1. 引言
随着我国经济的快速发展,政府、投资机构以及投资者们对股票预测的需求也越来越多 [1] 。因此,对股票价格走势的分析成为越来越多研究者关注的课题。但股票价格高度的波动性与不确定性,使其成为计算机领域和金融领域的一大难题 [2] 。
股票投资通常会选择某一类或某一只股票来作为投资对象,对这一类或一只股票进行预测,既可以将整体的股票交易信息作为训练数据,也可以只选择该类或该只股票的交易信息作为训练数据。模型有决策树 [3] 、LR [4] 、支持向量机 [5] 等传统机器学习的方法,也有深度学习的方法 [6] 。欧阳金亮和陆黎明等人 [7] 通过引入动态调整学习率的方法和附加量,对传统BP算法进行改进,然后用改进的算法对单只股票青岛海尔进行验证。毛景慧 [8] 通过研究基于LSTM的股票价格序列影响因素,使用沪深300的290只股票数据进行整体的建模预测。
本文根据以往研究中不同训练集的训练,同时考虑股票数据的时序性,选择用对时序序列有较好性能的LSTM网络分别对其训练,将训练好的模型用于预测6分类和3分类情况下的次日收盘价的涨跌幅,并对结果做对比分析。
2. 模型与实现
2.1. 模型理论基础
人工神经网络是1980年代兴起的人工智能领域的一类研究热点,它通过对人脑神经元网络进行抽象,构建人工神经单元,再通过不同的连接方式搭建不同的网络结构 [9] 。
神经网络分为多种,BP神经网络是一种按照误差逆向传播算法训练的多层前馈神经网络,也是目前应用最广泛的神经网络 [10] ;卷积神经网络(CNN)则是通过构造卷积层来提取输入特征,再利用前馈连接来完成特征的输出,它是深度学习的代表算法之一 [11] ;循环神经网络(RNN)适用于输入是序列的数据,它是一种在序列的演进方向进行递归,循环单元按照链式连接的一种神经网络 [12] 。由于其具有参数共享的特点,因此适合于序列的非线性特征学习。
长短期记忆网络(LSTM)则是对RNN的一种改进 [13] ,它通过引入门机制构建特殊的记忆神经单元,从而解决RNN不能实现信息的长期依赖问题。LSTM结构如图1所示,其包括输入门 、输出门
、遗忘门
等门结构,这些门结构通过以下的递归方程来更新细胞状态
,同时激活从输入到输出的映射。
、输出门
、遗忘门
等门结构,这些门结构通过以下的递归方程来更新细胞状态
,同时激活从输入到输出的映射。
(1)
(2)
(3)
其中,
、
、
分别表示t时刻的遗忘门、输入门和输出门。
表示激活函数,W和b分别表示权重矩阵和偏置,下标
代表遗忘门、输入门和输出门。
表示 时刻LSTM细胞的输出,
代表t时刻的输入。
时刻LSTM细胞的输出,
代表t时刻的输入。
遗忘门
决定神经单元遗弃哪些信息,该门层通过读取
和
的状态,输出一个0到1之间的值,0代表完全舍弃,1代表完全保留。输入门
决定神经单元要更新的值,它从遗忘门筛选完的信息中,通过tanh函数更新神经单元状态。最终神经单元输出的状态由输出门
决定,其先用sigmoid层决定要输出的神经单元状态,然后将这些状态用tanh函数压缩在−1到1之间。
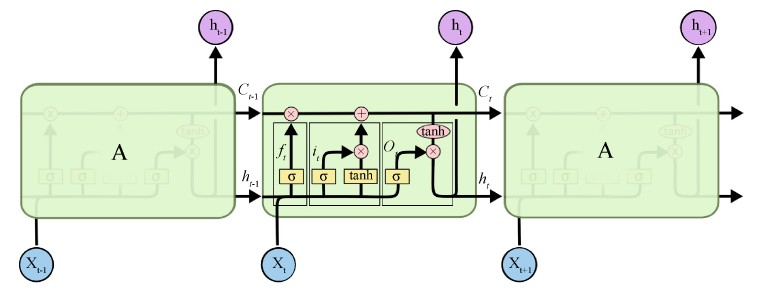
Figure 1. LSTM unit structure [14]
图1. LSTM单元结构 [14]
2.2. 股票预测问题描述
本文主要针对预测股票涨跌幅度的目标,将其转换为一个多分类任务来进行处理。
影响股票涨跌的因素有很多,与股票本身信息相关的有其基本交易数据如开盘价、收盘价、最高价、最低价、交易量、涨跌幅等6类,还有交易数据衍生出的一些统计技术指标,如换手率等 [10] 。
除了交易数据,股市波动还通常和舆论、政策等因素相关。但这些特征信息不能直观、即时的反映到后续的股票价格中去,同时这些信息是否与股票的基本信息耦合也尚未论证。因此本文只对股票的6类基本交易数据作为输入特征。记某连续T个交易日的价格序列为:
本文根据股票价格的前T天的历史交易信息,预测下一天股票收盘价较第T天的涨跌幅区间
。6分类下的第
天的收盘价涨跌幅区间定义如下:
(4)
0~5分别代表了6个涨跌幅区间,模型最终是预测第
天收盘价的涨跌幅属于哪个区间。
在股票预测时,预测股票是否出现大涨或大跌往往比只预测涨跌更具有实际意义,因此,本文还做了涨跌幅3分类的情况,既将第二天股票收盘价涨幅超过1%的作为大涨,跌幅超过−1%的作为大跌,在这之间的认为是不涨不跌。3分类下第
天的收盘价涨跌幅区间定义如式(4)所示:
(5)
2.3. 预测方法
本文利用能长久保持时序信息的LSTM作为网络框架,网络的输入包括6个基本交易数据特征:开盘价、最高价、最低价、收盘价、涨跌幅和交易量。
考虑到单层的网络对特征学习效果不佳,构建一个三层的LSTM网络,每层神经元节点数为128,层与层之间全连接。神经网络的输出层接一个Softmax层,将输出转换为每个涨跌幅区间的概率,并以取得最大概率的区间为预测区间。在6分类下,最后的输出是6维,既6种涨跌幅区间的概率值。在3分类下,最后的输出是3维,既3种涨跌幅区间的概率值。在两种不同的分类下,都将概率取得最大的涨跌幅区间作为模型最终的预测区间。
LSTM预测模型如图2所示。模型在Softmax后是两种不同区间分类的网络输出。
本文使用有监督的方式对LSTM网络进行训练,既以T天的数据集作为输入,将式(3)和式(4)所示下一天较第T天的涨跌幅区间用Onehot编码处理后,作为标签输入到网络中。
为了优化网络权重,通常需要使用损失函数来估计预测值和标签的差异。本文使用交叉熵损失函数,定义如下:
(6)
其中,n表示训练样本数,
表示模型的预测样本j属于类别k的概率,
表示样本j的实际概率,如果样本j属于k,则取值为1,否则为0。
预测值和标签值越接近,则损失函数的值就越小。因此需要通过反向传播来不断更新模型的权重值,使损失函数不断减小,让模型不断地学习数据特征。
在实际参数优化上,本文选用收敛速度较快、适应性较好的Adam算法 [15] 对损失函数进行优化。
3. 实验与结果
3.1. 数据集描述
本文所采用的数据集分为两个部分,一部分是从沪深300股票集中选取在2013年到2017年之间有连续交易数据的160只股票作为整体股票的数据集1,选取上市的在16只银行股票作为类别股的数集2,上市的14只证券类股票作为类别股的数集3。
数据集的基本信息如表1所示。
数据集包含了从2013年到2017年的股票基本交易信息,由于有的股票会在正常交易日出现停盘的情况,因此需要对停盘日期的数据填充,本文使用的方式是用停盘交易日前一天的数据来填充该日的交易信息。在处理后的股票数据集中,每个交易日都包含了开盘价、收盘价、涨跌幅等信息。表2是部分数据集信息。
由表2可知,成交量和其他几个特征在数值上有很大的差异,因此在数据集送入到LSTM网络之前,还需要对其做归一化处理,以降低不同特征之间的数值差异,减免奇异样本在优化时对梯度方向的影响。

Table 2. Partial data set information
表2. 部分数据集信息
为了进一步了解数据特征,本文对三个股票数据集根据其涨跌幅做了样本统计。
图3、图4和图5分别是沪深300整体类、证券类和银行类在2013~2015年期间的股票集价格涨跌幅分布图。由图可知,三种类型的股票价格涨跌幅分布都近似于高斯分布,其中整体类和证券类的股票都存在部分涨跌停的股票,而银行类则出现的较少,这说明整体类和证券类的股票出现。

Figure 3. Shanghai and Shenzhen 300 overall stocks up and down distribution map
图3. 沪深300整体类股票涨跌幅分布图

Figure 4. Securities stocks up and down distribution map
图4. 证券类股票涨跌幅分布图
动荡的样本数较多,其价格涨跌幅变化更为复杂,预测难度也更大。除此之外,三类股票集的涨跌幅众数都向零点右侧偏移,这说明在这五年期间,沪深300股票市场整体体量有所增长。
在涨跌幅3分类下的数据占比直方图如图6所示,由图可知3种分类情况下数据分布基本均衡,不涨不跌类别的数据所占比例稍多于其他两类。
3.2. 实验结果
为了检验不同数据集训练的模型对股票的预测效果,本文用数据集1、2和3分别训练对应模型,为了评测训练效果,将数据集划分为训练集、验证集和测试集。对于每只股票,以整体数据的前80% (2013年~2016年)作为训练集,剩余20%作为测试集。训练集用于训练调节LSTM网络参数,测试集用于评测效果。在训练集里,又以8比2的比例分割训练集和验证集。验证集数据用于判断模型收敛时的迭代次数,避免过拟合。本文使用分类准确率作为判断模型优劣的标准。

Figure 5. Bank stocks up and down distribution map
图5. 银行类股票涨跌幅分布图
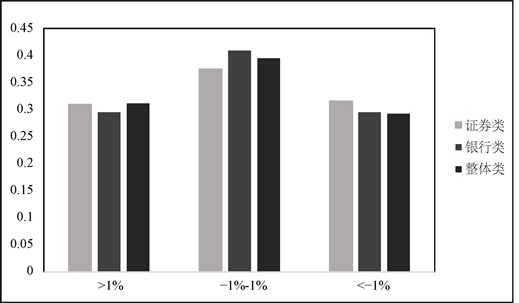
Figure 6. 3 kinds of classification data distribution map
图6. 3种分类数据分布图
本文开始设定的隐藏层节点数为128,学习率是0.01,训练迭代次数为150次。使用沪深300的160只股票训练的模型记为M1,用银行类的16只股票训练的模型记为M2,用证券类的14只股票训练的模型记为M3。在训练过程中,通过验证集的损失函数值变换情况来判断模型是否收敛。图7、图8和图9分别表示的是M1、M2和M3模型迭代150次时训练集和验证集损失函数值随迭代次数的变化情况。
由图7和图9可知,M1和M3模型在迭代了100次左右时就已收敛,由图8可知,M2模型在迭代了80次左右收敛,在此之后的迭代训练过程中,三种模型虽然训练集的损失函数值仍在下降,但验证集的损失函数值开始振荡,说明模型出现了过拟合。
因此用测试集对模型测试时,选择各自损失函数最小时的检查点模型。三种模型在不同测试集数据上的结果如表3所示。
Table 3. 6 classification accuracy in different model
表3. 不同模型6分类准确率
由表3可知,三种数据集的准确率都好于6分类随机预测的结果,这说明模型学习到了一定量的股票价格波动规律。其中,银行类的预测准确率高于其他两类,这是由于银行类的大盘股占比高,相对其他类型的股票,受非股票本身因素波动的影响较小。在同一数据集不同模型的表现效果上,M2模型在银行类测试集上的表现优于M1模型,M3模型在证券类测试集上的表现也优于M1模型。这说明对特定类别的股票预测时,选择该领域的股票数据进行训练,预测效果要好于用整体股票信息训练。
为了进一步评估模型的性能及更好的为投资者提供有用信息,本文还用了大涨、大跌和不涨不跌3分类的模型进行评估,表4是不同模型在三个数据集上3分类的准确率。
Table 4. 3 classification accuracy in different model
表4. 不同模型3分类准确率
由表4可以看出,3分类的准确率要比6分类的准确率高,这是因为数据分布不均衡,股票价格的涨跌主要集中在了不涨不跌这一类上,所以在把涨跌幅较小的数据合为一类时,模型的准确率有大幅提升。不同数据集上,银行类数据的准确率高于其他两类。除此之外,在3分类模型上,同样存在某一领域的股票预测上,选用该领域的训练集训练出的模型效果要好于用整体股票信息训练出的模型。
4. 总结
在预测股票价格涨跌幅上,本文提出了一种基于LSTM的多分类预测模型。用沪深300、银行类和证券类等多种数据集分别训练不同的模型,对比不同数据集上各模型在6分类和3分类情况下的预测效果。实验中发现,模型在6分类和3分类的股票涨跌幅预测上,均有比较好的效果。对特定类别的股票预测时,选择该领域的股票数据进行训练,预测效果要好于用整体股票信息的训练,最高时准确率可提升2%。在对涨跌情况三分类的预测中,最高准确率可达0.62。在今后的工作中,还可以根据预测任务的不同尝试使用不同的特征用于训练,探索股票的不同交易数据对于股票价格预测的影响。