1. 引言
近年来,网络在人们生活中的地位越加凸显,在线社交网络已成为大多数人日常交流和互动的平台。社交网络中的用户影响力排序是意见领袖挖掘 [1]、影响力分析 [2] [3]、社会信任度 [4] 的普遍问题。PageRank [5] 算法被视为在社交网络中对用户影响力排序的通用算法,可将其用来衡量意见领袖挖掘以及影响力分析和社会信任度分析的一种措施。但该算法在应对悬挂节点(出度为0的节点)、不连通子图或出现环形有向图时会出现排序结果不唯一的现象,并且该算法用到的阻尼系数d对每个用户都是统一的,这点用在不同的用户身上存在着缺陷。Lv等 [6] 针对相关的情况,提出了一种LeaderRank算法,其是在网络中添加一个背景节点,并且将该背景节点与网络中的其他节点双向连接,得到一个G (N + 1, M + 2N)的新的强连通网络,如图1所示,对网络的噪音有很好的容忍性,相比PageRank算法收敛更快、准确性更高。
但是LeaderRank在社交网络分析中有一些限制,在网络中,可能存在一些重要的结构,这些结构可能会对节点的影响力或可信度产生影响。如图1所示,在LeaderRank算法中边e12、边e13和边e14的权重设为相同的值,但是我们可以看到,相比节点4,节点1更信任节点2和节点3,是因为节点2和节点3存在相互关系,节点1、节点2和节点3构成三角形结构,因此将边e12、边e13和边e14的权重设为相同的值是不合理的。因此在社交网络中考虑涉及多个节点的高阶结构是非常重要的。
在本文中,我们提出了一种基于Motif的LeaderRank (Motif-based LeaderRank, MLR)算法,我们捕获网络中Motif的高阶关系,并将该高阶关系合并到LeaderRank算法中,用于社交网络用户影响力排序。文献 [7] 提到,由于在社交网络方面,许多工作着重于分析三重闭合作为社交网络的重要结构特征以及分析三元配置作为各种社交网络理论的基础,因此,在本文中,我们主要考虑社交网络的三角关系,在本文中我们主要考虑基于社交网络三角关系的3-节点简单Motif。图2显示了一些典型的基于社交网络三角关系的3-节点简单Motif,其中M6表示图1中节点1、节点2和节点3的3-节点简单Motif。我们在美国社交网络及微博客服务数据集Twitter上进行实验,来提取有影响力用户,我们使用基线算法度中心性方法IND,原始LeaderRank算法和加权LeaderRank算法,结果表明我们提出的MLR算法明显优于基线算法度中心性方法IND,原始LeaderRank算法和加权LeaderRank算法。在这项工作中,我们采用线性关系来对基于社交网络三角关系的3-节点简单Motif的高阶关系和基于边的直接关系进行组合,通过对参数的调节,表明了基于社交网络三角关系的3-节点简单Motif的高阶关系和基于边的直接关系在计算节点的权威性方面是相互补充的。
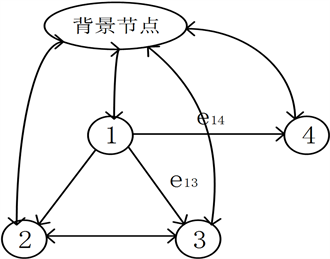
Figure 1. A schematic diagram of the LeaderRank algorithm. The algorithm introduces a background node in the original network
图1. LeaderRank算法示意图。该算法在原网络中引入一个背景节点
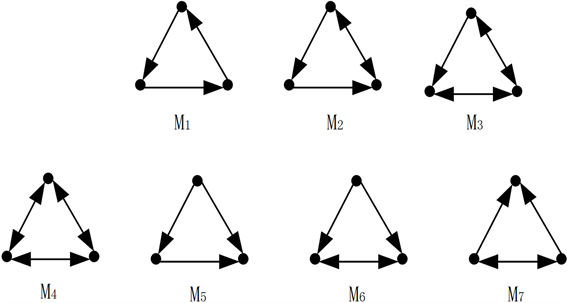
Figure 2. 3-Node simple Motif based on social network triangle relationship in directed unweighted graph
图2. 有向无权图中的基于社交网络三角关系的3-节点简单Motif
2. 相关研究
在本节中,我们介绍在复杂网络上使用LeaderRank和Motif进行计算的相关工作。
2.1. LeaderRank算法
首次引入LeaderRank来对网络上的网页进行排序是Lv等 [6],该算法主要是参考PageRank算法的基本思想,并在PageRank算法的基础上来进行不断的改进,并且在N个节点里面加上背景节点这样就获取了N + 1的网络G (N + 1, M + 2N)。除了进行网页排名之外,LeaderRank还用于许多其他领域,例如引文网络分析和意见领袖挖掘。在引文网络方面,邓启平等 [8] 充分考虑到了引用、合作这样不同的选项,分析哪些人更有影响力,并且按照合作数量还有被引的情况进行分析,并对作者开展相应的排序活动。在意见领袖方面,徐郡明等 [9] 则是充分想到使用者彼此有比较大的想法区别,都会按照自身的感情进行分析问题,就以此进行研究,并对LeaderRank算法进行了完善,添上了情感这一项,经过相应的完善,该算法具有了比较强的抗干扰水平,并且更加精准。此外,Zhang等 [10] 则充分分析了多种不一样的算法,并且据此开展研究,将节点聚类,获取其中边的具体权值。Bakshy等 [11] 在具体的验证过程中对其中的一些Twitter数值进行比较,了解用户的影响力的用途。顾亦然等 [12] 则充分依照到LeaderRank算法,通过相似度分析彼此的用途,这样就能让具体的效果更好,并且通过相应的模型,让算法精准度更好。与我们的工作相比,所有先前的研究仅是在LeaderRank算法中仅仅考虑了边关系,而忽略了多个节点之间的高阶关系。
2.2. 复杂网络中Motif的识别问题
网络是一个由多个节点组成的集合,节点之间有一定的连接,而不同于规则网络和随机网络的一些网络被称为复杂网络。复杂网络具有许多统计特征,其中最重要的是小世界效应 [13] [14] 和无标度特性 [15] [16]。随着复杂网络研究的进一步深入,网络中Motif的识别问题越来越受到关注,Milo等 [17] 人首次对在复杂网络中识别网络Motif的问题进行系统的阐述,激发人们对网络Motif识别技术研究的极大兴趣,在社交网络 [18] [19],学术网络 [20],生物学 [21] 等方面应用广泛。此外,之前的大部分工作都集中在如何对子图计数,在文献 [22] 中,提出一种快速高效的并行算法对3-节点Motif和4-节点Motif进行计算。在文献 [23] 中,提出一种采样算法对4-节点Motif进行计算。在文献 [24] 中提出了一种向左向右摇摆的蹒跚随机游走算法,该算法通过使用随机协议对步行走访的节点附近的子图进行采样来实现其计算效率。Motif也被应用在图聚类或社区检测 [25] 方面。在文献 [20] 中,Wang等人提出通过衡量节点在网络中的参与程度来衡量其重要性。与这些先前的研究相比,我们结合了Motif来探索基于社交网络三角关系的3-节点简单Motif,然后将该高阶关系与基于边的直接关系进行结合通过LeaderRank来对社交网络用户影响力进行排序。
3. 基于Motif的LeaderRank算法
3.1. 问题描述
社交网络中的社区由网络中一定数量的节点组成,令社交网络
,其中
是节点集合,
是边的集合,
表示从
到
的一条边。W'是邻接矩阵,
代表
的权重。G是由
多个社区构成,如图3所示,利用社区发现算法划分社区,对某一社区进行社交网络用户影响力排序。令社区
,其中
是节点集合,
是边的集合,eij表示从vi到vj的一条边。W是邻接矩阵,Wij代表eij的权重。除背景节点外的有向无权图,如果eij存在则
否则
。然后归一化邻接矩阵得到转移概率矩阵P,其中
。图上的LeaderRank可以定义如下。
(1)
其中
,并且xi表示当迭代达到稳定时的MLR值。达到稳定之后,将背景节点的MLR值平分给N个节点,最终的MLR值计算为
(2)
公式(2)中,
,N表示网络中除背景节点以外的所有节点的个数。
在一个社区G1,我们可以将该定义概括如下。如果存在从节点vi到vj的一条边eij,则我们用Wij表示vi对vj的认可强度或vj对vi施加的影响强度。这个权重可以基于交互频率,用户帖子的内容相似度等来计算,但是,以上所有权重仍然是两个用户之间的一阶关系的计算。如图1所示,对于用户1,W13应该大于W14,因为节点1和节点3参与了可信度评估中的三角关系。因此,理想的是,权重还可以包含关于这种高阶关系的信息。
3.2. Motif定义
定义1:网络Motif。一个Motif由元组(B, A)表示,其中
,B表示k × k二进制矩阵。
在文献 [25] 中给出锚节点代表我们感兴趣的节点。通常情况下,锚节点是所有k个节点,在这种情况下,我们称它为简单锚定,否则,我们称它为锚定Motif。在本文中,我们关注3-节点简单Motif,图4给出了一个3-节点简单Motif示例,说明Motif的定义。
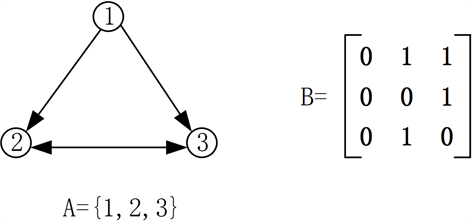
Figure 4. An example for a simple 3-nodes Motif
图4. 一个3-节点简单Motif示例
定义2:Motif集合。带有邻接矩阵W的有向无权图的Motif集合用
表示,定义为
(3)
其中δA是一个选择函数,为由A索引的k个元组的子集,而set(.)是一个将有序元组转换为无序元组的运算符
。v是表示k个节点的有序向量,Wv是有序向量v的k个节点在子图上引起的k × k个邻接矩阵。
我们用
表示图5的示例如下。
(4)
3.3. 基于Motif的邻接矩阵
当给定一个Motif集合F,我们使用F中两个节点的共现来捕获3-节点简单Motif的高阶关系,基于Motif的邻接矩阵或共现矩阵的定义如下:
(5)
其中
,l (s)是真值指标函数,即如果语句s为真,则l (s) = 1,否则为0。请注意,对于3-节点简单Motif,要求i和j是set(v)的成员。
基于Motif的邻接矩阵表示在给定Motif上的两个节点出现的频率。(WM)ij越大,表示在Motif上i和j之间的关系越明显。如图5所示,该图是由图二中的M1和M6的3-节点简单Motif构成,当我们以M6的3-节点简单Motif来计算邻接矩阵时,构成M6的3-节点简单Motif的边权值WMij = 1,其他WMij = 0。注意,边e12既属于节点1、节点2和节点5构成的M6的3-节点简单Motif又属于节点1、节点2和节点3构成的M6的3-节点简单Motif,因此边e12的权值为WM12 = 2。
令W为G的邻接矩阵,U和B分别为G的单向链接和双向链接的邻接矩阵。这里,我们集中讨论W中的元素为1或0的非加权图。例如,在图5中,e23是双向边,而e13是单向边。那么我们有
和
,其中
表示逐项乘积。注意,B是一个二进制矩阵,表示有向图中两个节点之间存在双向边。
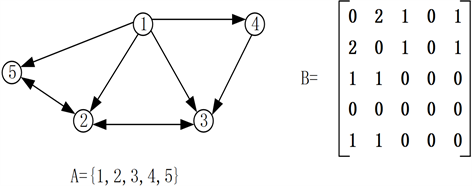
Figure 5. An example for computing M6 based adjacency matrix
图5. 基于M6的邻接矩阵示例
我们使用一个示例来说明M6的计算过程。如图4所示,三个用户vi,vk,vj有六种不同的情况{(3,1,2), (2,1,3), (1,2,3), (3,2,1), (1,3,2), (2,3,1)},e23是双向边,而e12和e13是单向边。为了计算M6参与下的vi和vj的频率,我们需要将在六种情况下的所有频率相加,在(1,2,3)中,vi为节点1,vj为节点3,频率由
所得,其中
计算的是不包括边e13的路径1-2-3,
表示用边e13补充图。因此M6邻接矩阵的计算为
(6)
3.4. 基于M6邻接矩阵的案例
1) 社区发现算法
这里使用文献 [26] 中所提到的基于随机游走方法来计算节点属性相似性、节点影响力,评估节点对社区重要程度,使节点向社区核心靠拢来划分社区。
第一步:子空间构造。发现子属性空间,构建属性增强图。
将属性转化为网络中的虚拟节点来构造属性增强图,在网络G中,节点与其对应的虚拟节点间建立一条双向边,如图6所示:
构造属性信息矩阵
来描述虚拟节点对原节点关系的影响,构造增量邻接矩阵
来描述加入虚拟节点后新的网络拓扑结构。通过属性影响度Affect(Ai)来反映将属性信息转化为拓扑结构信息后,原节点间的联系受到多大的影响,计算公式为
(7)
其中Ai为属性;βA为矩阵缩放因子,作用为更加明显的区分属性的结构影响度。
第二步:社区划分。计算转移概率,计算核心系数,确定聚类方向,创建初始社区及边缘修剪。
构造节点影响力strength来描述任意节点的邻接节点对该节点产生的影响,strengthij的计算公式为
(8)
其中
为节点
指向节点
的出链产生的影响力,
为节点
指向节点
的入链产生的影响力,
为属性关系产生的影响力。
(9)
(10)
(11)
其中βout、βin和βAttr分别表示出链系数、入链系数和属性系数,用于控制函数的收敛速度,D'为子属性空间包含的属性数目。
利用影响力矩阵,得到转移概率矩阵
,
。
(12)
引入节点核心系数
。节点的转移概率和节点的核心系数共同作用于节点的聚类方向
。取其中系数最大的作为聚类方向,得到初始社区,进行边缘修剪工作,输出社区序列。
2) 基于Motif的邻接矩阵
我们构建社区G1(16,17)的网络拓扑结构,如图7所示。
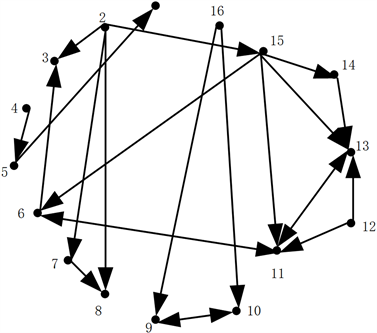
Figure 7. Community G1 (16,17) subgraph structure diagram
图7. 社区G1 (16,17)子图结构示意图
我们对图7识别3-节点简单Motif M6,首先我们构建一阶矩阵W,如图8所示。

Figure 8. Community G1 (16,17) first-order matrix W
图8. 社区G1 (16,17)一阶矩阵W
之后依据算法1得出基于M6的邻接矩阵。
算法1:基于M6的邻接矩阵算法


由算法1可得如图9所示的基于
的邻接矩阵。

Figure 9. Community G1 (16,17) based on the M6 adjacency matrix
图9. 社区G1 (16,17)基于M6邻接阶矩阵
由图7的案例,基于边的关系所得的邻接矩阵为W,仅考虑两个节点i和j,若存在eij即节点i指向节点j,则
,否则
。但由图7可观察到节点11与节点13所连成的边e1113的权重要明显大于其他边的权重,节点11与节点15所形成的e1115边权重也明显大于其他边的权重,主要原因为节点11与节点13所连成的边e1113既属于由节点11、节点13和节点15所围成的三角关系,也属于由节点11、节点12和节点13所围成的三角关系,因此,我们引入基于Motif的高阶关系来计算基于Motif的邻接矩阵,来对节点11与节点13所连成的边e1113的权重和节点11与节点15所形成的e1115边权重重新赋值,提高社交网络用户影响力排序的准确性。
3.5. 线性合并后的LeaderRank
在计算出基于Motif的邻接矩阵之后,我们将它们合并到用于对用户影响力排序的排序模型中。由于基于Motif的邻接矩阵中的非零元素将不超过原来基于边的邻接矩阵中的非零元素,因此我们将基于社交网络三角关系的3-节点简单Motif的高阶关系与基于边的关系结合,替代原来的基于边的关系。这样,基于Motif的边可以视为对使用LeaderRank进行计算的补充。我们使用线性组合来融合基于边和基于Motif的邻接矩阵。具体来说,对于给定的Motif Mk,我们生成如下的新矩阵。
(13)
其中
平衡了原来的基于边的关系和由Motif提供的3-节点简单Motif的高阶关系,
(14)
之后我们可以利用公式(14)计算转移概率矩阵
并将其代入公式(1)中的转移概率矩阵P,计算迭代稳定时的MLR值,迭代稳定后利用公式(2)得到节点的最终MLR值。
算法2:基于Motif的LeaderRank (MLR)算法。

4. 实验
4.1. 实验数据集
我们选用美国社交网络及微博客服务数据集Twitter,依据关注关系,选取2000个节点,57,544条组成,在构建社交网络时,当用户vi信任用户vj时,将添加边eij,网络数据是从 http://law.di.unimi.it/webdata/twitter-2010/上面下载的。
4.2. 实验环境
我们的实验环境为在Windows10操作系统上进行操作,使用python 2.7.16,numpy 1.11.2,Networkx 1.11的开发环境进行实验。
4.3. 评价指标
为了评估所提出MLR算法的可行性与准确性,我们比较了按不同算法排序的前K个用户的质量。具体来说,我们提取具有最大LeaderRank值的K个用户,然后计算归一化折损累积增益(NDCG),这个指标通常用来衡量和评价搜索结果算法。
NDCG计算公式表示为
(15)
其中
(16)
(17)
其中reli代表给定查询的文档相关性得分,|REL|表示文档按照相关性从大到小排序,取前N个文档组成的集合,
表示如果将较高的相关项放在较低的位置,则使用
来惩罚该算法,IDCG@N指的是理想情况下,根据相关性得分对结果进行排序。
基线算法。在对社交网络进行社区划分时,节点的转移概率和节点的核心系数共同作用于节点聚类方向,主要是考虑节点的度中心性,因此选用基线算法度中心方法IND,它根据度中心性来选择有影响力的节点,BLR方法是原始的LeaderRank算法。WLR方法是在加权网络中运行LeaderRank,其中从i到j的边的权重设置为i引用j或i信任j的频率。
对于MLR,我们分别处理M1~M7这七种情况下的3-节点简单Motif,然后分别显示每个3-节点简单Motif的结果。为了进行准确性比较,我们展示了在不同α值中可以获得的每个Motif的最佳结果,并展示参数α如何影响MLR的准确性。
4.4. 实验结果分析
1) 可行性与准确性分析
对Twitter数据集分别使用基线算法IND、BLR、WLR和我们的MLR算法计算top10、top50和top200的NDCG值,如表1所示。

Table 1. NDCG for top10, top50, top200 users from Twitter
表1. Twitter数据集top10、top50、top200的NDCG值
总体结果如表1所示。我们显示了使用不同算法得出的top10,top50,top200排序结果的NDCG值。从表1中,我们可以看到,通过我们提出的MLR算法,具有不同K值的三个数据集它的NDCG值都显示出很高的准确性,展现了将3-节点简单Motif的高阶关系合并到LeaderRank算法中的可行性。
由表1可以得出3个观察结果。第一,在Twitter数据集上,我们可以看到,K越大,NDCG值越小,这意味着更多的用户获得理想排序列表的难度更大。第二,我们可以看到在Twitter上的BLR和WLR在K = 10时NDCG大于0.96,K = 50时NDCG大于0.94,K = 200时,NDCG大于0.92,而我们提出的MLR可以将NDCG在K = 10时从0.9637提升到0.9875,在K = 50时从0.9434提升到0.9649,在K = 200时0.9256提升到0.9479。第三,我们发现BLR和WLR的NDCG值相似,这意味着使用频率作为权重并不会带来太多额外的好处。
从表可知,将基于社交网络三角关系的3-节点简单Motif的高阶关系与基于边的直接关系线性组合到LeaderRank可以提高社交网络用户影响力排序的准确性。
2) α值分析
Table 2. NDCG values of M1~M7 in Twitter dataset top10, top50, top200
表2. M1~M7在Twitter数据集top10、top50、top200的NDCG值
在公式(8)中,我们用参数α来控制基于边的直接关系和基于社交网络三角关系的3-节点简单Motif的高阶关系之间的平衡。当α = 0时,它仅使用高阶关系进行计算。当α = 1时,这意味着我们仅将基于边的直接关系进行计算。在本节中,我们将说明此参数如何影响NDCG的准确性。
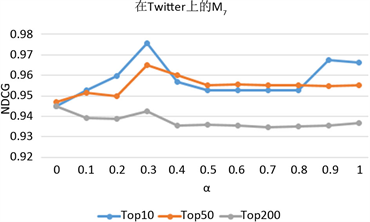
为简单起见,我们分别从表2中取K = 10,K = 50和K = 200NDCG值最大时所指向的3-节点简单Motif,即K = 10时使用M6进行实验,K = 50时使用M7进行实验和K = 200时使用M3进行实验我们可以看到,在大多数情况下,趋势是一致的,并且在[0, 1]中的某个值上可以获得最佳准确度。这意味着通过融合基于边的直接关系和基于社交网络三角关系的3-节点简单Motif的高阶关系,NDCG准确性会更高。Twitter上M7的K = 200排序结果和M3上的K = 50和K = 200排序结果的最佳准确性是在α = 0时实现的,即仅使用基于社交网络三角关系的3-节点简单Motif的高阶关系。这再次表明,基于社交网络三角关系的3-节点简单Motif的高阶关系可以为社交网络用户影响力排序提供有用的信息。
由图10所示的M6、M7和M3在K = 50和K = 200排序结果曲线趋势相似,而top10则更加多样化,这可能是因为社交网络中的前十名用户非常突出,并且行为可能与其他用户不同。在与BLR和WLR进行对比,可以计算得到Twitter上M6在top10方面效果提高了2%,在top50方面效果提高了1.7%,top200方面效果提高了1.3%;Twitter上M7在top10方面效果提高了0.8%,在top50方面效果提高了2.2%,top200方面效果提高了1.8%;Twitter上M3在top10方面效果提高了1.5%,在top50方面效果提高了1.7%,top200方面效果提高了2.4%。由此表明,将基于社交网络三角关系的3-节点简单Motif的高阶关系与基于边的直接关系线性组合到LeaderRank可以提高社交网络用户影响力排序的准确性。
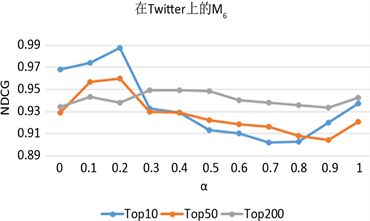
 (a)
(a) 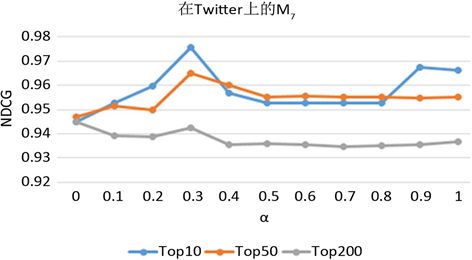 (b)
(b) 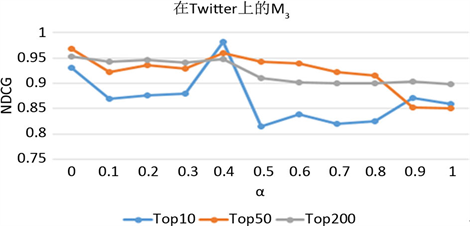 (c)
(c)
Figure 10. Parameter analysis of α on the three datasets. (a) Running alpha parameter analysis of M6 on Twitter; (b) Running alpha parameter analysis of M7 on Twitter; (c) Running alpha parameter analysis of M3 on Twitter
图10. 在Twitter数据集上α参数分析。(a) 在Twitter上运行M6的α参数分析;(b) 在Twitter上运行M7的α参数分析;(c) 在Twitter上运行M3的α参数分析
3) 案例分析
为了显示MLR算法的准确性,我们从社区序列里提取另一个社区,提取前10个用户并计算其NDCG值的平均值。结果如表3所示,在基于M1~M7的网络Motif上运行MLR算法,所得到的前10名用户的NDCG值的平均值。
Table 3. The average of the NDCG values of the top 10 users
表3. 前10名用户NDCG值的平均值
从表3中可以看出,在Twitter上,MLR的NDCG值的平均得分大于BLR的NDCG值的平均得分,这意味着MLR可以将最相关的结果排在前面,可以选择更有影响力的作者或可信赖的用户。这展现了基于社交网络三角关系的3-节点简单Motif的高阶关系合并到LeaderRank算法中的准确性。因此,它表明MLR可以更合理对有影响力的用户进行排序,再次显示了在社交网络用户影响力排序时将基于社交网络三角关系的3-节点简单Motif的高阶关系合并到LeaderRank算法中的优势。
5. 结束语
在本文中,我们提出MLR算法,将基于社交网络三角关系的3-节点简单Motif的高阶关系与基于边的关系相结合代入到LeaderRank中进行计算。使用基于Motif的邻接矩阵来重新权衡社交网络中边的链接。然后,将基于社交网络三角关系的3-节点简单Motif的高阶关系和基于边的关系组合在一起来执行LeaderRank。我们在Twitter数据集上进行实验,通过归一化折损累积增益(NDCG),表明基于社交网络三角关系的3-节点简单Motif的高阶关系和基于边的关系组合在一起的LeaderRank算法不仅在社交网络用户影响力排序上的可行性,而且可以显著提高社交网络用户影响力排序的准确性。