1. 引言
随着Facebook、Twitter、微博等社交媒体或平台的出现,信息量急速增长,用户在海量信息中很难找到真正中意的商品。与此同时,在现实社会化商务平台中常出现“诈骗用户”、“广告用户”等一系列恶意用户,然而,在已有的社会化信任推荐研究中,通常直接将社交关注关系表达为社会化信任关系,但是并非存在社交关注关系就代表用户值得信任。其次,在庞大的社会化网络中,社交关注数据同样会出现极度稀疏的情况,这将导致构造出的社会化信任关系过少。
在社会化商务环境下,用户频繁的社交行为和交易活动产生了丰富的社交数据。用户在社交上的关注关系能在一定程度上反映了用户之间的社会化信任关系。基于这种社会化关系进行推荐,不但能缓解数据稀疏性对传统推荐方法造成的影响,同时也将更加符合社会化商务的口碑营销、信任建议、好友推荐购买等特征。已经有相当多的学者通过使用社会网络来提高推荐系统的准确性 [1] [2] [3] [4] 。而这类推荐系统的研究一般都是基于其属于的信任网络 [5] [6] [7] ,用户获得的推荐也往往是来自于信任网络中与之距离较近的用户 [8] [9] [10] 。
因此,本文提出基于社会化信任改进的协同过滤推荐方法,对社交关注数据进一步进行挖掘和利用,进一步缓解传统协同过滤算法的数据稀疏性问题,最终提高推荐效果。
2. 研究现状
2.1. 国外研究现状
Massa等 [11] 首次提出了基于信任的推荐系统框架,他通过将项目评分矩阵和信任关系矩阵作为系统算法的输入项并提供给评分预测模型,最终得到了预测评分矩阵,改善了传统算法数据稀疏性问题,但其采用的是未加处理的布尔型信任标注值,表达信任的能力较弱,而且由此得到的信任关系也难以抵御恶意用户的攻击。Golbeck提出了一种TidialTrust算法,该算法通过广度优先搜索(BFS)的方法对信任传播方式进行了挖掘 [11] 。Massa等 [3] 在后来对TidialTrust进一步改进,提出了一种设定最大信任传递距离的MoleTrust算法。Zarghami等 [12] 提出了一种衡量信任程度的T指数,同时引入了信任传递机制,提高了推荐的精度和覆盖率。Jamali等 [13] 将基于项目的协同过滤推荐方法与信任推荐方法相结合,提出了TrustWalker随机游走算法,该算法认为信任程度较高的邻居用户比信任程度低的邻居用户在与源用户相似的目标项目上的评分更可靠,由此对源用户的未评分目标项目进行预测评分。Chen等 [14] 在传统协同过滤算法的基础上引入了信任的传播机制,提出了TPCF信任推荐模型。Bedi等 [15] 提出了一种信任动态更新的协同过滤推荐算法,通过用户的评分相似度和共同评分数占比综合推出。
2.2. 国内研究现状
国内对信任推荐的相关研究中,出现较早的是唐文等人提出的一种公开网络环境下的信任管理模型 [16] 。陈婷等 [17] 提出一种融合社交信息的推荐新方法Trust-PMF,融合由评分数据产生的相似度和由信任关系信息产生的信任度构建用户的偏好模型生成邻居,再综合目标用户自身的偏好和邻居用户对其评分的影响预测评分。潘一腾等 [18] 在社会化推荐算法SocialMF的基础上,提出一种基于信任关系隐含相似度的推荐算法,综合考虑了评分相似和信任关系隐含相似对每组用户之间信任度的影响,得到了更精确的信任度量和推荐模型。王瑞琴等 [19] 借鉴社会心理学中的信任产生原理,综合考虑多种信任要素在社交信任度量中的作用,提出一种基于多元社交信任的协同过滤推荐算法CF-CRIS。王占等 [20] 提出基于信任与用户兴趣变化的协同过滤改进方法,该方法将信任引入到传统协同过滤算法中,构建用户信任模型,用信任的传递特性为用户匹配更多邻居用户,从而可以在一定程度上缓解数据稀疏性等问题。吴应良等 [21] 提出基于社会网络分析的协同过滤推荐算法,利用网络中存在的信任关系健壮原先的推荐技术,新算法的核心是利用用户间邻接矩阵得到直接信任关系,进一步应用凝聚子群分析方法,根据成员间的可达性和捷径距离找出子群成员得到间接信任关系,摆脱单纯依赖直接信任关系,形成用户综合信任网络,并融入到协同过滤算法中。杜巍等 [22] 提出基于个性化情景的移动商务信任推荐模型,该模型首先通过挖掘训练集为每个用户找出对其信息需求影响最大的K个情景要素,在此基础上融合社会网络与信任机制,分别构建基于个性化情景的移动商务富信任信息推荐模型及基于个性化情景的移动商务稀疏信任信息推荐模型。陈梅梅等 [23] 提出一种基于标签簇的多构面信任关系定义的方法,在标签聚类得到的标签簇基础上,引用TF-IDF思想及Pearson相似度定义簇间和簇内信任关系,构建有利于反映不同构面信任强度的信任张量,并融入基于张量分解模型的个性化推荐算法中。薛福亮等 [24] 通过筛选信任用户作为相似用户,根据选择的信任用户和目标用户形成一个项目的评分集,并对目标用户未评价过的项目进行评分估算(根据信任用户评分进行简单的评分计算),将用户间的信任关系依据方差大小进行量化,形成一个调节因子,并将调节因子纳入用户相似性计算,形成相似性用户聚类簇,以在相似用户之间进行交叉推荐。
3. 基于可信评分的矩阵预处理
3.1. 可信评分计算
本文从用户社交属性中抽取了影响用户可信度的5种重要因子:点评数(Comment)、粉丝数(Fans)、关注数(Follow)、收藏数(Collection)和互粉数(Mutual-Fans)。选择这5种影响因子的原因在于它们具有通用性。本文可信评分的计算将由个人可信度评分和互鉴可信度评分两部分组成。可信评分的构成,如图1所示。
Figure 1. The impact factor of user credibility score
图1. 用户可信评分影响因子
1) 个人可信度评分的计算
个人可信度(Personal Reliability, PR)用以衡量推荐系统中社交用户的可信赖程度,由点评数,粉丝数,关注数,收藏数以及互粉数的可信度得分共同计算得出。
① 点评数可信度得分
点评数(Comment, FS)是衡量用户在推荐系统中参与活跃程度的一种重要影响因子。假设不存在恶意评论行为的情况下,用户点评数较多意味着用户参与度高,所以相对于点评数较少甚至几乎不参与点评的用户显得更为忠诚和可信。用户u的点评数可信度得分的具体计算如公式(1)所示:
(1)
其中,
表示用户u个人的点评数得分,而
表示用户u的点评数。通常情况下,双向的关注关系比单向关注更具有可靠性和研究价值 [25] ,所以本章的五种影响因子中引入了用户u的互粉数
与粉丝数
之比,即互粉比例
,用以强调用户在互粉数影响因子上的重要性。
代表点评数的相对影响力,用以强调用户u相对于用户v的点评数影响程度。相对影响力越大,则说明用户v越具影响力,即用户v更值得用户u信任,否则反之。
表示除用户u以外的k个用户对项目的点评数,用户v属于这k个用户集合,后续四种影响因子得分与此同理,不再复述。ε1代表点评数阻尼系数,具体计算公式在后续给出。
同理,我们可以相似得出粉丝可信度评分、关注数可信度评分、收藏数可信度评分以及互粉数可信度评分,其计算公式分别如下所示:
② 粉丝数可信度得分
(2)
③ 关注数可信度得分
(3)
④ 收藏数可信度得分
(4)
⑤ 互粉数可信度得分
(5)
本章的阻尼系数与PageRank算法中的阻尼系数并不相同,它可随机地由指定用户v的可信度评分除以评分集合中k个用户评分的最大值计算得出,其随机性体现在结果并不是一个固定值,而是随着不同目标用户的不同可信度评分进行变动的数值,由此计算出来的影响因子更具合理性。上述5个影响因子的计算公式中,权重值皆可利用用户各项指标在所有用户中的占比随机计算得出。为了让计算出来的结果限定在0到1的范围内,5种阻尼系数
的取值范围也在0到1之间,见公式(6)所示:
(6)
通过上述的公式(1)~(5)分别计算出每一位用户的各项影响因子后,将它们加总求和可以得到依据用户自身属性的可信评分,如公式(7)所示:
(7)
2)互鉴可信度评分的计算
互鉴可信度(Mutual Identify Reliability, MI)是指相互鉴别后的可信度,即目标用户的可信度评分由其他用户的可信度相互鉴别后计算得出。
引入互鉴可信度的原因在于:在社会化商务环境下的推荐系统中,常常出现用户或商家恶意“刷分”的情况,系统中的用户同样也可能会为了追求特殊“信誉”和“地位”而疯狂地对自身社交属性进行“刷分”,由此可能会导致个人可信度评分虚高的情况。
为了使用户可信度评判过程更加公平公正,本章以用户的互鉴可信度评分作为用户最终的可信得分评判指标。互鉴可信度评分的计算如公式(8)所示:
(8)
其中,
表示阻尼系数,计算方法与其他阻尼系数相似。
3.2. 社交关注矩阵可信量化
在社交关注矩阵中,如果用户A关注用户B则将TA,B标注为1,否则标注为0,但是在社会化商务中,关注并不意味着信任,每一位用户在系统中的自身属性和行为中间隐含着一些属于自己的可信赖信息,并可以传达给其他用户。如果能在用户社交关注关系中引入目标用户的可信赖程度,则可以构造出可能反映源用户对目标用户预期可信程度较高的信任关系矩阵。
对于这种可信赖程度的衡量,本章已对用户社交信息中的五种重要影响因子进行了提取并评估得出了互鉴可信度评分,可将其作为目标用户的可信赖程度衡量指标,如表1所示。此时,用户之间的信任度值由原先的0和1二值细分量化为[0, 1]区间中的值,由此更加细致地表达用户之间更加可信的社会化信任关系,有利于提高后续算法的推荐质量。

Table 1. A social attention matrix based on mutual trust
表1. 互鉴可信度的社交关注矩阵
3.3. 项目评分矩阵预填充
传统协同过滤算法中存在数据稀疏性问题,本文基于评分矩阵预填充的思想来缓解数据稀疏性问题,利用上文得到的可信评分模型来对稀疏的评分矩阵进行预填充:首先,需要根据用户集中的任意两位用户之间的互鉴可信评分MI和公共评分项目PI建立起用户两两之间的预估可信度(Forecast Reliability, FR)。在建立互信度的过程中,源用户通常会向目标用户进行咨询,如果目标用户的反馈(项目评分)与自己预期大体相同或偏差较小时,该目标用户的反馈建议可视作有效且会被采纳,否则反之。通过计算两位用户之间评分差距较小的项目集合数(Undifferentiated Item, UI)占公共评分项目总数的(Public Item, PI)比例计算得到预估可信度FR可由公式(9)计算出:
(9)
其中,
表示
中用户评分差距小的项目集合。对于任意
,若用户u对项目i的评分
满足
,则
。
表示用户u对项目i评分预测函数,由公式(10)计算:
(10)
然后,根据预估可信度FR的大小进行降序排序,选取排名前20且评分不为0的用户作为目标用户u的可信邻居集RNu。下一步,根据RNu中用户的评分,对目标用户u尚未评分项目进行评分预测,预测评分的计算如公式(11)所示:
(11)
最后,将
填充到初始评分矩阵的相应位置,直到未评分项目的预测评分填充完毕,由此构造出了能提高初始评分矩阵数据密度的可信评分预估矩阵。
4. 基于可信评分预估矩阵的相似性计算
4.1. 用户相似性计算
传统的用户相似性度量可由传统的相关相似性算法计算得出,如公式(12)所示:
(12)
其中
和
分别表示用户u和用户v对共同评分项目k的评分,
和
分别表示用户u和用户v已有评分项目的平均评分。为了将结果限定在[0, 1]范围内,需要归一化处理,如公式(13)所示:
(13)
4.2. 预测评分计算
对于预测评分的计算,本章算法采用传统协同过滤算法评分预测公式,如公式(14)所示:
(14)
其中,
和
分别表示用户u和v的评分均值,
和
分别表示与用户u相似的Top-N相似邻居集和对项目i存在评分的用户集。
5. 算法实施步骤
图2展示了基于社会化关系与信任传播的协同过滤算法的算法步骤,具体步骤如下:
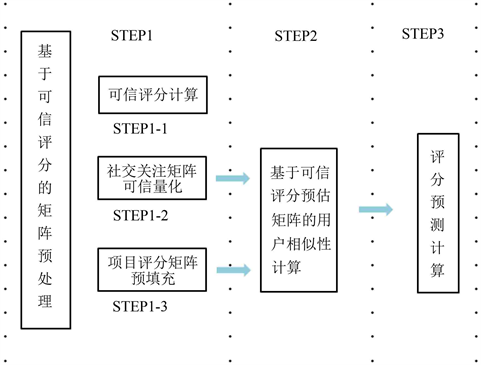
Figure 2. The implementation step diagram of the algorithm in this paper
图2. 本文算法实施步骤图
STEP1-1可信评分的计算:根据推荐系统的用户数据库中,提取用户的点评数,关注数,粉丝数,收藏数,利用公式(1)至公式(7)离线计算每一位用户的五种影响因子得分和个人可信度评分,再利用公式(8)计算出每一位用户的互鉴可信度评分。
STEP1-2社交关注矩阵可信量化:将STEP1-1中计算出来的互鉴可信度融入到初始社交关注关系矩阵中,如表1所示,得到改善可信水平后的社会化信任矩阵。
STEP1-3项目评分矩阵预填充:将STEP1-1输出的互鉴可信度利用公式(9)至公式(11),先转化为预估可信度后对用户未评分项目进行评分预测,并补充到初始用户项目评分矩阵的相应位置,最后得到数据密度改善的用户项目评分矩阵。
STEP2基于信任传播的相似性计算:基于STEP1-3填充后的项目评分矩阵,利用公式(12)至公式(13)计算相似度矩阵。
STEP3预测评分计算:根据公式(14)对用户的评分进行预测,将预测评分按照降序排序后形成推荐列表,位于前列的是目标用户最可能乐意接受的项目,以此进行实时的在线推荐。
6. 实验及结果分析
6.1. 实验数据集和评估标准
大众点评是国内领先的Web2.0生活信息交易平台(http://www.dianping.com/),是最早在全球建立的第三方消费购物点评网站之一。大众点评具备虚拟社交社区,社区中的用户具有丰富可挖掘的用户属性,信任数据和项目评分数据,非常适用于本章的信任推荐研究。在使用八爪鱼软件采集后,本文对部分空值和重复数据进行处理,并统计出每一位用户的项目评分数量和关注其他用户的数量以及每一种项目被用户评分的数量列表,作为算法各部分的输入项。
大众点评数据集的特征统计如表2所示。可以看出,数据集的评分和信任数据都相当稀疏。为了让实验更具可靠性,将预处理后的数据集分别分成五组在实验中进行交叉验证,每组数据均随机划分为80%训练集用以构造本章推荐模型和20%测试集,最终结果取五组数据集的平均值,用以检验模型的性能。评价推荐算法的优劣程度可以由很多指标来评价。为了比较提出的算法,本文选择平均绝对误差MAE、准确率Precision、召回率Recall以及综合评价指标F值作为其评价指标。
Table 2. Characteristic statistics of experimental data set
表2. 实验数据集特征统计
6.2. 实验结果讨论
1) 可信评分影响因子充分合理性验证
在可信评分计算中,影响因子得分引入的充分与否会通过影响用户可信评分,进而影响算法推荐的效果。所以,需要对引入的五种影响因子充分性与合理性进行验证。在大众点评数据集上,测试缺失任意一种影响因子对MAE值的影响,最后MAE值取五个训练数据分组集计算的平均结果,如表3所示。
从表3可以看出,五种影响因子得分中的任意四种结合效果都没有全部包含的精度高。互粉数和点评数的缺失对算法推荐效果的影响较大。
2) 社交关注和评分矩阵处理影响验证
Table 3. Calculating MAE results with different influence factors of credible score
表3. 不同可信评分影响因子下MAE的计算结果
本章在基于可信评分的矩阵处理步骤中,不仅对社交关注矩阵进行了可信量化,还对评分矩阵进行了预填充,因此需要对这两部分对算法推荐效果的影响进行检验。
MAE值取五个训练数据分组集计算的平均结果。测试分为三种情况:
① 未可信量化社交关注矩阵但预填充评分矩阵(No-Process-Trust);
② 未预填充评分矩阵但可信量化社交关注矩阵(No-Filling-Rating);
③ 既量化社交关注矩阵又预填充评分矩阵(Process-Trust-Rating)。
如图3所示,推荐精度最高的是本章即量化处理信任数据又预填充评分矩阵的情况 (Process-Trust-Rating),其次是(No-Process-Trust),最低的是(No-Filling-Rating)。可见,如果在仅提高信任数据的可信水平而未预填充评分数据的情况下,推荐效果并不可观。同样,如果仅预填充了评分数据而未对社交关注矩阵量化处理的情况下,推荐效果虽有提升,但是效果并不突出。由此说明,本章基于可信评分对社交矩阵的量化计算和对评分矩阵的预填充的处理步骤能使推荐效果更加显著。
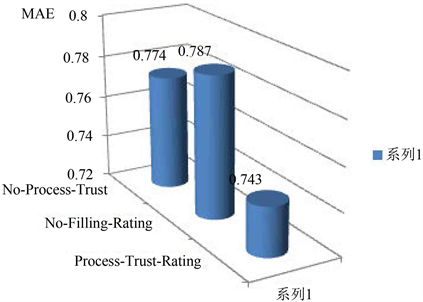
Figure 3. The impact of social attention and score matrix processing on MAE
图3. 社交关注和评分矩阵处理对MAE的影响
7. 结论及展望
已有研究表明,用户之间的信任关系对改善推荐系统的推荐效果起到不可忽视的作用。在社会化商务环境下,通过社交数据反映出的社会化关系进行推荐,不但能提高传统推荐方法的推荐效果,同时也将更加符合社会化商务的口碑营销、信任建议等特征。因此,本文通过充分挖掘社会化商务环境下的用户社交和项目评分数据,计算用户可信评分,然后基于可信评分对社交矩阵进行量化计算以及对评分矩阵进行预填充,从而提高了推荐效果。
在下一步工作中,值得我们进一步研究是:根据信任的动态特性,考虑构造一种附带时间因素的效用函数,对信任网络中的用户节点接受推荐后的效用情况进行反馈,从而模拟此信任变化过程,进一步提高推荐算法的抗恶意用户攻击性能。
基金项目
国家自然科学基金项目“管理科学理论和方法的综合集成研究”(70440011),国家社会科学基金项目“分享经济下基于TRIZ理论的网络约租车服务创新研究”(16BGL190),国家社会科学基金项目“基于关联数据的政府数据开放研究”(14BTQ009)。