1. 引言
气温是描述某一地区气候特征的一个主要因素,通过对气温进行预测,可以在极端天气来临前起到预警作用,并及时采取预防措施。传统的预测方法主要有多元线性回归法 [1]、自回归移动平均法 [2] 和灰色预测法 [3] 等,这些方法的预测结果比较趋于平均值,不仅难以应付海量的数据和天气的动态变化,而且用于预测的气象数据多为时间序列,传统预测方法没有将数据的时间相关性考虑在内,导致出现预测准确率低的问题,因此正逐渐被淘汰 [4]。目前,应用较广泛的是以支持向量机、人工神经网络等为代表的人工智能算法。如小波分析和非线性自回归(NVR)神经网络结合技术 [5]、多元时间序列局部支持向量回归方法 [6],这些研究都能考虑到气象要素的时序多元性,却没实现精细化的气温预测,只能对相对稳定的平均气温进行预测,限于研究的手段限制,最终得到的精度有限。
1998年,N.E. Huang提出了一种新的信号分析方法——经验模态分解(EMD) [7]。该方法在处理非平稳非线性的数据上具有很大的优势,一经提出后,就在不同的工程领域得到了迅速有效的应用,例如在海洋、大气、天体观测资料与地震记录分析、机械故障诊断 [8]、密频动力系统的阻尼识别以及大型土木工程结构的模态参数识别等方面。但是,如果数据出现模态混叠现象,该方法的性能会出现大幅度下降的情况,因此N.E. Huang为了改进EMD的不足,提出了EEMD方法 [9],用以解决EMD中的模态混叠问题,该方法在气候、工程等领域有较多的应用。
气温数据具有非平稳非线性、时间相关性的特征。为了提高气温预测的准确性,本文提出EEMD和ARIMA模型相结合的方法对气温数据进行预测。EEMD能对非平稳数据进行平稳化处理,并且能有效解决数据中存在的模态混叠问题,使其达到时间序列数据分析的要求,ARIMA时间序列分析又充分考虑到了气温数据的时间相关性,将两种方法结合起来对气温数据进行处理及预测,将会有效提高预测的准确性。
2. EEMD基本原理
1998年N.E. Huang [7] 提出了EMD方法分析非线性、非平稳序列,此方法的基本思想是把一个频率不规则的波转化为多个单一频率的波(本征模态函数IMF)和残波的形式。但有时EMD会出现不同程度的模态混叠现象,为了解决这个现象,WU等 [9] 提出了集合经验模态分解方法(EEMD)。EEMD是一种基于EMD,用噪声进行辅助的数据分析方法,EEMD的核心思想是将白噪声加入原始信号中进行多次分解,把分解多次的本征模态函数(IMF)和趋势项取均值,该值为最终的IMF分量和rs余项。利用EEMD分解原始信号的具体步骤如下:
1) 添加白噪声的次数(即试验总次数)
和幅值系数
。
2) 将白噪声加入原始信号
中,
是第i次加入的白噪声序列,可得到信号
:
(1)
3) 找出要分解的时间序列
所有的局部最大值点和最小值点,利用三次样条函数的方法拟合
所有的最大值点和最小值点,构成上包络线和下包络线。
4)
为上下包络线的平均值。将信号
与
相减,得到新序列:
(2)
5) 判断
是否满足IMF分量的条件,如果满足,则
是筛选出的第一个IMF分量为
;如果不满足,
将作为新的原始序列重新回到步骤(3)和步骤(4)继续进行筛选,直到满足IMF分量的条件。
6) 把
从信号
中减去得到
,如式(3)所示。把
作为要分解的新信号,重复步骤(3)至步骤(6) n次,直到
或者
小于给定的数值或
为单调函数,即可结束分解。
(3)
7) 用SD (限值标准差)判断筛选是否终止。当SD小于阈值
时,筛选结束。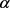 的一般取值范围是0.2~0.3。
经步骤(3)至步骤(7)处理后即可得到不同尺度的IMF和余项。
的一般取值范围是0.2~0.3。
经步骤(3)至步骤(7)处理后即可得到不同尺度的IMF和余项。
(4)
8) 利用白噪声频谱的均值为零,将
次分解得到的各IMF进行均值处理,得到EEMD分解后最终的IMF分量
和趋势项
:
(5)
(6)
9) 最后
的分解结果为:
(7)
3. EEMD-ARIMA预测模型基本原理
3.1. ARIMA模型
ARIMA(p, d, q)是最常用的时间序列模型 [10] [11],其中AR是自回归过程,参数p是其自回归项项数;MA是移动平均过程,参数q是其移动平均项数;参数d是使研究对象的时间序列达到平稳状态的差分次数。ARIMA(p, d, q)模型结构为:
(8)
式中,
,为平稳可逆ARMA(p, q)模型的自回归系数多项式;
,为平稳可逆ARMA(p, q)模型的移动平滑系数多项式。ARIMA(p, d, q)模型可
简记为:
,式中
为零均值白噪声序列。
3.2. EEMD-ARIMA模型
气温是一个非平稳序列,所以在预测之前要先对序列进行平稳化处理。因此,本文建立基于EEMD分解的EEMD-ARIMA预测模型。模型的建模流程如图1所示。
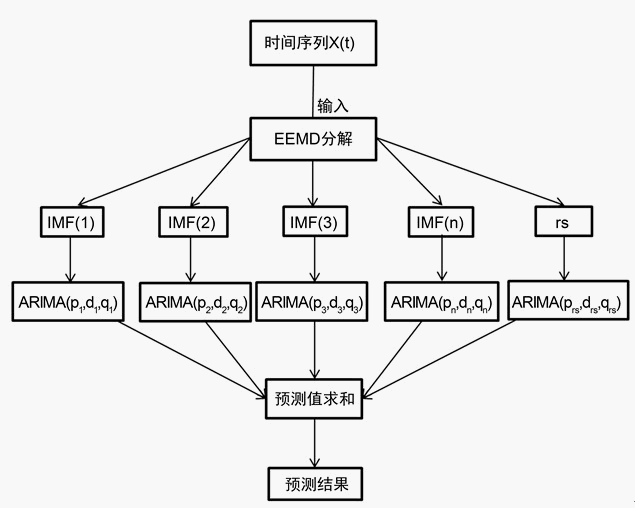
Figure 1. Flow chart of EEMD-ARIMA prediction model
图1. EEMD-ARIMA预测模型流程图
EEMD-ARIMA预测模型的具体步骤如下:
1) 首先,将原始信号
输入EEMD中进行分解,
会被分解成若干个IMF和余项rs。
2) 其次,因为通过EEMD分解得到的若干个IMF和rs之间相互独立,所以,对每一个IMF和rs进行ARIMA建模,并求出相应的预测值。
3) 最后,将所求得的每个分量的预测值相加,其和为最终的气温预测数据。
4. 模型应用
本节利用EEMD-ARIMA模型对沈阳市年平均气温数据建模分析。采用1951至2013年的年平均气温数据作为训练样本,并用2014年至2018年的年均气温作为测试集。将EEMD-ARIMA的结果与EMD-ARIMA和ARIMA的结果对比分析。
4.1. EMD与EEMD去噪效果分析
用EMD和EEMD分别对沈阳1951至2013年的年平均气温数据进行处理。对原始信号进行EMD处理后得到4个IMF分量和1个残余分量,如图2所示。在图2中,分量IMF1代表着信号高频成分,含有的噪声成分最多;分量IMF2和分量IMF3尺度区分不明显,存在模态混叠现象。
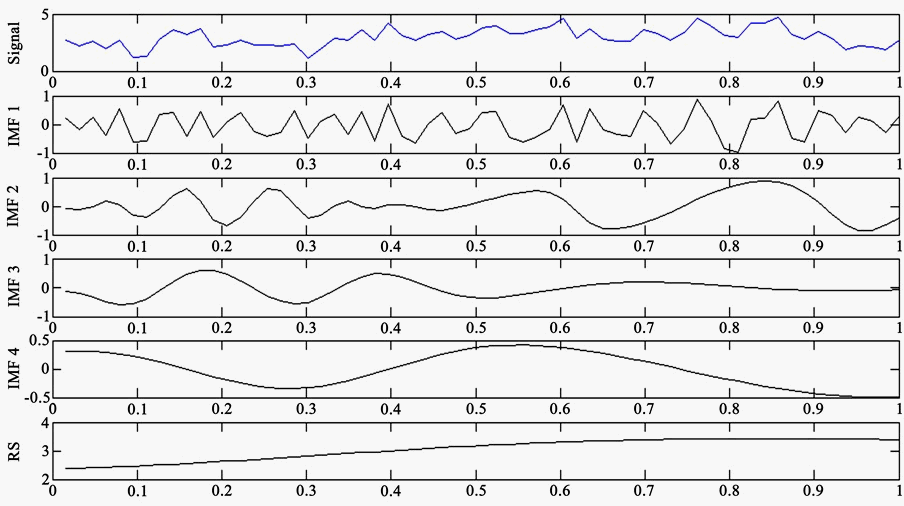
Figure 2. EMD component of annual average temperature in Shenyang
图2. 沈阳年平均气温 EMD 分解分量
对原始信号进行EEMD处理,其中EEMD加入了一个20dB的白噪声且总体白噪声集成次数为25次。处理后得到4个IMF分量和1个残余分量,如图3所示。其中IMF1为信号高频成分,频率沿时间
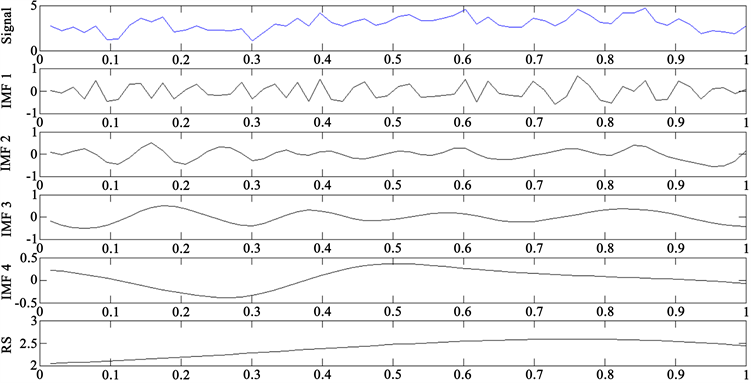
Figure 3. EEMD component of annual average temperature in Shenyang
图3. 沈阳年平均气温 EEMD 分解分量
轴基本不发生较大的变化,且幅值很小,可以视为信号噪声。各个IMF分量具有不同的时间尺度且时间尺度区分较为明显,说明EEMD在一定程度上解决了EMD存在的模态混叠问题。其中IMF1和IMF2不具有规律性,为随机分量,IMF3和IMF4为周期分量,rs为趋势分量。为了查看EEMD分解原始信号的完备性水平,对沈阳年平均气温和用EEMD分解得到的IMF分量与rs (残余分量)进行逐步拟合,得到不同平滑程度的重构序列,如图4所示。随着依次添加IMF分量,重构序列与原始信号越来越接近,直至最后与原始信号差不多完全拟合,说明EEMD分解该原始信号的完备性很好。
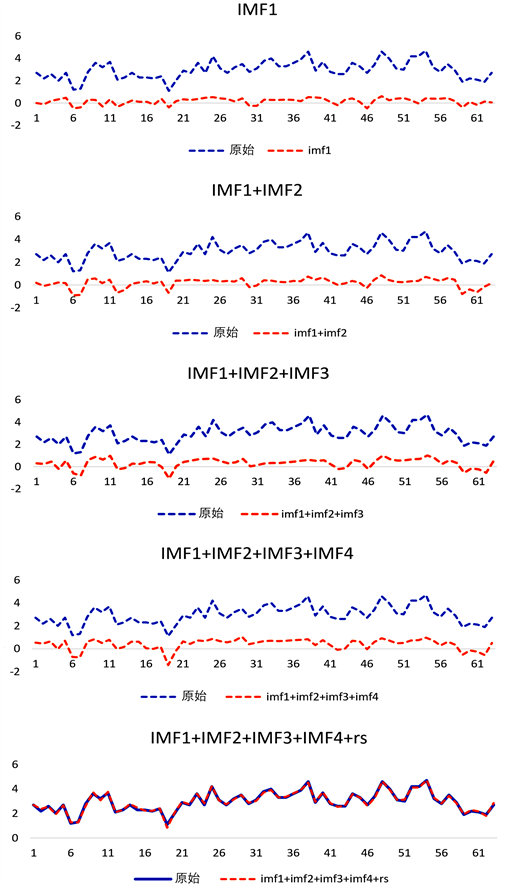
Figure 4. Sequence reconstruction of EEMD decomposition components
图4. EEMD分解分量的序列重构
利用均方误差(MSE)对EMD和EEMD的去噪结果进行量化评价。均方误差是反映估计量与被估计量之间差异程度的一种度量,所以MSE越小,表示估计量的可靠性越大,去噪效果会更好。其定义式如式(9)所示:
(9)
式中:
为原始时间序列,
为去噪后的时间序列。
计算MSE得出的结果如表1所示。EEMD的均方误差更小,其去噪效果优于EMD。

Table 1. MSE calculation value
表1. 均方误差(MSE)计算值
4.2. 年均气温预测结果及分析
如上,用EMD、EEMD对原始信号进行分解,得到两组不同的IMF,对两组中不同的IMF选择合适的ARIMA模型建模预测。EMD-ARIMA模型、EEMD-ARIMA模型和ARIMA模型的预测结果如图5所示,可以看出,EEMD-ARIMA预测模型的预测结果最接近原始值。
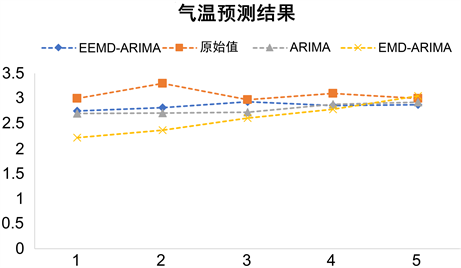
Figure 5. Temperature prediction chart of three models
图5. 三种模型的气温预测图
利用平均绝对误差(MAE)评价三种模型的预测效果。平均绝对误差是所有单个观测值与算术平均值的偏差的绝对值的平均,其中MAE越小,说明预测值与原始值的偏差越小,预测模型的准确性越高。MAE的定义式如式(10)所示:
(10)
式中
为原始值,
为预测值。
三种模型MAE的计算结果如表2所示。从表2中可以看出EEMD-ARIMA预测模型的MAE最小,其次是ARIMA模型,EMD-ARIMA预测模型的MAE最大,故EEMD-ARIMA预测模型的预测效果最好。
Table 2. Calculated value of mean absolute error (MAE)
表2. 平均绝对误差(MAE)计算值
5. 结论
气温时间序列数据具有非线性、非平稳的问题,故本文用EMD和EEMD对原始信号进行分解,对分量进行分析,然后对各分量分别建立ARIMA预测模型。通过比较EEMD-ARIMA预测模型、EMD-ARIMA预测模型和ARIMA模型的预测结果,发现针对沈阳地区的年均气温预测,EEMD-ARIMA模型预测结果均优于EMD-ARIMA模型和ARIMA模型。
基金项目
浙江省大学生科技创新活动计划暨新苗人才计划项目(2019R428014);宁波市自然科学基金(2018A610195)。