figure 7. Original voltage data of the first day of 2012
图7. 2012年第一天电压原始数据图
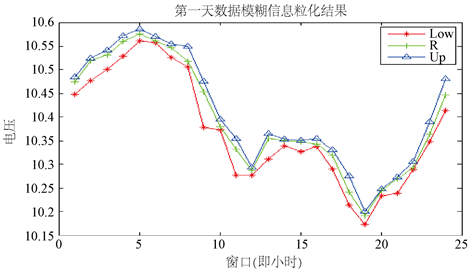
Figure 8. The first day data fuzzy information granulation results
图8. 第一天数据模糊信息粒化结果
从上面两个图,图7、图8,我们可以看出来经过模糊信息粒化之后,数据的基本特征本都被保留下来了。其中Low,R,Up分别对应着原始数据在每个窗口内变化的最小值,平均值和最大值。但是,数据由原来的96个,变成了由Low、R、Up各24点组成的特征向量组,起到了一定的提取特征、降维的作用 [6]。
定义第i天与第j天电压序列的距离为:
(4.1)
其中,
、
、
分别为第i天与第j天电压序列模糊信息粒化后Low、R、Up的距离。显然,
越小,第i天与第j天电压序列就越相似。
利用前面经过优化的SVM回归方法,先求出要预测那天的电压数据,然后以该序列作为查询序列,采用模糊信息粒化之后,跟模糊信息粒化后历史序列去匹配,最后以匹配结果作为最终预测结果。依然从301天开始作为测试数据集,在该天前的数据全部作为历史数据集。
用前面的方法预测第301天的电压数据,以及使用模糊信息粒化匹配,得到第301天电压结果如下图9所示:

Figure 9. Real voltage and two prediction results on the 301st day
图9. 第301天真实电压及两次预测结果
从图9上看,结果还是比较令人满意的,如果我们同样求第301天到第366天的绝对平均误差,会发现,其值为0.068251,相比之下,还是组合方法稍微精确一点。
5. AVC系统调压阈值设置策略
根据我们预测出来的结果,如果发现预测值只是超过警戒线,并没有超过合格线,那么可以在该预测时间点提前将警戒线调整至更靠近合格线的位置。比如,当预测值为10.63的时候,可以将上警戒线调整到10.7;当预测值为10.04时,将下警戒线调整到10.0。
这样做,我们就可以避免一些不必要的调整动作,避免电压的频繁调节,从而保证了理想的电压合格率。
6. 结束语
本文通过参数优化,利用支持向量机回归模型较准确地预测出了未来的电压值。结合模糊信息粒化方法,定义模式匹配算法,得到最终的电压预测方案,取得了令人满意的结果,并根据预测结果给出了阈值的设定策略。
基金项目
资助项目:中国南方电网科技项目《基于BART算法和超吸收壁Brown运动的AVC系统定值智能学习与过程控制技术研究》。