1. 引言
SMP集群作为高性能计算系统成为目前应用最为广泛的高性能并行计算平台。并行程序设计模型通常可以分为共享内存和消息传递两类,MPI和OpenMP分别是这两类并行程序设计模型的代表,也是目前应用最为广泛的并行程序开发环境。MPI基于大粒度的进程级并行,通过消息传递实现进程间的数据交互和协同控制,具有扩展性强、便于移植等优点,但实现难度较大;OpenMP基于线程级细粒度并行,通过内存共享,使用显示指导语句,实现应用问题的并行求解,具有实现难度小的优点,但可扩展性差 [1] 。笔者在实际的科研和教学活动中发现,MPI并行编程环境在并行求解计算量小、通信量大的应用问题时常常表现出较差的可扩展性,这是由于随着进程规模的增加,并行计算部分花费的时间虽然逐渐减小,但进程间通信所花费的时间却在不断地增加,并逐渐在整个计算时间中占据主导地位。针对这个问题,本文结合SMP集群的体系结构特点,开展了基于MPI + OpenMP混合并行编程方法的研究,充分发挥MPI和OpenMP并行编程环境的优点,提高并行程序的效率,并对比分析了MPI与MPI + OpenMP混合程序的性能优劣,总结了造成性能差异的主要原因。
2. 并行编程模式
2.1. OpenMP (Open Multi-Processing)
OpenMP支持多线程并发编程和C、C++、FORTRAN等多种编程语言,是一种共享存储方式的并行编程标准,可在Linux、UNIX等操作系统中运行。OpenMP采用标准的Fork/Join式并行执行模型。OpenMP通过在代码中加入指导语句来控制代码的并行处理,实际并行过程由底层支持库来实现。OpenMP基本的结构包括:parallel、工作共享、master和同步、任务等结构,其中parallel结构是最基本的指导语句,所有的OpenMP程序都会用到 [1] [2] 。
2.2. MPI (Message Passing Interface)
MPI是由工业、科研和政府部门等联合建立的消息传递并行编程标准 [1] 。MPI凭借其标准化、可移植、可扩展等优点,成为目前最通用的并行编程标准。MPI1.0版于1994年发布,1998年MPI2.0版本发布,在MPI2.0中,共有287个调用接口。
2.3. MPI + OpenMP
MPI + OpenMP混合编程模型通过在节点内使用共享存储模型,节点外采用消息传递模型实现具体问题的多级并行求解。该模型将OpenMP和MPI模型有机融合到一起,通过充分发挥两种模型的各自的优点,从而获得更高的计算性能和可扩展性 [3] [4] [5] [6] 。具体来讲:节点外采用消息传递,解决了节点间OpenMP模型计算结果无法交互的问题;节点内采用共享存储,减少进程的数量,降低了进程通信所花费的时间。经测试,该模型对大规模循环问题的并行处理具有较高的并行效率和可扩展性。
3. MPI + OpenMP混合并行编程的实现
3.1. 算法设计
本文选用圆周率π数值积分并行求解算法来分析MPI + OpenMP混合编程的具体实现。π数值求解过程物理意义清晰,其计算规模灵活可调,虽然其并行实现过程虽相对简单,仍不失为用于并行程序计算性能测试分析的良好测例。
求解主要围绕着循环计算各部分梯形面积展开,其算法设计也主要针对循环过程的二级并行划分开展。具体如下:
(1) 节点间任务划分
采用均匀划分或交叉划分方法,将计算区间S划分为np个小区间
,若采用交叉划分,每个区间所含的循环次数尽量为节点内核心数的整数倍。
(2) 节点内任务划分
在每个计算节点内调用OpenMP for并行制导语句,将所分配的循环分配给不同的线程,期间需要调整每个线程分配的循环次数,尽可能做到负载均衡,求解流程如图1所示。
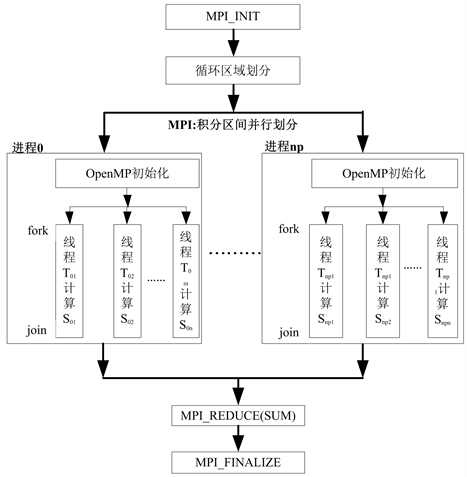
Figure 1. MPI + OPenMP hybrid parallel computation flow of π numerical calculation
图1. π值MPI + OpenMP混合并行求解流程图
3.2. 算法实现
算法的具体实现过程分为以下几步:
(1) 设定线程数
根据计算节点CPU配置,指定每个节点内部的线程数,本文中为24个。
(2) 计算区间划分(第一级并行MPI)
采用均匀划分方法,将循环分配给不同的进程(第一级并行处理)。如下所示:
n=N/np;//N为总循环次数,np为进程数
for (i=myid*n;i
{
#pragma omp parallel private(tid)
{
第二级并行;
}
}
(3)计算任务划分(第二级并行OpenMP)
调用OpenMP for并行制导语句,将分配的计算区间内的计算任务分配给不同的线程(第二级并行处理)。如下所示:
#pragma omp parallel private(tid)
{
tid=omp_get_thread_num();
#pragma omp for
for(j=0;j
{
;
;
}
}
(4) 数据收集和输出
每个节点分配的计算任务完成后,调用MPI_REDUCE(),将计算结果收集到进程0,并将计算结果输出。
4. 性能测试和分析
4.1. 测试环境
本文利用SMP集群对程序进行了测试,该集群共314个计算节点,节点内2颗Intel Xeon E5-2680 v3 12核CPU,集群理论峰值计算能力310TFlops,Linback实测计算能力210TFlops。
4.2. 测试结果
测试分为节点内测试、节点间测试两部分,节点内测试主要开展节点内MPI、OpenMP并行程序性能测试,节点间测试主要用于开展跨节点MPI、MPI + OpenMP并行程序性能测试。
4.2.1.
节点内测试
表1给出了使用一个计算节点,分别用3、6、12、24个线程/进程运行OpenMP、MPI并行计算程序时间统计情况(每种情况运行10次,取计算时间最小值,积分次数N = 100,000,000,000)。图2为表1对应的加速比。

Table 1. Parallel computing time of MPI and OpenMP parallel program
表1. 节点内OpenMP、MPI并行程序计算时间
从表1和图2可以看出,单节点内OpenMP与MPI并行程序性能基本一致,都具有比较高的并行加速比,OpenMP并行程序计算性能略高。
4.2.2.
节点间测试
表2给出了分别用1、2、4、8、16、32个节点运行π值MPI、MPI + OpenMP并行程序计算运行时间统计情况(积分次数N = 100,000,000,000)。其中:MPI程序每个节点分配24个进程,MPI + OpenMP每个节点分配1个进程,24个线程。对于MPI + OpenMP程序,核心数 = 节点数 * 单节点核心数;MPI程序,核心数 = 进程数。图3为表2对应的加速比。
Table 2. Parallel computing time of MPI + OpenMP and MPI parallel program
表2. 节点间MPI + OpenMP、MPI并行程序计算时间
从表2、图4可以看出,MPI + OpenMP和MPI程序加速比均呈现先增加后减小的趋势,但MPI + OpenMP程序的加速比随计算规模的增加基本保持稳定,且高于MPI程序近4倍。因此,与MPI并行程序相比,MPI + OpenMP并行程序具有更快的计算速度和更好的可扩展性。
为了进一步分析两种并行程序计算性能差异的原因,对MPI + OpenMP和MPI并行程序执行过程中时间的分布按照:并行计算时间、通信时间两部分进行统计,表3、表4分别给出了MPI和MPI + OpenMP并行程序执行过程中不同部分消耗时间的统计表。图4、图5分别为表3、表4对应的时间分布表。
Table 3. Parallel computing distribute time of MPI parallel program
表3. MPI并行程序计算时间分配表
从表3可以看出,随着计算规模的增加,MPI程序并行计算部分花费时间由11.95 s减少为0.64 s,降低近19倍,占总计算时间的百分比由91.0%减小为8.6%;进程间通信消耗的时间由1.09 s增加至6.77 s,提高6.2倍,占总计算时间的9.0%提高至91.4%。进程间通信开销远高于并行计算所花费的时间,极大的制约了并行效率的提高。
Table 4. Parallel computing distribute time of MPI + OpenMP parallel program
表4. MPI + OpenMP并行程序计算时间分配
从表4可以看出,在同样的计算规模下,MPI + OpenMP程序并行部分计算花费时间由11.92 s减少为1.27秒,占总计算时间的百分比由99.7%减少为73.4%;进程通信部分消耗的时间由0.04 s增加为0.46 s,占总计算时间的百分比由0.3%提高至26.6%。采用MPI + OpenMP混合并行程序方法,有效降低了进程间通信的时间开销,大大提高了程序的并行执行效率和可扩展性。
从表3、表4和图4、图5可以见,随着进程数的增加,MPI + OpenMP两种并行编程方式下,应用问题并行部分的计算时间均逐渐减小,但MPI + OpenMP并行程序的通信消耗时间只占MPI并行程序的6.8%。由此可见,MPI + OpenMP混合并行程序在很好地继承了两种并行编程环境的优点的同时,可以有效克服两种并行编程环境的缺点,可以有效提高并行程序的效率。
5. 结束语
MPI + OpenMP混合编程模型通过节点间消息传递,节点内数据共享的方式,将分布式存储系统和共享式存储系统的优点互相结合,既能解决MPI并行程序性能随进程数增加而降低的问题,同时又克服了OpenMP并行程序扩展性差的问题,可有效地发挥SMP集群的计算性能。并行程序的性能受并行机体系结构、编程环境、问题自身结构、并行程序的优化、编程人员的习惯等多重因素制约,很难给出统一的编程和性能评价标准,需结合具体的应用问题,合理地采取编程和优化方式,系统地进行设计。
基金项目
本文基金资助项目为国防科技创新特区项目(18-H863-05-ZT-
001-012-06)
;水中军用目标特性国防科技重点实验室基金(614240704040317)。