1. 引言
近年来,随着计算机处理技术的高速发展,互联网中的信息呈爆炸形式的发展,人们希望能够更精炼快速地捕获重要信息。句子压缩就是一种将冗长句子转换成精炼简洁句子的信息提炼方法。该项技术广泛地用于主题自动获取、摘要生成、问答系统等技术中,压缩后的句子需要保证原本句意不变,并且还需要一定程度上保证句子的可读性和语法上的逻辑性。
经典的句子压缩工作主要依赖于语法信息来进行判断,其主要思路是使用传统的句法信息,如基于选区的解析树(parse trees)的方法,通过使用语法树解析句子,以此进一步裁剪句子中的单词并重写句子 [1] [2] 。近年随着神经网络的发展,使用深度学习解决这个问题越来越受到人们的关注。Fillippova [3] 首次将循环神经网络 [4] [5] (Long Short-Term Memory)引入英文句子压缩中去,将句子压缩视为一种删除句子中单词的分类任务,相比传统方法有了较大的提升。神经网络模型是一种基于数据驱动的模型,拥有强大的特征提取能力,可以节约大量的人力物力,通过在大量的数据集上对模型进行训练,可以得到优于传统方法的效果。
尽管神经网络具有强大的特征提取能力,但网络端到端是不可控的。从句子压缩层面来看,在一些重要的名词或动词等被误删之后,往往会导致句意歪曲或压缩句阅读不通顺的问题。其次,由于不同领域下的常用词汇一般有较大的区别,在使用单一训练数据集得到的模型往往难以应对不同领域下得到的句子。对于不同风格和来源的句子,都需要使用到特定领域的训练数据集来进行训练才能达到理想效果,而数据集的获取是非常困难的,这一点极大地增加了应用难度。
针对以上问题,本文提出了一个既会使用句子中的单词信息,还会对词性信息进行获取的模型。通过提出一种带有语法注意力机制的长短期记忆网络,使用词性信息通过语法门控得到语法注意力,最终结合单词信息进行输出。使用词性序列来作为辅助序列是因为词性属于更为一般的信息,在句子中组成的单词不同的情况下,其所对应的词性序列往往有一定的相似性。使用词性序列进行辅助输出能够促进输出结果的语法正确性,进而保证可读性。本文的主要贡献如下:
1) 将句子的词性序列单独作为一条辅助序列,使用完整的词性序列并通过计算注意力机制来引导进行句子压缩。
2) 在模型中显式加入语法序列信息,使用语法注意力机制让输出的结果具有更强的可读性和鲁棒性,一定程度上也具有更好的跨领域应用能力。
3) 通过使用单词的语法信息,即使在词向量词典中找不到该词,也可以通过单词的词性信息一定程度上协助进行协助判断。一定程度上解决了词典非常见单词的OOV (out of vocabulary)问题。
2. 相关工作
传统的句子压缩方法主要基于语法解析树(Parse Tree)。例如,Cohn [6] 使用语法解析树来决定怎样重构句子,Filippova [7] 通过剪枝依赖树删除冗余词进而达到压缩句子的目的。而随着神经网络技术的发展,越来越多学者考虑使用神经网络来解决这个问题。Fillippova将编码器–解码器框架应用于删除式句子压缩任务,其核心组成是一个三层单向LSTM结构构成的编码解码模型,输出端使用Softmax作为激活函数来对每个单词进行二分类判断是否进行保留来组成压缩句,在大规模训练数据集上训练得到的效果相比较传统方法有较大的提升。后续Lai [8] 使用双向LSTM对句子双向信息进行捕捉,并在输出端使用条件随机场提高了效果;Tran [9] 。提出适应于句子压缩任务的注意力机制即t-attention模型,通过对编码器序列每个节点的输出引入到对应的解码器中去,有了显著的提升。紧接着鹿忠磊 [10] 等人通过尝试增大t-attention的捕获范围来扩大信息捕获范围。
上述工作的输入为句中单词的词向量,改进的主要思路为通过增强编解码器的特征捕获能力来提高模型效果。而从语言学的角度来看,语法相关信息是一个同为通用的信息,Wilks [11] 研究了通过对英文句子进行词性标注从而达到一定程度上消歧。而近期刘杰等 [12] 又通过对比发现使用循环神经网络能够更好判别出作文句间的逻辑性。Wang [13] 等人开始尝试将语法信息显性地引入句子压缩任务中,输入到网络的词向量中加入词性和单词之间的依赖信息,在跨领域数据上验证了通过显式地加入相关语法信息能够增强模型的效果和迁移能力。
3. 本文方法
3.1. 问题定义
删除式句子压缩,即通过在原本长度较长的句子上,使用删除句子中单词的方式得到较短的句子,通过去除冗余词并保留核心词的方式重新组成压缩句。假设输入的原句为:
(1)
表示组成句子的单词。通过删除原句中的一些单词并使用剩余单词共同组成新的句子。即希望得到这么一系列的标签
,其中
。其中标签0表示删除该单词,标签1表示保留该单词。示例如表1数据示例所示:
3.2. 基本模型
本文借鉴了Filippova所提出的3层LSTM结构,提出了LSTM-Res网络。同样使用3层的LSTM结构作为编码器和解码器,多层的网络结构可以在不同捕获不同映射维度下的语义信息。此外,受到残差网络 [14] 的启发,在本次实验中将第一层和第二层的网络捕获到的低维和高维的语义叠加作为第三层的LSTM的输入。通过结合第一层和第二层的输出结果,能够捕获得到更多层次的语义信息,从而更好地得到输出的结果。其网络结构如图1 LSTM-Res结构所示。
图中的三层网络其中LSTME代表编码器,LSTMD表示解码器,其下标数字表示所在层数。作为外部输入的
到
表示句子中的N个单词的词向量,将句子完整投入到编码器之后将隐含层信息投入到解码器中;使用
作为解码器解码输出的标志,再将原句中的单词投入到解码器中,即对于编码器和解码器而言,输入单词是保持一致的。此时每个单词对应的输出Y则为每个单词对应是否删除的标志。
3.3. 语法特征
句子压缩任务中,不同句子包含的单词往往不近相同,但却可能拥有相似的语法逻辑,因此通过加入单词的词性信息,能够协助更好地理解句意。对于词性特征,在本次论文实验中使用spacy来进行分词和词性捕获,主要将词性分为17种类型如表2词性符号表示。

Table 2. Symbol of property of word
表2. 词性符号表示
除了本身词性序列排序上上具有相似性,由于词向量 [15] 。所需占用空间巨大 [16] ,词向量的词典只会对常用高频词进行保留,对于词表中没有的词则会统一使用
进行标记。然而,特殊的人名地名等往往是句子中的重要组成成分,统一使用
进行替代会损失大量的词义信息。通过使用词性信息能够一定程度缓解这种状况,具体示例如
表3数据标志所示。
通过上述示例可以观察到,当句子中出现特殊的人名地名或动作时会被判定为
字符,此时通过额外补充的词性序列在一定程度上也可以更好地为句子压缩提供方向。如上例中的人名Serge Ibaka和形容词Spanish都使用
标志,但通过加入了专有名词
和形容词
作为标记;而一些动作如例子中的has been granted则被记为动词
。对于大多数陈述性的句子而言,其核心组成部分往往需要包括一个主语和一个谓语,而对于本次使用的新闻数据集而言主语往往是人或物,谓语则是动作,通过这样显性地添加词性信息到网络中,能够一定程度上正确地引导输出结果。
通过结合词性信息的网络整体处理框架如图2编码器解码器基本结构所示:

Figure 2. Encoder and decoder basic structure
图2. 编码器解码器基本结构
先对原句子进行预处理,包括分词以及对词性信息进行捕获等。得到句子中的词向量和词性向量。将词向量和词性向量输入到网络中,网络通过结合词性序列和词向量序列最终得到压缩后的句子。
3.4. 语法注意力机制
为了更好地将语法特征融入网络,本文提出一种带有语法注意力机制的长短期记忆网络(Syntax-LSTM),使用句子的语法信息控制门控信号,得到语法注意力来引导最终的输出判断。网络整体框架如图3带有语法注意力机制的编码解码结构所示:
输入到网络中的单词序列和词性序列分别使用两个独立的编码器和解码器进行编解码。编码解码器的结构主要基于上文提出的LSTM-Res。对于单词序列,使用循环神经网络结构来进行信息捕获;同样地,词性信息也是使用循环神经网络来构建序列上的关联。词性序列相比单词序列,排列上更具有规则性,通过捕捉序列上的排序规律,使用循环神经网络结构能够更好地捕获词性信息,从而对最终输出进行引导。本文通过一种带有语法门控的LSTM (Syntax-LSTM)结构作为单词序列的解码器,使用这个语法门控来生成语法注意力机制,进而对最终的输出结果进行限制。改进之后的解码器部分的结构如图4编码解码结构:
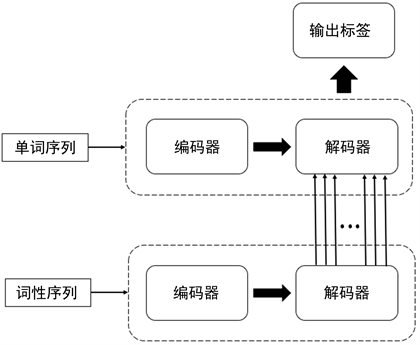
Figure 3. Encoding and decoding structure with syntax attention mechanism
图3. 带有语法注意力机制的编码解码结构
为句子中第i时刻单词对应的词性,投入到解码器之后得到输出词性信息
。再将词性信息
作为引导信息和第i时刻的单词
一并投入到Syntax-LSTM,输出对应标签
。
对于Syntax-LSTM,在原本的LSTM结构中增加一个额外结合语法信息的语法门控,并且由词性解码器的输出进行控制。具体结构如图5 Syntax-LSTM内部结构所示:

Figure 5. Internal structure of Syntax-LSTM
图5. Syntax-LSTM内部结构
Syntax-LSTM的工作原理如下:
(2)
(3)
(4)
(5)
(6)
(7)
(8)
(9)
其中
表示当前节点的输出信息
和
分别表示从上一节点传递过来的细胞状态(cell state),和隐含状态(hidden state)。
表示遗忘门(forget gate),控制从上一时刻传递过来状态是否进行丢弃;
表示输入门(input gate),控制当前时刻信息是否添加到隐含状态中;
表示输出门(output gate),控制选择作为当前节点输出的信息。此外,使用额外的信息
,即对应于文本中词性解码器的输出来对最终输出结果
进行控制,通过这种方式让最终的输出结果更符合语法逻辑。
4. 数据与实验
4.1. 数据与预处理
对于有监督训练尤其是深度学习模型而言,需要大量对应带标注语料数据。本文的训练数据集使用Filippova [17] 公开的4万条数据集,这批数据来自谷歌新闻(Google News)中收集到的“标题–新闻”句子对,进而通过参考标题对原句的依赖树进行剪枝,使用这种方式能够构建为原句子序列的压缩句,进而得到删除式句子压缩所需要的“原句–压缩句”平行语料。数据分为三部分:36,000条句子对组成训练集用于模型训练,2000条验证集用于训练过程中的交叉验证,2000多条测试集用于最终测试模型效果。
实验采用了开源的自然语言处理工具spacy对句子进行了分词等预处理工作。对于单词的词向量,采用了开源word2vec中的skip-gram训练方式基于本次数据集进行训练最终得到维度为97的词向量,使用预训练好的词向量能够一定程度上提高实验效果。由于词向量的训练依赖于词典,通过统计数据集选出词频最高的8000个词构成词典训练他们的词向量。
超出单词表的单词或字符均使用符号
作为标识,在句子开头加入
作为句子开始的标志。由于句子长短不一,本次实验中通过统计选取数据集句子长度,选择了120个单词的句长,即对于小于120词的句子,使用
进行补齐,而对于超出120个单词的句子,则对超出的单词直接进行截断丢弃。
此外,由于本次任务为删除式的句子压缩,因而需要使用原句子和压缩后的句子构造对应的标签,标签为0表示句子中的该单词应该被删除,而标签为1则表示单词应该被保留,而
和
部分则使用标签2进行区别表示。
4.2. 实验设置
本次实验中的词性编码解码器和单词编码解码器的输入维度和隐含层维度大小统一设置均为100。其中输入的词性向量和词向量均为97维度,而末尾的3个维度为标志位。在编码阶段,标志位不会进行标记均设为0;而在解码阶段,当前词的标志位由上一个词的标签输出结果决定,标签输出1、2、3则对应的标志位上的第1、2、3位置为1,其他位置为0。通过使用标志位的方式,能够将上一个节点的输出的结果传递给下一个节点,当前节点结合上一输出标签引导当前节点的输出。
根据本次数据集的特点对模型采用了如表4模型基本参数的设定方式。并且采用了提前停止的策略 [18] (early stop),当验证集的F1数值超过5轮不增加之后,停止训练。
4.3. 实验结果
本文对实验结果的评价指标主要通过F1分数、以及压缩率CR(Compression Rate)二者进行衡量。F1指标是一种综合召回率和精确率的指标。其表示方法如下:
(10)
上述公式中的 表示精确率, 表示召回率。压缩率是一种用来描述句子压缩前后单词占比的指标,其计算公式如下:
(11)
对于这一指标的目标是压缩率能够与原本句子中的基本保持一致,结合F1指标,CR能够一定程度说明压缩后的句子充分压缩了并且整体语义保留完整。
主要对比的网络主要包括Filippova提出的三层LSTM结构,一种使用双向LSTM更好捕获句子前后语义并进行解码的网络结构以及在神经机器翻译系统中提出来在双向LSTM的基础上加入注意力机制(Attention),一种针对于句子压缩任务特点提出来的T-Attention结构,也是目前的state-of-the-art。实验测试集结果如表5 Google News数据集上的表现所示。
Table 5. Performance on the dataset of Google News
表5. Google News 数据集上的表现
增加残差结构的LSTM-Res相比Filippova的三层LSTM结构F1数值上高出0.0129,并且是与当前达到state-of-the-art的Bi-LSTM-TA相当。而在通过加入语法信息,又在LSTM-Res又在原有的基础上有所提升,并且可以观察到压缩率CR和测试集的标准压缩率最为接近。对于同一来源的训练集的测试样本,加入语法门控的效果与当前state-of-the-art相当。
为了进一步比较模型的跨领域泛化能力,下面使用了与训练数据集不同来源且写作风格不同的NBC News数据集来做进一步的验证。
Table 6. Performance on the dataset of NBC News
表6. NBC News数据集上的表现
通过表6 NBC News数据集上的表现可以看到,在Google News的测试集中表现一般的3LSTM和Bi-LSTM在NBC News上表现良好,这一定程度上说明了简单的网络尽管对于单一数据上的拟合不够好,却能够在不同来源的数据集中变现出了良好的泛化能力。相比之下,原本表现良好的Bi-LSTM-tA在跨领域数据集中表现反而为最差。这反应了拟合能力强的模型往往在跨领域或者是在处理差别较大的数据时效果大打折扣。而本文提出的加入了语法信息的LSTM-Res-Syntax则通过捕捉句子中通用的语法信息,增强对于未见过句型的泛化能力。
5. 结论
本文提出一种融合语法信息的句子压缩方法。在该方法中,文本使用了词性序列来作为语法信息,然后提出了一种通过语法门来形成语法注意力的Syntax-LSTM,通过这一门控生成注意力,最终进行单词序列标签的判断。词性相比单词而言,是一种更为一般的信息,对于单词不同的句子其词性序列却有着一定的相似性,通过捕捉这类的相似结构,能够得到更好的输出并具有更强的泛化能力。最终实验取得了目前的state-of-the-art相当的分数,并在跨领域数据集NBC News上的性能均优于其他模型,证明了该方法具有更好的鲁棒性和可迁移性。下一步将对语法门控引入到文本摘要任务,尝试用删除式的方式做摘要的抽取。
基金项目
国家自然科学基金(61876043);广东省自然科学基金(2014A030306004,2014A030308008);广东特支计划(2015TQ01X140);广州市珠江科技新星(201610010101);广州市科技计划(201902010058);NSFC-广东联合基金(U1501254)。
参考文献