1. 引言
近年来,随着水文预报模型的不断更新和预报方法的不断完善,水文预报的精度得到了一定程度的提升。但由于水文预报的误差是客观存在且不可避免的 [1],为了减少预报误差对水库调度带来的不利影响以提高水库优化调度效益,一方面需要进一步提高预报模型的预测精度,另一方面也有必要研究模型产生的预报误差,统计其分布规律并进行定量分析 [2] [3]。目前研究中,通常将径流预报误差作为随机变量,利用概率统计的方法来分析其统计特性和确定其概率分布形式 [4]。左保河 [5] 采用实测预报误差序列分析和谱分析相结合的方法,基于正态分布和对数正态分布对水文预报中的误差分布特性进行了研究,结果表明无论是大流域还是小流域,对数正态分布更适合描述其预报误差分布规律;董前进等 [6] 通过对三峡水库汛期入库径流预报误差资料的计算分析表明,其预报误差基本服从正态分布,并利用统计图形对Laplace和Logistic的分布拟合效果进行了比较,结果显示Laplace分布更适合描述其误差分布规律。已有研究成果表明对于不同的水库,其入库径流预报误差分布规律有所不同,因此找到各自拟合度最优的分布曲线和分布函数是十分必要的,而且这些多是针对水库的单一入库径流预报误差进行的分析,对于梯级水库群来说,有多条径流汇入的情况下,使得整个梯级水库群系统具有多源输入的特性,径流预报误差存在多重不确定性,目前相关研究成果尚不多见。
研究多条径流汇入梯级水库群系统带来的不确定性,涉及到多变量问题。比较常见的多变量分析方法有多元联合分布函数、非参数方法、将多维联合分布转换成一维分布的方法以及经验频率法等 [7],这些方法在处理多变量联合分布时都有自身的局限性,难以准确描述水文数据的多元分布统计特性。近些年来,由于Copula函数可以很好描述多变量之间相关性,能对不同类型的边缘分布构造相对合理的联合分布,并具有形式灵活多样、计算较为简单等优点,在水文分析研究上受到了广泛关注 [8]。例如,Favre [9] 采用多维Copula函数构建了洪峰、洪量极值的联合分布,并探讨了其适用性;顾佳帅等 [10] 采用4种对称Archimedean Copula函数构建了干旱历时、干旱烈度和烈度峰值的二维、三维联合分布;谢华等 [11] 运用多维Frank Copula函数构建了三条河流的径流量联合分布,分析得到了不同径流量级的遭遇概率和条件概率;张冬冬 [12] 等采用Copula函数计算洪峰、洪量和历时的联合分布并计算得到相应的重现期。本文以锦屏一级与官地水库构成的梯级水库群系统中两条汇入径流的预报误差分析为例,采用多种分布曲线对其进行拟合,得到效果最优的边缘分布曲线,在此基础上,采用Copula函数对两条径流预报误差服从的边缘分布构造联合分布,得到拟合效果最优的copula函数并随机抽样产生径流预报的模拟值,将模拟值与实际值进行比较,验证方法的可行性。
2. 多源径流预报误差分析方法
2.1. 各径流预报误差描述
设
为第j条径流在第i个预报作业时刻下的预报相对误差:
(1)
式中,
为预报值,
为实际值,m为序列长度,n为汇入梯级水库群的径流条数。
则对于具有n条径流汇入的梯级水库群系统,在第i个作业时刻下的径流预报误差为
。n条输入的径流预报误差分别设为
,其对应的边缘分布分别为
,密度函数分别为
。
对于
的求解通常可以选用正态分布、logistic分布、t分布、stable分布、Gamma分布、广义极值分布、对数正态分布、指数分布等等 [13] 进行拟合选取。
2.2. 多源径流预报误差联合分布
对于具有n条径流输入的梯级水库群系统来说,各条径流之间可能存在的相关性导致各径流预报误差之间也存在一定的相关性,基于此,采用Copula函数构造联合分布描述求解。为了寻求
的联合分布函数
,根据n维Sklar定理可知,一定存在一个Copula函数C,使得下式成立:
(2)
式中,
分别为随机变量
的边缘分布,即
。
的联合概率密度函数为:
(3)
对于(2)式与(3)式中的Copula函数C可以考虑水文领域常用的阿基米德Copula函数,比如n元Gumbel Copula,n元Clayton Copula以及n元Frank Copula等。
2.3. 多源径流预报误差联合分布求解步骤
1) 对n条汇入梯级水库群的径流预报误差序列数据进行分析。主要采用均值、标准差和确定性系数作为统计量描述,计算公式分别如下:
(4)
(5)
(6)
式中,
为预报值,
为实际值,m为序列长度。
2) 对n条径流预报误差系列数据建立频率分布直方图,观察其数据分布情况选用合适的边缘分布曲线进行拟合。
3) 选取拟合效果最好的分布曲线作为边缘分布。判断依据主要为均方根误差和判定系数等。计算公式如下:
(7)
(8)
式中:
为各拟合分布的离散点的概率值,
为样本总体分布的概率密度函数值。判定系数的取值是[0,1],其值越大表示拟合效果越好,均方根误差值越小表示拟合效果越好。
4) 选取常用的n元阿基米德copula函数对得到的n条边缘分布曲线构造联合分布并判断拟合效果。判断依据为离差平方和最小准则(OLS)和AIC信息准则法,其计算公式分别如下:
(9)
(10)
其中,
为联合分布的经验频率,
为联合分布的理论频率,k为相应n元copula函数的参数个数。
5) 根据计算结果得到拟合效果最佳的n元copula模型参数及表达式,并根据蒙特卡洛法随机抽样,得到n条输入径流的预报误差的边缘分布值,再根据逆函数原理,通过求取第(3)步中边缘分布曲线的逆函数,从而得到模拟的n条径流预报误差值,并计算模拟值与实际值的特征值,进行比较。
3. 实例研究
雅砻江是金沙江最大的支流,是中国水能资源最富集的河流之一。全长1571 km,流域面积13.6万km²,河口多年平均流量为1910 m³/s,年径流量近600亿m³,占长江上游总水量的13.3%。其干流共规划了22级水电站,总装机容量约为3000万kw,年发电量约为1500亿kw·h。雅砻江下游河段是其目前水电开发的重点河段,有锦屏一级、锦屏二级、官地、二滩、桐子林五大电站。九龙河是雅砻江下游左岸的一级支流,发源于九龙县北端与康定县交界处,全长128 km,由北向南至文家坪注入雅砻江。其水能资源丰富,最高流量200 m³/s,理论蕴藏发电量103.9万kw。
锦屏一级电站(锦西水库)和官地水库构成的梯级水库群系统中,上游有雅砻江汇入锦西水库,区间还有九龙河汇入官地水库,两条径流汇入使得梯级水库群存在多重不确定性,基于此,本文以锦西入库径流预报误差和九龙河区间入流预报误差作为研究对象,构建联合分布进行分析,以期为水库制作准确调度方案提供一定的参考依据。
3.1. 确定边缘分布
数据采用2013年6月~2014年6月锦西入库和九龙河日径流预报过程中预见期为6 h的预报值和实测值,采用均值、标准差和确定性系数三个指标作为统计量描述,对两条径流(下文简称锦西入库和区间入流)预报误差的样本做统计分析。由公式(4)、(5)、(6)计算可得各指标的结果见表1。

Table 1. Statistical description of runoff prediction errors in Jinxi reservoir inflow and interval inflow
表1. 锦西水库入库和区间入流的径流预报误差的统计描述量
对两条径流预报误差序列数据分别建立频率分布直方图,根据分布情况选用不同分布曲线对其进行拟合,分别得到两条径流预报误差的拟合效果图,见图1、图2。
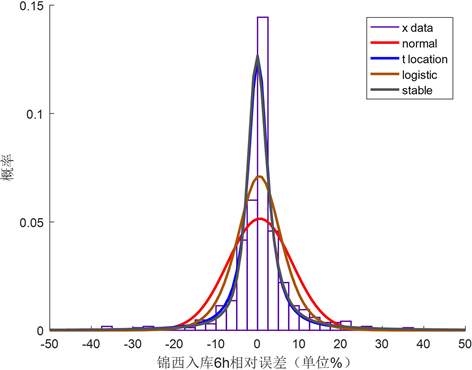
Figure 1. Jinxi reservoir inflow runoff forecast error distribution
图1. 锦西水库入库径流预报误差分布拟合
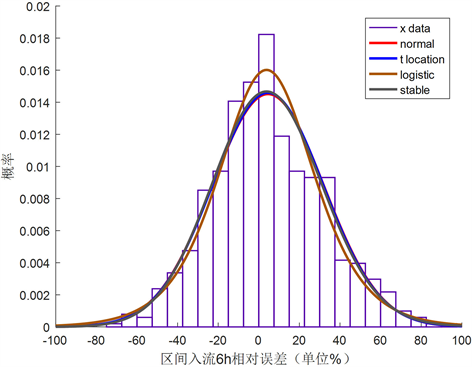
Figure 2. Interval inflow runoff forecast error distribution fitting
图2. 区间入流径流预报误差分布拟合
由图1锦西水库入库预报误差的频率分布直方图中可以看出,频率分布直方图呈现中间高两边低,选用满足此类描述的分布,如正态分布、logistic分布、t分布和stable分布对其进行拟合,可以初步看到拟合效果好的分布情况依次是t分布 > stable分布 > logistic分布 > 正态分布。图2中区间入流预报误差的频率直方图也大致满足中间高两边低,同样选取4种分布对其序列进行拟合,可以看出logistic分布对于峰值的拟合优于其他3个分布曲线。由公式(7)、(8)计算判定系数和均方根误差再次判断各曲线的拟合效果,计算结果见表2。
Table 2. Applicability judgment table for each distribution curve of Jinxi inflow and interval inflow runoff forecast error
表2. 锦西水库入库和区间入流径流预报误差的各分布曲线适用性判定表
对于锦西入库径流预报误差序列,由表2可以看出,判定系数t分布0.9349 > stable分布0.9059 > logistic分布0.7356 > 正态分布0.6213,均方根误差t分布0.026 < stable分布0.0283 < logistic分布0.0332 < 正态分布0.0399,由判定系数越大越好和均方根误差越小越好这一判定依据,可以得到拟合效果好的分布依次是t分布 > stable分布 > logistic分布 > 正态分布,这与图2得到的结论是相同的,所以可以得到锦西入库径流预报误差服从t分布。类似的,对于九龙河区间入流预报误差序列,由表2可以看到logistic分布的判定系数最大,均方根误差最小,所以得到九龙河区间入流预报误差服从logistic分布。
锦西入库、九龙河区入流径流预报误差拟合的4个分布曲线的参数见表3。
Table 3. The distribution parameter table of runoff forecast error of Jinxi inflow and interval inflow
表3. 锦西入库、区间入流的径流预报误差各分布参数表
设锦西入库和区间入流的径流预报误差分别为x,y。由表3可以得到,锦西入库径流预报误差服从的t分布参数分别为
,可以得到t分布表达式如下:
(11)
九龙河区间入流预报误差服从的logistic分布参数
,可以得到分布函数和密度函数分别如下:
(12)
(13)
3.2. Copula函数构造联合分布
根据得到的锦西入库径流预报误差服从的t分布、九龙河区间入流径流预报误差服从的logistic分布采用copula函数构造联合分布。
为了研究两条径流预报误差的相关性,采用t检验进行检验。计算锦西入库(x)和九龙河区间入流(y)两条径流预报误差序列的相关系数r,其计算公式如下:
(14)
通过计算可以得到r = 0.1423,然后根据t检验构造统计量见式(15):
(15)
指定置信度
,由t分布表中查得临界值
,由(15)计算得到
,所以,可以认为x和y不独立,即锦西入库和区间入流的径流预报误差两个序列并不独立,具有一定的相关性。
在此基础上选择常用的三种阿基米德Copula函数:GH Copula、Clayton Copula和Frank Copula函数,对两个径流序列构造联合分布。利用Matlab得到三个Copula函数下的联合分布函数图和密度函数图如下,见图3~5。
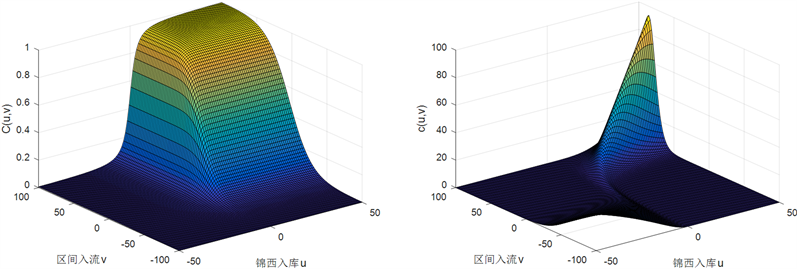
Figure 3. Distribution function graph and density function graph of GH copula
图3. GH copula的分布函数图和密度函数图
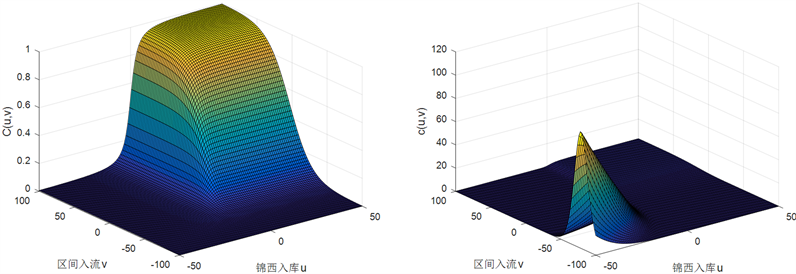
Figure 4. Distribution function graph and density function graph of Clayton copula
图4. Clayton copula的分布函数图和密度函数图
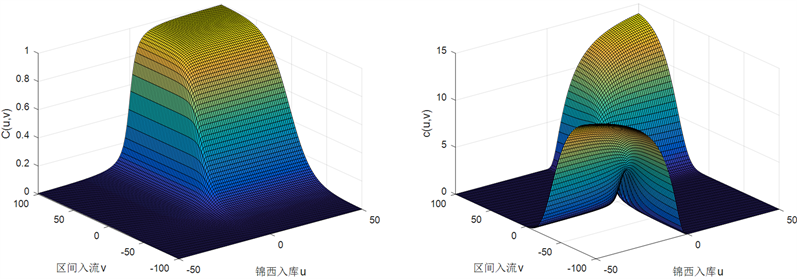
Figure 5. Distribution function graph and density function graph of Frank copula
图5. Frank copula的分布函数图和密度函数图
采用极大似然法估计得到的3个Copula函数的参数,以及采用离差平方和最小准则(OLS)和AIC信息准则法对联合分布的适用性判定的结果见表4。
Table 4. Table of copula function parameter values and applicability judgment
表4. Copula函数参数值及适用性判定表
采用OLS和AIC准则值均为最小为判断依据,由表4可以得到,3个Copula函数的拟合情况分别为Clayton copula > GH copula > Frank copula。因此选用Clayton copula构造联合分布,其参数值
,相应的分布函数和密度函数分别如下式:
(16)
(17)
式中:
分别为x和y的边缘分布函数即
。
3.3. 随机模拟
由Clayton copula函数模拟5000次锦西入库和九龙河区间入流的径流预报误差作为模拟值,并计算模拟值与实际值的特征值见表5。
Table 5. Comparison table between the simulated value and the actual value of the forecast error of Jinxi inflow and interval inflow
表5. 锦西入库和区间入流误差模拟值与实际值特征值对比表
由表5可以看出实际值与模拟值相差不大,表明构造的联合分布可以用来模拟梯级水库群中两条径流汇入的预报误差的实际情况,以此来表征整个系统输入的不确定性。将模拟值与预报值叠加,可以产生一系列考虑径流预报误差的模拟值,能得到更接近实际的来水径流过程。
4. 结论
本文以锦西入库和九龙河区间入流的径流预报误差分析为例,考虑多条径流之间存在的相关性带来的梯级水库群系统的多重不确定性,基于Copula函数构建了多源径流预报误差的联合分布,得到的结论如下:
1) 对于不同的径流预报误差序列,其服从的分布规律不同。锦西入库径流预报误差服从t分布,九龙河区间入流径流预报误差服从logistic分布。
2) Clayton copula函数构建的两个径流预报误差序列的联合分布拟合效果更好。基于此函数产生的模拟值与实际值的特征值结果相差不大,说明建立的多源径流预报误差的联合分布方法具有一定的可行性,可以将产生的模拟值与预报值叠加后得到更接近实际来水的一系列径流过程,为水库调度决策提供一定的参考依据。
基金项目
国家自然科学基金(51709105);中央高校基本科研业务费专项资金资助(2019MS031)。