1. 引言
光学相干断层扫描(Optical coherence tomography, OCT)可以用来观察视网膜的形态,所以近些年被广泛应用于眼科疾病的诊断。目前,视网膜疾病的诊断,如年龄相关性黄斑变性(Age-related macular degeneration, AMD)和糖尿病视网膜病变(分别是老年人和糖尿病患者失明的主要原因)主要基于临床检查和专业的眼科医生对OCT图像的主观分析 [1]。在我国,眼科疾病患者多、医生少的矛盾非常突出,为了减轻医生负担、提高诊断的效率和准确度,开发基于OCT图像的视网膜疾病计算机辅助诊断系统具有重要的意义,其中涉及到的关键技术问题是视网膜OCT图像的分割和分类问题 [2]。
近些年,许多研究者致力于视网膜疾病分类算法的研究。在2011年,Liu等人 [3] 利用LBP特征和多尺度空间金字塔,提出了在视网膜中心凹OCT图像中检测视网膜疾病的算法。2012年,Zheng等人 [4] 提出了一个利用图论来帮助分类视网膜疾病的算法。2013年,Zhang等人 [5] 利用核主成分分析(KPCA)对正常的眼睛和晚期AMD眼睛进行分类,分类精度达到92%;2014年,Mookiah等人 [6] 基于Gabor特征提出一种自动检测干性AMD的算法,并经过两组数据的验证,得到了一个相对不错的分类精度;Srinivasan等人 [7] 设计了基于方向梯度直方图(HOG)特征的OCT视网膜病变图像分类方法,对健康视网膜、AMD、DME进行分类,取得了较高的分类精度;2017年,孙延奎等人 [8] 在Srinivasan等人 [7] 研究的基础上,提出了一个基于稀疏编码和字典学习的全自动检测AMD和DME的框架,并且分别采用Duke光谱域数据与北京某医院的临床数据对算法进行验证,分类精度比较理想。近年来,由于深度学习在计算机视觉、语音识别、自然语言处理方面的成功应用,很多学者开始将深度学习方法应用于视网膜疾病的分类方面 [9] [10] [11] [12]。
这些算法无论是从准确性还是减轻工作量的角度都可以极大地帮助医生对眼科疾病进行诊断。但仍然存在一些问题:1) 对于视网膜OCT图像,现有文献中采用的特征有LBP特征 [3] 、Gabor特征 [6] 、SIFT特征 [8] 等少数几种,因此,还有必要尝试新的特征,以进一步提高诊断的准确率;2) 现有文献中的高精度算法,其算法的效率比较低,计算复杂度比较高,不利于对眼科疾病的实时诊断。本文在孙延奎等人 [8] 的研究基础上,提出了一种基于局部相位量化(local phase quantization, LPQ)特征的视网膜OCT图像分类算法,算法的主要步骤如图1所示。
2. 预处理
视网膜OCT图像在获取过程中不可避免地会受到外界因素的影响,在图像上产生噪声,尤其是斑点噪声,严重影响后期对图像的分析。其次,在OCT成像过程中,视网膜的形态、位置会发生大幅度的变化,这使得无法将全部的视网膜对齐到一个相对统一的位置上,并且OCT图像中包含了大量的无关部分,这些问题都严重影响之后的图像特征提取以及分类的准确度。因此,在提取特征前,需要对图像进行必要的预处理操作。本文参照孙延奎等人在文献 [8] 中的操作,将预处理过程分成三部分:感兴趣区域探测阶段、拟合阶段、切割阶段。
在感兴趣区域探测阶段,主要的目的是获取整个视网膜形态,具体步骤如下:1) 利用BM3D [13] 滤波器对原图像去噪;2) 去除左右空白边缘,并用OCT图像中背景像素的平均值填补图像上下部分的无关空白图像;3) 利用Otsu算法 [14],对去噪后图像进行全局阈值处理,获取视网膜结构;4) 对阈值处理后的图像进行中值滤波,去除视网膜周边的黑色斑点;5) 利用形态学闭操作去除视网膜内部的大的黑色斑点,这些斑点无法用中值滤波来去除;6) 利用形态学开操作去除视网膜外的白色斑点。
在拟合阶段,为了将不同图像中视网膜区域对齐,本文从形态学开操作后得到的图像中提取两组数据点:中间数据点(在每列像素中,通过对白色像素的坐标取平均值得到中间数据点的坐标)和底部数据点(在每列像素中,取最下边的白色像素作为底部数据点)。然后,对中间数据点作二次多项式拟合,如果拟合开口向上则选用中间数据点,否则选用底部数据点。
当选择中间数据点时,继续用数据点作线性拟合,比较两种拟合点集与原中间数据点的相关系数,最终选择相关系数高的拟合方法。当选择底部数据点集时,对底部数据点作二次多项式拟合,如果开口向上,则继续用数据点作线性拟合,然后选用相关系数大的拟合方法;如果开口向下,则直接选用线性拟合方法 [8]。
在切割阶段,根据上述拟合的结果,将视网膜对齐,然后切割掉对识别视网膜类型无关紧要的部分。具体过程为:对每一列像素向上或向下平移若干像素,使得拟合曲线上的像素点位于一条水平线上,然后根据对齐后白色像素的最高点和最低点,切割出图像的感兴趣部分。根据此方法,可以保留有利于分类的视网膜形态结构,并且去除无关紧要的干扰部分。
图2为视网膜OCT图像预处理过程的示例。

Figure 2. Illustration of image preprocessing: (a) Original retinal OCT image; (b) Denoising; (c) Remove and fill in blanks; (d) Binarization; (e) Median filtering; (f) Morphological closing; (g) Morphological opening; (h) Polynomial fitting; (i) Aligning
图2. 图像预处理示例:(a) 原OCT图像;(b) 去噪;(c) 去除、填充空白;(d) 阈值化;(e) 中值滤波;(f) 形态学闭操作;(g) 形态学开操作;(h) 多项式拟合;(i) 视网膜对齐
3. 特征提取和分类
3.1. LPQ特征
LPQ是一种处理空间模糊图像纹理的特征描述子,该特征描述子具有模糊不变性 [15] [16]。LPQ特征通过在灰度图像
上的每个像素点x的
的矩形邻域
进行离散傅里叶变换提取相位信息,即
(1)
其中
为频率
的2维离散傅里叶变换的基向量,
为
中
个像素的灰度值所组成的向量。
LPQ只在
,
,
,
四个频率点上考虑傅里叶系数,其中a为一个足够小的数。令
傅里叶系数中的相位信息由
中每个分量的实部和虚部表示,可以通过一个简单的分级量化方法量化:
其中
为
向量中的第j个分量。量化系数通过二进制编码
表示
为一个[0,255]的整数。在提取图像的LPQ特征时,需要首先将图像分割成一些小的矩形块,在每个矩形块上,计算每个像素的量化系数,然后再在每个块上生成量化系数的直方图,最后将所有矩形块的直方图向量串联起来,得到图像的LPQ特征。
3.2. 特征降维和分类
对图像进行特征提取后,由于特征维数过高,不仅加大了计算的复杂度,而且特征中包含冗余信息以及噪音信息,使得在识别过程中造成误差,降低准确度。降维可以帮助减少冗余信息所造成的误差,提高效率,增强准确度。本文选用主成分分析(Principal Component Analysis, PCA)对提取的LPQ特征进行降维,之后选用线性的SVM对数据进行分类。PCA是最常用的线性降维方法,它的目标是通过某种线性投影,将高维的数据映射到低维的空间中表示,并期望在所投影的维度上数据的方差最大,以此使用较少的数据维度,同时保留住较多的原数据点的特性。
4. 数值实验
本文选用Duke视网膜OCT数据对算法进行验证。该数据集包含45名志愿者的视网膜OCT图像,其中包含15名正常人,15名AMD患者,15名DME患者的视网膜OCT图像 [7]。和其他文献一样,本文采用留三法交叉验证,即每次随机从每个类别中选出一个志愿者的数据作为测试样本,其余42名志愿者的数据作为训练样本。为了得到的结论具有一般性,我们按照此种方法选取20组训练样本和测试样本。
在预处理阶段的操作及参数设置如下:选用BM3D对原视网膜OCT图像去噪,其中 取25;使用Otsu算法自动地对每个图像进行阈值处理;选用35 × 35的中值滤波器进行滤波;利用大小为40的圆形结构元进行形态学闭操作,利用大小为5的圆形结构元进行形态学开操作。最后,将分割后的图像大小统一缩放为40 × 200。在特征提取阶段,本文采用LPQ特征,然后再利用PCA对所得的特征向量进行降维,最后,采用线性支持向量机对图像进行分类。为了更为客观地评价本文所提出的算法,我们对于随机选取的20组训练样本和测试样本,分别采用LPQ特征和现有文献中提到的LBP特征 [3] 、Gabor特征 [6] 以及SIFT特征 [8] 进行实验,并统计在20组测试样本上的平均识别率。
图3给出了采用这四种特征时,平均识别率随PCA降维后维数变化的曲线。从图中可以看出,对于不同的维数,选用LBP特征的平均识别率整体最低且幅度最大,而LPQ、SIFT与Gabor三种特征的平均识别率相对比较平稳,总的来讲,LPQ特征的平均识别率相对于其他三种特征要更高。可见LPQ特征在视网膜疾病分类方面,表现出更好的优势,具有很好的鲁棒性。四种特征的最高平均识别率如表1所示。从表中可见LPQ特征在800维时平均精度可以达到92.23%,明显高于其他三种特征,可见LPQ特征要更适用于视网膜OCT图像,可以很好的表征视网膜图像的纹理特征,能够更好的结合分类算法对视网膜图像进行分类,提高分类精度。
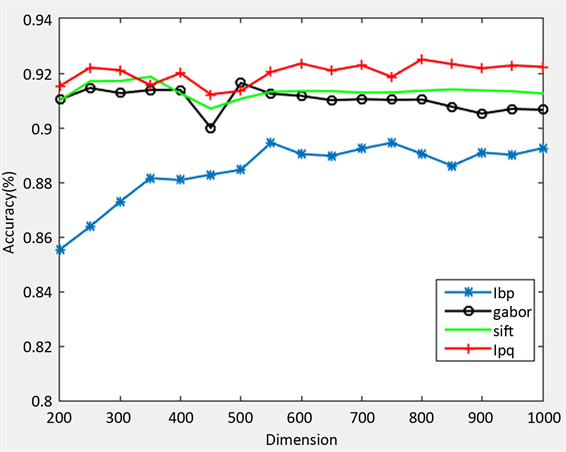
Figure 3. The curves of mean accuracy vs. dimension
图3. 平均识别率随维数变化的曲线

Table 1. Comparison of classification results
表1. 分类结果对比
5. 结论
本文将LPQ特征应用于对视网膜OCT图像分类,提出了基于OCT图像与LPQ特征的视网膜疾病检测算法,并在Duke视网膜数据集上进行了实验,并与现有文献中所用的特征,包括LBP特征、Gabor特征和SIFT特征进行了比较研究。实验结果表明,本文提出的算法具有较高的精度。本文提出的算法对视网膜疾病的计算机辅助诊断具有重要的意义。在今后的研究中,我们将考虑将多种特征进行融合,或者尝试将LPQ特征与更优的分类算法进行结合,以进一步提高视网膜OCT图像分类的准确性和鲁棒性。
基金项目
本文受到河北省自然科学基金项目(A2019202135)资助。