1. 引言
在钢材器件生产过程中,往往会在每个部件上标注不同的生产编号,这样不仅为了便于对部件的质量监控和信息管理追踪,还为了方便对部件与相应器件间的匹配问题进行把控。压印字符是利用字模对物体表面施压形成的,呈凹凸状,因其不能随意更改而可以永久保存的优点,在工业生产中得以广泛应用。钢材器件通常是大批量的生产,传统的人工手动记录生产编号的方法需消耗大量的劳动力,同时大大延长了生产时间,还容易出错。计算机视觉技术不断发展,应用于工业生产过程当中,极大地减少了工业生产对人工的依赖。现如今,随着工业智能化生产的发展要求不断提高,在工业生产中迫切需要对钢材器件上的压印字符标号进行视觉实时识别。
压印字符与手写字符、印刷字符等一般的光学字符有所不同,压印字符的颜色与背景色是一样的,因而这两者的对比度不鲜明,而且在复杂多变的工业生产环境下,会出现噪声、光照不均衡、抖动模糊、位置不确定等问题,这些问题又进一步增加了压印字符识别的难度。因此,传统的字符识别技术(如模板匹配 [1] )无法直接应用于钢材压印字符的识别中。可将钢材压印字符识别看成是具有一般性的目标检测任务。目标检测是计算机视觉 [2] 研究的热点问题之一,它学习每个对象的可视模型,并找到合适的边界框区域和对象类别。早期较常用的目标检测算法是DPM (Deformable Parts Model) [3],其通过HOG (Histograms of Oriented Gradients) [4] 特征提取,将提取到的图像特征作为输入,利用SVM (Support Vector Machine) [5] 进行分类。DPM在行人检测 [6] 等目标检测任务上有较好的效果。但实质上,这样的方法对于特征设计十分依赖于人工,过程也比较复杂繁琐。
近年来,随着深度卷积神经网络的兴起,目标检测的性能与以往基于手工的方法(如文献 [7] [8] )相比有了显著提高。最初利用神经网络进行目标检测的方法是基于候选区域的方法。Girshick等 [9] 提出的区域卷积神经网络(R-CNN)先从图像中采用选择性搜索算法 [10] 提取候选区域,再通过标准的卷积神经网络去调整以及分类这些区域。但是,对于每个候选区域都需要对整个网络进行重新计算,存在大量重复的计算,进一步增加了计算复杂度,从而降低了目标检测网络的速度。随后,Girshick [11] 提出了快速区域卷积神经网络(Fast R-CNN),直接从CNN的编码特征图中提取候选区域,使得网络可以共享计算结果,从而让模型提速,帧速率达到5 frame/s。然而,Fast R-CNN仍采用选择性搜索算法来提取候选区域,计算还是相当复杂。为解决这一问题,2015年Ren和Girshick [12] 提出超快区域卷积神经网络(Faster R-CNN),采用基于深度学习的区域建议网络(RPN)来提取目标候选区域。在RPN中,预定义的锚点(Anchor)和框(Anchor Box)预测目标感兴趣区域(RoI)。通过引入RPN,检测精度和速率都有所提高。尽管Faster R-CNN的计算速度有了很大提升,但是仍然无法满足实时检测的要求,因此在2016年Redmon等人 [13] 提出了YOLO (You Only Look Once)网络,将整幅待检测图像作为输入,而卷积神经网络作为回归器,回归目标在待检测图像中的位置信息,实现端到端的目标检测和识别。相比于基于候选区域的方法,YOLO算法不需要生成目标建议区域,而是将输入图像看成一个候选区域,简单地划分为几个小区域,然后通过CNN来判断每一个区域是否存在目标,并预测目标的种类和边界框,这大大节省了图像处理的时间,帧速率达到了45 frame/s。当然,YOLO在提升检测速度的同时精度有所降低。随后,2017年Redmon等人 [14] 基于YOLO网络进行一系列的改进提出了YOLOv2网络,其准确率和检测速度均得到了显著提高。从VOC 2007数据集的模型检测测试结果来看,YOLO v2的准确率为76.8%,检测速度可达到67 frame/s,满足了实时性,在目标检测领域表现出色。
本研究提出了一种基于YOLOv2网络的钢材压印字符识别方法,结合图像灰度化、滤波去噪、边缘检测、霍夫变换算法对工业生产线上钢材部件的生产标号图像进行预处理,处理之后的数据集通过YOLOv2网络训练,学习各类字符的特征,对字符进行分类的同时得到字符的位置信息,利用图像中各个字符所得的位置信息进行排序操作,即可得到钢材部件的生产标号,实现实时地、快速地、准确地一步式识别钢材部件的生产标号。
2. 识别方法
2.1. 图像预处理
2.1.1. 倾斜矫正
从工业相机获取的钢材压印字符原始图像如图1(a)所示。由于在压制压印字符过程中会出现偏差,或者在摄取压印字符图像过程中没有完全对准,难免会出现字符倾斜的问题,这就需要对字符进行倾斜校正。霍夫变换(Hough Transform)是图像处理中的一种检测特定形状的技术。它实质上是一种线-点变换,把图像空间转换到一个参数空间中,通过统计寻找累加的局部最大值得到一个符合该特定形状的集合作为霍夫变换结果。霍夫变换常用来检测图像中的直线,此外霍夫变换也可用于对曲线的识别,例如检测圆和椭圆。霍夫变换检测直线具有受直线中的间隙影响小和抗干扰性强的优点。其原理是:将图像中直线上的点(x, y)进行变换,利用过该点的直线在直角坐标中的表达式y = kx + b (其中k为斜率,b为截距)可变换成b = −kb + y,即把点(x, y)转换到k-b参数空间的一条直线,图像空间的直线上多个点的累加变为在参数空间上的多条直线相交于一点,在参数空间寻找这个最大点从而可以返回找到原始图像上的直线。根据钢材部件的矩形条状结构特点,可利用霍夫变换检测直线的算法获取图像中最长的线,然后计算该长线的倾斜角度 ,最后将图像旋转
即可。结果如图1(b)所示。
,最后将图像旋转
即可。结果如图1(b)所示。
另外,图像在实际成像、获取的过程中会出现字符倒置的情况,如图1(c)所示。为了统一数据集样本的基本形式,就需要对这些倒置的图像进行180˚的旋转处理,结果如图1(d)所示。
 (a) 原始图像 (b) 倾斜矫正 (c) 倒置原始图像 (d) 旋转矫正
(a) 原始图像 (b) 倾斜矫正 (c) 倒置原始图像 (d) 旋转矫正
Figure 1. Tilt correction picture
图1. 倾斜矫正图片
2.1.2. 图像增强
为了加强和突出钢材部件图像中压印字符特征,减少字符图像的噪声干扰,本研究首先对图像进行灰度化处理,然后利用中值滤波抑制噪声,同时字符的边缘细节还能保留下来。中值滤波 [15] 是一种非线性图像平滑方法,其输出像素由邻域像素的中间值决定。首先要选定一个奇数像素的窗口W,将窗口内各像素灰度值按从小到大进行排列
,选取排在灰度序列中间的灰度值y作为对应窗口中心位置的像素灰度值。具体的计算方式为
(1)
其中,n为像素值的数量,通常是奇数。但当n为偶数时,计算中间两个像素的平均值即为窗口中心位置的灰度值。通过中值滤波后图像的背景更加平滑,字符更突出,有助于在字符识别的过程中更好地提取出字符特征,从而达到较好的识别效果。图像增强的效果如图2所示。
 (a) 灰度化 (b) 中值滤波
(a) 灰度化 (b) 中值滤波
Figure 2. Image enhancement effect map
图2. 图像增强效果图
2.1.3. 数据集扩充
由于没有公开的钢材压印字符数据集,本研究从实际的工厂生产线上通过工业相机获取了1500幅钢材压印字符原始图像作为数据集样本。每幅钢材生产标号图像均包含了10个字符,由数字和大写字母组成,但经过统计发现字母的数量远远少于数字字符的数量。为了平衡网络训练的各类样本数量,对现有样本进行扩充,本研究采用泊松融合的方法对部分字母样本进行重新自由组合,产生新的样本。
泊松融合是由Perez等 [16] 提出的基于泊松方程的图像编辑算法,通过求解公式(2)极值问题,构造泊松方程从而求解像素最优值。
(2)
式中,
代表前景图像中需要融合的字符区域,
则为该区域的边界,V是在
上的梯度向量场。f代表字符融合后的图像,其梯度为
,而f*代表融合的字符区域以外的背景图像。在满足融合图像和背景图像的边界值相等的同时,求解融合图像的梯度与V引导下的梯度最小差值,从而达到比较自然的无缝融合效果。该问题可以转化成利用狄利克雷边界条件求解泊松方程,如式(3)所示。
(3)
式中,
为拉普拉斯算子,div为散度算子。本研究利用泊松融合方法最终得到2000幅字符图像,其中1600幅作为训练集,400幅作为测试集。
2.2. YOLOv2原理
2.2.1. YOLOv2网络结构
大部分目标检测框架常用准确率高的VGG-16 [17] 作为特征提取网络,但VGG-16网络结构复杂且计算量庞大。而YOLO采用类似GoogleNet [18] 的网络结构,相较于VGG-16而言,计算量减小,但准确率略低于VGG-16。为了兼顾复杂度与准确率以提升网络的检测性能,YOLOv2对YOLOv1进行了改进,采用了新的分类网络Darknet-19作为网络骨架来进行特征提取。Darknet-19网络包含了19个卷积层和5个最大值池化层,去除了YOLOv1中的全连接层,得到了更多的空间信息。网络在所有的卷积层后增加Batch Normalization (批量归一化)并移除网络的dropout,这可以显著改善网络的收敛性,并且有利于正则化模型,防止过拟合。
基于YOLOv2的钢材压印字符识别网络结构如图3所示。将归一化为
大小、通道数为3的图像作为输入,采用多个
卷积核,每经过一次池化操作都会将通道数翻倍。借鉴了network in network [19] 的思想,使用全局平均池化进行预测,将
卷积核置于
卷积核之间进行交替操作以压缩卷积间的特征表示。经过19个卷积层和5次池化后,图像转化为
的特征图,其中第13个卷积层输出的
特征图经过一层卷积和重组之后得到
的特征图,将其与
的特征图进行融合,最后再经过两层卷积得到最终的特征图。通过添加这样一个转移层(passthrough layer)把浅层特征图和深层特征图相连接,使得最终获得的特征图可以拥有更好的细粒度特征。
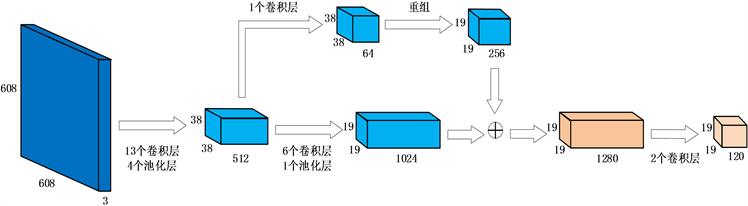
Figure 3. The network structure of YOLOv2
图3. YOLOv2的网络结构
2.2.2. 检测过程
YOLOv2在对钢材压印字符检测识别的过程中,会将整个输入图像划分成
的网格,每个网格负责检测中心点落在网格中的对象。同时,YOLOv2网络借鉴Faster R-CNN的思想,引入Anchor Boxes先验框,不同于Fast R-CNN需要人工定义Anchor Boxes,YOLOv2采用K-means聚类方法对数据集中的人工标记框进行聚类分析,确定Anchor boxes的数量和大小,最后在网格的周围生成几个一定比例的边框。那么,每个网格单元预测B个边界框和这些框的置信度分数,每个边界框包含了该区域中心点的位置(x, y),高度h,宽度w和置信度confidence这5个信息。
置信度表征边界框中是否含有检测对象以及边框预测的准确程度,其计算公式为
(4)
式中,P(object)表示边界框中有无包含检测对象,若有取值为1,则置信度confidence等于
的值,若边界框中没有包含检测对象,P(object)取值为0,则置信度confidence的值也为0。而
表示预测边界框与标记的真实边界框的重合程度,其计算方式为
(5)
即预测边界框与真实边界框所占面积的交集比上两者的并集(Intersection over Union),该值越接近于1,表明两者的重合度越高。那么,预测边框某一类别的置信分数Confi就可以通过式(6)进行计算。
(6)
置信分数表征预测边界框中含有某一类别的概率及边框坐标的准确度。综上,当存在C类别时,网络的输出尺寸为
的张量。根据置信分数的大小,采用非极大值抑制(NMS)筛选获得最终的检测结果。
2.2.3. 输出改进
在检测结果输出时,为了能使检测到的字符按生产标号顺序输出,本研究利用检测到的字符位置信息通过冒泡排序按从小到大进行排序,相应的字符从左到右排列,从而得到准确的生产标号。利用字符位置信息进行冒泡排序的方式比较简单,依次比较存放字符位置信息的数组中相邻两个数的大小,若排在第i位的数比排在第i + 1位的数要大,则两者进行交换,否则不需要交换。同时位置信息对应的字符数组也进行相同的操作,最终得到位置信息从小到大的序列和按生产标号从左到右的字符序列。
3. 实验结果及分析
3.1. 实验平台
本实验是在PC端上完成,PC配置为CPU Intel Core i7-6700,显卡/GPU为NVIDIA GeForce GTX 960M,8G运行内存,训练和测试框架均为Darknet。
关于网络参数的设置方面,将初始学习率(learning_rate)设为0.001,采用steps学习率调整策略(policy);每迭代一次训练的样本数(batch)为64,最大迭代次数(max_batches)为10000次;学习率在迭代次数为4000,6000时,在原来的基础上再分别乘以0.1,0.1;动量(momentum)为0.9,衰减系数(decay)为0.0005。
3.2. 训练
对YOLOv2网络的训练是钢材压印字符识别的关键一环,训练所得模型的好坏直接影响字符识别的效果。本实验利用LabelImg软件对训练集中所有图片上的字符打上各自相应的标签,生成每一幅图片对应的.xml文件,然后将每一个.xml文件生成txt文件,存储标签信息。最后利用设置好参数的YOLOv2网络对训练集样本进行训练。
YOLOv2网络在训练时可以通过计算损失函数Loss来判断训练的效果,计算方法在等式(7)中示出。
(7)
其中,
表示目标对象是否出现在网格单元i中,
表示网格单元i中的第j个目标边界框。相反地,
表示网格单元i中的第j个边界框,其不包含目标对象的任何部分;
为目标坐标预测的损失系数,
则为不包含有目标的边框预测的损失系数;
、
、
、
、
、
为网格i中预测目标的中心点坐标、宽高、类别及概率,
、
、
、
、
、
则为网格i中目标的各相应信息的真实值。公式(7)的时间复杂度是
,其是针对一个图像计算的。要得到较好的训练效果,则期望Loss值尽可能小。
YOLOv2网络在训练过程中还采用了多尺度训练策略,每隔十轮便改变一次图像尺寸进行输入,以提高模型对不同分辨率图像的鲁棒性。使用YOLO v2网络在钢材压印字符训练集训练中随着迭代次数的增加平均损失率所产生的变化如图4所示,从图中可以看出网络收敛速度较快,在迭代2000次左右时基本收敛,之后处于基本稳定状态,并且Loss值越来越接近于0,说明训练的效果逐渐趋于最佳。
3.3. 测试结果及分析
本研究还将整幅钢材生产标号图像分割成单个字符图像作为样本集,分别采用LeNet-5 [20] 和SVM来对样本集进行训练和分类识别,对比两者与本研究采用的YOLOv2方法的识别效果。采用准确率(Accuracy, Acc)、假阳性率(False Positive Rate, FPR)、召回率(Recall)、检测单幅图像耗时(Time)等评估参数作为评价性能指标,如表1所示。

Table 1. Performance indicators for recognition assessment
表1. 识别评估性能指标
从表中可以看出,采用YOLOv2方法进行识别时,每幅图像平均需要花费0.3 s的时间,准确率达到了98.6%,不仅所用的时间少于其他两种方法,而且识别的准确率还比较高。此外,YOLOv2的假阳性率比其他两种方法的要低,而召回率高于其他两种方法。实验结果表明,采用YOLOv2网络模型对钢材压印字符进行识别具有快速性和高效性,满足工业生产的实时性需求。
采用YOLOv2对钢材压印字符进行识别的实际效果如图5所示。由图可见,YOLOv2基本能对数字和字母进行分类,并且能较准确地标识出各字符所在的位置。对于一些特征相近的字符如“8”和“B”,也能被准确地识别出来,而字符“C”和“D”会存在误识成“0”的情况,分析其原因可能跟训练的样本数有关。
同时,YOLOv2采用整幅生产标号图像作为输入,检测时即能输出一整串生产标号,比先分割字符输入,识别输出单个字符后再进行拼接的方法方便快捷很多。利用HTML与PHP相结合制作基于YOLOv2的钢材压印字符识别平台,可以在网页上远程实现一键得到生产标号,结果显示如图6所示。
4. 结论
随着深度学习的深入研究和不断发展,越来越多的针对图像、视频的视觉识别算法被开发出来,这些算法的网络框架性能不断提升并且使用起来十分的便捷。本研究将目前对目标检测比较快速准确的YOLOv2算法应用于部件钢印字符识别中,实验结果表明,与其他的经典的字符识别算法如LeNet-5和分类器SVM相比,YOLOv2的识别准确率较高,且算法处理时间较少。同时,通过对网络输出结果的改进,可以直接输出图像中正确的生产标号,不需要把图像分割成单个字符再进行识别,更加的方便快捷。
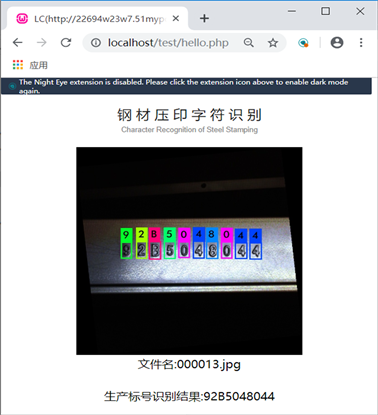
Figure 6. Steel stamping character recognition platform based on YOLOv2
图6. 基于YOLOv2的钢材压印字符识别平台
这有效提高了工业生产管理的稳定性和实时性。后续的研究工作将不断扩充数据集样本数量,还有对样本图像采用边缘检测等预处理方法。
致谢
本研究室的卢健祥,李壁江等多位同学完成了很多先期准备工作;匿名审稿老师对本文提出了宝贵的修改意见,在此表示感谢!
基金项目
本课题得到广西自然科学基金“形状纹理特征量的提取及其优化研究”(No. 2017JJA170765y);国家自然基金“基于CT数据的胃癌模型的三维重建和手术仿真”(No. 81760324)资助。