1. 引言
尽管医疗保险资金再分配是医疗保险机制中重要的一环,但在日常的运行过程中常常遇到资源分配不合理的问题。而对患者来说,难以预先得知较为准确的治疗费用,也将对其治疗过程产生不利的影响。所以,研究医疗费用预测对建立单病种的支付额度和患者的治疗十分重要。但是,由于很多因素的影响,单病种支付额度不可能是始终不变的,尤其是癌症这类医疗费用极差较大的病种来说,其治疗过程中产生的费用更是难以准确预测。究竟该如何准确给出治疗费用是摆在研究人员面前的棘手问题。
国内外对于该问题已有一定的研究,近些年,Robert B. Fetter等人提出的DRGs (Prospective Payment System Based On Diagnosis Related Groups) [1],即诊断相关分类,有着迅速发展,它是当今世界公认的比较先进的支付方式之一。它以病例组合为基本依据,考虑了患者的个体特征以及并发症和合并症情况等因素,将诊疗过程相似、费用支出相近的病例分到同一个组,进而接受统一标准的诊疗预付费。这一方法通过统一的诊断分组定额支付,激励医院加强质量管理、优化资源利用。而国内对于医保赔付和医疗费用预测问题也有一些成果,林倩、杜剑亮、Ai-Jing Luo等人 [2] [3] [4] 利用决策树实现DRGs,并对医保赔付做出指导。张凯、王若佳 [5] [6] [7] 引入数据挖掘技术解决该问题,提供了新的思路。
本文对大量鼻咽癌患者病历进行数据挖掘,根据影响疾病治疗费用的主要因素,基于回归决策树构建了针对鼻咽癌(NPC)患者个体的费用预测模型,并运用Boosting算法进行模型改进,最后解释模型的现实意义,为医疗保险资源的分配和单个病例预期费用提供参考。
2. 描述性统计
2.1. 数据预处理
本文处理的鼻咽癌患者数据采样于广东省某肿瘤医院,但由于原始数据存在缺失、不规范等原因,需要对数据进行预处理。针对此次课题,本小组利用莱文斯坦编辑距离算法、正则表达式、余弦相似性等方法对原始数据进行了如下处理:剔除罕见的接受手术的样本、限制ICD编码范围、去除费用大于三倍标准差的样本(如表1所示)、TNM分期标准化、费用明细整合,最终获得2064例标准化数据 [8]。

Table 1. Removing data out of three times the standard deviation
表1. 去掉大于三倍标准差的数据
2.2. 描述性统计
2.2.1. 基本情况
对鼻咽癌病例数据进行描述性统计,具体统计情况如表2 [8]。
2.2.2. 社会学数据分布情况
在2064例鼻咽癌患者病例中,男性共1605例,占病例总数的77.76%,女性460例,占病例总数的22.24%。由年龄和支付的密度散点图,即图1,可见年龄多分布于区间[41, 50]岁,支付总费用在10万元到20万元的鼻咽癌患者是密度最大的 [8]。

Figure 1. Density scatter plot of hospital expenses varying with age
图1. 住院费用随年龄变化的密度散点图
2.2.3. TNM分期数据分布情况
观察病例数据在不同分期中的分布,发现男性患者较多的现象普遍存在,并且鼻咽癌分期主要集中在三期、四期中,占比62%。
观察每个TNM分期与平均费用的关系,可知一期费用普遍较低,而二期费用最高,我们推测导致该现象的原因为二期鼻咽癌症状相对一期更为严重,但相较于三期、四期更容易被治愈,存活率相对较高,导致二期患者疗程更长,花费更多 [8]。
2.2.4. 对数据集的概况性描述
1) 男性更容易患鼻咽癌,占总患者数78%;
2) 患者多为40至60岁的中老年人;
3) 患者的治疗费用集中在20万左右,其中二期的鼻咽癌患者花费最多;
4) 就诊患者主要为鼻咽癌中晚期(三期和四期)患者。
3. 基于CART算法的费用预测
3.1. CART回归树生成算法原理
CART回归树的生成算法基于最小二乘法。在训练数据集所在的输入空间中,递归地将每个区域划分成两个子区域并决定每个子区域上的输出值,构建二叉决策树。例如给定数据集 ,输出回归树
,输出回归树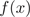 :
:
1) 第一步、选择数据集 中最优切分变量
中最优切分变量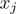 与切分点
与切分点 :求解:
:求解:

遍历变量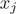 ,对固定的切分变量
,对固定的切分变量 扫描切分点
扫描切分点 ,选择使上式达到最小值的二元有序数对
,选择使上式达到最小值的二元有序数对 。
。
2) 第二步、用选定的有序数对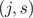 划分区域并决定相应的输出值:
划分区域并决定相应的输出值:

其中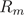 是一个用二元有序数对(切分变量及其取值)表示的定义域。由此进一步可以解得枝结点和叶节点的因变量的预测值(回归拟合值)为其结点内样本均值:
是一个用二元有序数对(切分变量及其取值)表示的定义域。由此进一步可以解得枝结点和叶节点的因变量的预测值(回归拟合值)为其结点内样本均值:
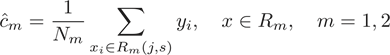
3) 第三步、对两个子区域(枝结点)重复前两步,直到满足停止条件(最大树深度、结点内最小样本量、复杂度参数阈值等)。
4) 第四步、输出回归决策树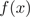 :
:
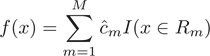
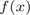 将输入空间划分为
将输入空间划分为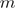 个区域
个区域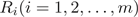 ,即
,即 个叶节点(
个叶节点( 类) [8]。
类) [8]。
3.2. 基于CART算法的费用预测
我们使用Python的sklearn.tree库实现CART回归预测,建立并训练最大深度为4的CART回归树,之后进行费用预测并与真实数据进行对比,得到如下预测费用与年龄分布散点图,由图2可知,CART算法预测的费用集中于1万至3万,对于费用较低或费用较高的病例预测效果较差。
Figure 2. Comparison between predicted and actual expenses based on CART
图2. 基于CART算法的预测费用与真实费用对比
4. 基于Boosting算法的费用预测
Boosting (提升方法)是Ensemble Learning算法的一类。这类算法的思想是将弱学习器提升为强学习器。即先用初始训练集训练出一个基学习器,再根据基学习器表现对训练样本分布进行调整,那些基学习器判断错误的样本,在之后会被赋予更大的权值,然后基于调整后的样本来训练下一个基学习器,一直反复进行,直到达到理想效果。在2000年左右,Friedman的几篇论文提出Boosting算法的成功实现 [9] [10]。
Boosting常用的两种方法为AdaBoost (Adaptive Boost)和梯度提升(Gradient Boosting)。本章及下一章选取已出院鼻咽癌病例样本进行如下的费用预测,即所得到的费用可以认为是该病例治疗的最终花费。其中,取性别、年龄、住院次数、住院天数和首诊分期为自变量,建立并训练模型预测最终费用,并比较CART算法、AdaBoost算法、梯度提升算法的预测效果。经过反复的实验,最大树深度为4且弱学习器为300个的梯度提升算法表现最好。
4.1. AdaBoost算法原理
由于CART预测效果较差,我们选用集成算法中的提升方法进行改进。首先研究基于AdaBoost算法的费用预测。
4.1.1. AdaBoost算法思路
AdaBoost的思路为,先从初始训练集中训练出一个基学习器,再根据基学习器的表现对训练样本分布进行调整,对所有基学习器采用加权结合,增大分类或回归误差小的基学习器的权值,减少误差率大的基学习器的权值。
4.1.2. AdaBoost算法步骤
输入:训练集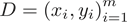 ,其中,
,其中, ;基学习算法
;基学习算法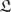 ;基学习器个数
;基学习器个数 。
。
过程:
1) 初始化训练样本的权值分布
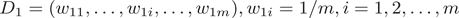 。
。
2) 对迭代轮次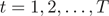 。
。
a) 使用具有当前分布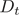 的训练数据集训练基学习器
的训练数据集训练基学习器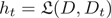 ;
;
b) 计算训练集上的样本最大误差:

计算每个样本的相对误差:
如果是线性误差,则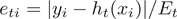 ;
;
如果是平方误差,则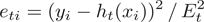 ;
;
如果是指数误差,则 ;
;
c) 基学习器在训练数据集上的回归误差率:
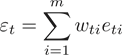
d) 基学习器的权重系数:

e) 更新训练集的样本分布:
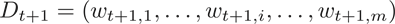
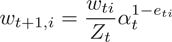
其中,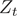 是规范化因子:
是规范化因子:

f) 构建基学习器的线性组合,得到最终的强学习器:
输出:强学习器 [11] [12]。
[11] [12]。
4.2. Gradient Boosting算法原理
由于对AdaBoost算法对异常样本敏感,异常样本在迭代中可能获得较大权重,影响强学习器的预测准确性。接下来将使用Gradient Boosting算法进一步改进费用预测模型。
4.2.1. Gradient Boosting算法
由Freidman提出的梯度提升(gradient boosting, GB)算法 [10],若将梯度提升算法里的弱算法选择为决策树,则的到GBDT算法(Gradient Boosting Decision Tree)。该算法主要利用最速下降法的近似方法,利用损失函数的负梯度在当前模型的值
作为回归问题提升树算法中的残差的近似值,拟合一个回归树。
4.2.2. Gradient Boosting算法步骤
接下来是该算法的训练步骤 [11] [12] :
给定训练数据集
 。
。
其中 是变量自变量的个数。损失函数
是变量自变量的个数。损失函数 。
。
1) 初始化
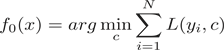 。
。
2) 对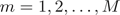 。
。
a) 对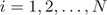 ,计算
,计算
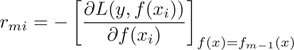 ;
;
b) 对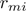 拟合一个回归树,得到第
拟合一个回归树,得到第 棵树的叶节点区域
棵树的叶节点区域 ;
;
c) 对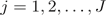 ,计算
,计算
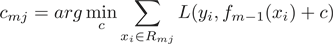 ;
;
d) 更新 ;
;
3) 得到回归树
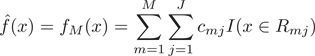 。
。
4.3. 基于Boosting算法的费用预测
我们使用Python的sklearn.ensemble库分别实现AdaBoost算法、GBDT算法,最终建立如下两种费用预测模型模型:
基于AdaBoost算法:以最大深度为4的CART回归树作为基学习器,基学习器300个,学习速度为1,损失函数为linear函。
基于GBDT算法:以最大深度为4的回归树作为基学习器,基学习器100个,学习速度为0.1,损失函数为l s函数。
下面进行费用预测并与真实数据进行对比,得到预测费用与年龄分布的散点图,如图3、图4。
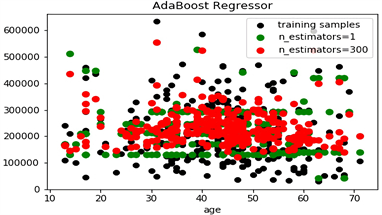
Figure 3. Comparison between predicted and actual expenses based on AdaBoost
图3. 基于AdaBoost算法的预测费用与真实费用对比

Figure 4. Comparison between predicted and actual expenses based on Gradient Boosting
图4. 基于Gradient Boosting算法的预测费用与真实费用对比
5. 预测结果分析及评价
5.1. 三种算法对总费用的预测结果与真实结果的比较
现对比研究基于CART算法、AdaBoost算法、GBDT算法对总费用预测的结果。
直观地,由图5可知,三种算法预测效果有明显不同。尤其值得指出Boosting算法的预测结果较CART算法的预测结果更加分散,其中GBDT算法的预测结果最为分散,且预测结果的分布更接近于真实值,Boosting算法对于预测效果有着明显的改进。
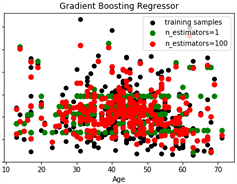
Figure 5. Comparison among predicted results by using CART, AdaBoost and GBDT
图5. 三种算法费用预测效果对比
图6是基于AdaBoost算法和GBDT算法的费用预测结果与真实值比较的折线图,黑色的圆形散点为对应患者的总费用的真实值(经过排序),蓝色曲线为基于AdaBoost算法的预测结果,红色曲线为基于GBDT算法的预测结果。显然红色曲线更趋近于真实值的分布,即基于GBDT算法的预测效果的效果最好。

Figure 6. Comparison between predicted results by using AdaBoost and GBDT
图6. 基于AdaBoost算法、GBDT算法的预测效果对比
5.2. 对集成学习算法的5个回归评价指标
我们将通过5个回归评价指标,量化对比三种模型的预测效果。下面先引入这5个指标,分别是均方对数误差平均值(Mean squared logarithmic error, MSLE)、平均绝对误差(Mean Absolute Error, MAE)、中值绝对误差(Median Absolute Error, MedAE)、确定系数(The Coefficient of Determination, R2)、解释方差分(Explained Variance Score, EVS)。
1) 均方对数误差平均值(Mean squared logarithmic error, MSLE)。由于本文中预测值较大,均方误差受单位影响较大,于是采用MSLE来代替均方误差。
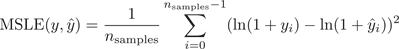
2) 平均绝对误差(Mean Absolute Error, MAE)是指预测值与真实值之间的平均差值。
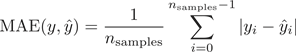
3) 中值绝对误差(Median Absolute Error, MedAE)对异常值有很好的稳定性,它通过获取预测值和真实值之间差值的绝对值的中值来计算损失。
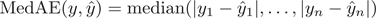
4) 决定系数(The Coefficient of Determination)即R2,用来反映模型拟合效果的好坏。最大取值为1,但它也可能是负数。一般来说,R2越大,表示模型拟合效果越好,由于随着样本数量的增加,R2必然增加,无法真正定量说明模型拟合效果,只能大概定量。

其中
5) 解释方差分(Explained Variance Score, EVS)是用来解释回归模型方差大小的分数,取值范围为0到1,EVS越大,表示回归效果越好。
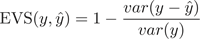 。
。
5.3. 基于5个回归评价指标的三种算法预测效果及比较
我们使用Python语言的sklearn库metrics模块计算上述五个回归评价指标,三种算法预测效果的量化数值如表3、表4所示。
Table 3. Evaluation indicators of prediction models
表3. 三种预测模型的回归评价指标
Table 4. Evaluation indicators of adjusted prediction models
表4. 三种预测模型拟合效果的改进
由上表中数据可知,虽然AdaBoost算法在MSLE、EVS、MAE、R2评价指标上的表现优于CART算法,但AdaBoost算法和CART算法的预测效果都较差,其拟合效果均低于60%,即这两种算法的预测结果与真实值并不接近。而GBDT算法在五个指标上的表现远远优于AdaBoost算法和CART算法,其拟合效果达到了85%,表明GBDT算法的预测结果与真实值较为相近,在三种算法中效果最好。该结论与先前对比的直观结论相符合。
为了检验费用预测模型是否过拟合,我们从总数据集中抽取20%的样本作为测试集,代入进行预测效果评价并与之前的评价结果进行比较。综合表5和表6可知,GBDT的拟合程度达到了85%,在测试集中拟合效果83%。基于GBDT算法建立的费用预测模型没有过拟合。
Table 5. Evaluation indicators of prediction models on test set
表5. 将测试集分别带入三种预测模型的拟合效果
Table 6. Evaluation indicators of adjusted prediction models on test set
表6. 三种预测模型的对于测试集拟合效果的改进
5.4. 费用预测模型的可解释性
通过简单地可视化树结构,可以轻松解释单个决策树。然而,集成算法模型包括数百个回归树,因此通过对各个树的可视化无法轻易解释它们。然而可以通过计算特征重要程度以及绘制部分依赖图,来直观的概括和解释Boosting模型。
5.4.1. 特征重要程度
Friedman在论文中提出在使用决策树集成算法(Tree Ensemble)时评价特征在模型中重要程度的方法 [8],便于更好的理解特征和模型。接下来介绍一下特征重要程度的计算原理,并给出已建立的三种回归模型的特征重要性。
单个决策树通过选择适当的分裂点本质上执行特征选择。此信息可用于衡量每个功能的重要性;基本思想是:在树的分裂点中使用特征的次数越多,特征就越重要。通过简单地平均每棵树的特征重要性,可以将这种重要性概念扩展到决策树集成算法中。
特征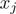 在整个模型中的重要程度为:
在整个模型中的重要程度为:
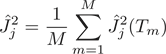
其中,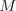 是模型中树的数量。特征
是模型中树的数量。特征 在单独一个树上的特征重要度为:
在单独一个树上的特征重要度为:

其中, 是树中非叶子节点数量,
是树中非叶子节点数量,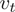 表示在内部节点
表示在内部节点 进行分裂时选择的特征,
进行分裂时选择的特征,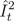 是内部节点分裂后平方损失的减少量。
是内部节点分裂后平方损失的减少量。
接下来给出五个特征分别在三种算法下的特征重要程度,由表7可知三种算法均将年龄、住院次数、住院天数作为训练模型时较为重要的特征,然而性别和TNM分期对预测模型的贡献较少。
Table 7. Magnitude of each attribute by using CART, AdaBoost and GBDT
表7. 五个特征分别在三种算法下的特征重要程度
5.4.2. 部分依赖关系
部分依赖图显示了训练模型得到的目标函数与一组特征之间的依赖关系。单项部分依赖图只研究一个特征,边缘化了所有其他特征的值,直观的展示一个特征对模型的影响。
由图7,即Gradient Boosting预测模型中五个特征的单项部分依赖图可以得到以下关系:
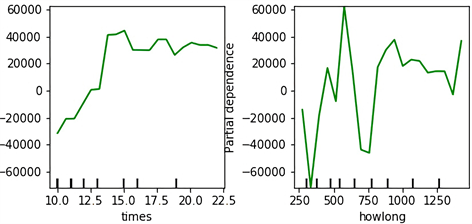
Figure 7. Single partial dependency graph based on two target characteristics
图7. 基于两个目标特征的单项部分依赖图
1) 男性患者(sex = 2)倾向于产生更多费用;
2) 小于45岁或大于60岁的患者,费用呈现年龄越大花费越多的趋势,而大于45岁小于60岁的患者,费用呈现年龄越大花费越少的趋势;
3) 住院次数与模型有较为规律的依赖关系,住院次数小于15次,次数越多费用越高,而住院次数大于15次,则费用趋于稳定;
4) 治疗天数对于模型的依赖关系较为复杂。
多项部分依赖图研究多个特征,边缘化了其他特征的值,直观的展示了多个特征对模型的综合影响。由图8,即Gradient Boosting预测模型中四个特征的多项部分依赖图可以得到以下关系:
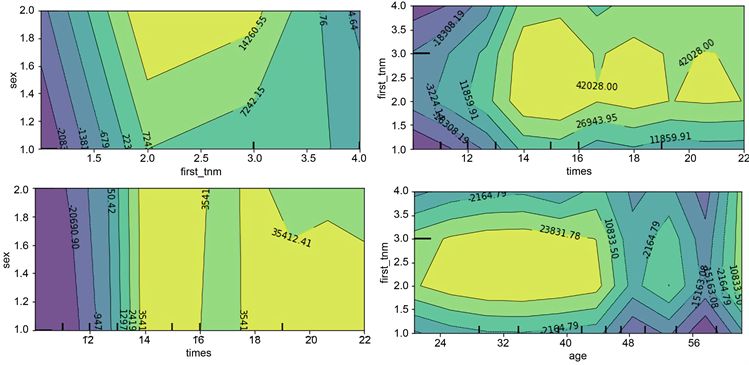
Figure 8. Multi-partial dependency graph based on two target characteristics
图8. 基于两个目标特征的多项部分依赖图
1) TNM分期在二期和三期的男性患者群体将产生大量费用;
2) 住院次数大于13次的患者,无论男女,都易产生大额医疗费用,其中二、三期的患者中这种依赖关系更显著;
3) 小于45岁的患者,费用呈现年龄越大花费越多的趋势,其中二、三期的患者中该关系更显著。
通过分析部分依赖图,能够直观的理解和解释基于GBDT算法预测模型中复杂的目标函数,这是分析基于Boosting算法以及其他集成算法的模型的有效方法之一。
致谢
在该项目研究阶段,东北大学秦皇岛分校以及东软集团医疗事业部给予团队许多支持,特在此致谢。同时该项目受到东北大学秦皇岛分校创新训练项目,教育部科技发展中心科研创新基金的支持,使得项目有充足的资金得以顺利进行。最后感谢姜玉山博士为项目指明了研究方向,同时对论文的撰写提出了许多建议,使得项目及论文撰写都圆满成功。
基金项目
东北大学秦皇岛分校创新训练项目,教育部科技发展中心科研创新基金(2018A03031)。
参考文献
NOTES
*通讯作者。