1. 引言
互联网的快速发展与传播,使人们体会到了数据的庞大和资源的丰富。面对如此巨大的数据资源,如何从众多数据中发现隐藏的,对我们研究分析有用的数据信息,成为了一大难题。合理的分析毕业生资源总量、层次、专业结构,运用可视化技术对海量异构研究数据进行科学文献分析,如科学知识图谱、学科知识地图、科学知识网络(或学科知识网络、领域知识网络)等 [1] ,得出科学的预测模型,为高校教育的工作者要开拓思路,转变高校毕业生就业观念,提高就业竞争力。我们的研究就是运用可视化从数据集中将需要的数据呈现在人们眼前。毕业生需求状况可视化分析与预测研究具有重要意义。
2. 研究概述
本设计系统分为收集数据、分析呈现数据和可视化分析预测三部分。
2.1. 收集数据
通过Excel收集毕业生信息和企业需求信息。
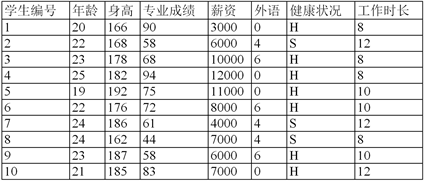
Figure 1. Information thumbnails for graduates
图1. 毕业生信息缩略图
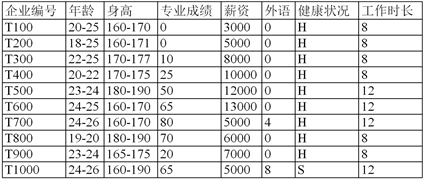
Figure 2. Thumbnail of enterprise demand information
图2. 企业需求信息缩略图
2.2. 分析呈现数据
本文使用的数据来源是名为“student”的excel文件中的“源数据” [2] 。图1、图2为缩略图,企业需求数据一共100行,九个属性,毕业生信息共100行,12个属性。
首先对源数据进行预处理,清除掉一些无关事项,在本次数据中包含属性,身高、健康状况。
数据预处理的第二步:使用dm = xlsread('shen');导入“student”.xls文件,在Matlab中对一些连续数据离散化。
如下:
1、[18,20]1,[21,23]=2,[24,26]=3
2、[0,33]=1,[34,66]=2,[67,100]=3
3、[0,3000]=1,[3000,4500]=2,[4500,6000]=3
4、[0]=1,[4]=2,[8]=3
5、[0,8]=1,[8,10]=2,[10,12]=3
生成以下图表:
然后对不同数据的相同数据进行整合:
由于不同属性之间的属性值存在相同情况,所以利用下面语句对一共2个条件属性中的100个数据进行如下赋值,使每条属性唯一确定。从而得到个200唯一数据,只不过200个里面有且只能出现100个。
程序如下:

从而得到dm(3)矩阵。而且决策属性分为1:专业成绩;2:工作时长
2.3. 可视化分析预测
Apriori算法 [3] 是常用的用于挖掘出数据关联规则的算法,它用来找出数据值中频繁出现的数据集合,找出这些集合的模式有助于我们做一些决策。常用的频繁项集的评估标准有支持度,置信度和提升度三个。
支持度就是几个关联的数据在数据集中出现的次数占总数据集的比重。或者说几个数据关联出现的概率。如果我们有两个想分析关联性的数据X和Y,则对应的支持度为:
(1)
以此类推,如果我们有三个想分析关联性的数据X,Y和Z,则对应的支持度为:
(2)
一般来说,支持度高的数据不一定构成频繁项集,但是支持度太低的数据肯定不构成频繁项集。
置信度体现了一个数据出现后,另一个数据出现的概率,或者说数据的条件概率。如果我们有两个想分析关联性的数据X和Y,X对Y的置信度为:
(3)
也可以以此类推到多个数据的关联置信度,比如对于三个数据X,Y,Z,则X对于Y和Z的置信度为:
(4)
在毕业生需求数据中,通信工程专业对应电子类专业的置信度为40%,支持度为1%。则意味着在电子行业数据中,总共有1%的用人单位既需要通信工程专业的人才又需要电子类专业的人才;同时需要电子类专业人才的用人单位中有40%的用人单位需要通信工程专业学生。
提升度表示含有Y的条件下,同时含有X的概率,与X总体发生的概率之比,即:
(5)
提升度体先了X和Y之间的关联关系,提升度大于1则XÜY是有效的强关联规则,提升度小于等于1则XÜY是无效的强关联规则。一个特殊的情况,如果X和Y独立,则有Lift(XÜY)=1,因为此时P(X|Y)=P(X)。
一般来说,要选择一个数据集合中的频繁数据集,则需要自定义评估标准 [4] 。最常用的评估标准是用自定义的支持度,或者是自定义支持度和置信度的一个组合。
运行Apriori算法实现关联规则,需要借助JAVA程序,编写程序后进入关联规则主界面,如图3所示。
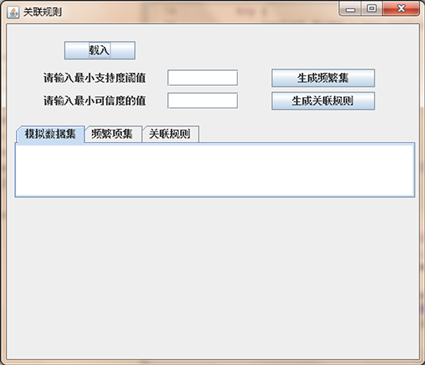
Figure 3. Main interface of association rules
图3. 关联规则主界面
3. 结束语
本次分析用的数据主要有两方面:毕业生基本信息和招聘企业基本信息和需求数据,对毕业生信息使用Apriori算法时,每个毕业生作为一个项集,这里项集的特征是每个项集包含的item个数是一样的,而item是所有毕业生属性的所有情况的集合。
利用Apriori算法,以5%为支持度阈值得到毕业生信息的频繁项集及其支持度为:
再对上述频繁项集进行关联规则处理得到以下置信度60%以上的规则(已经经过规则合并):
985高校,六级,农村 7~10 k,一线城市
985高校,六级,城市 5~7 k,二线城市
普通一本高校,文史专业,四级 3~5 k,一线城市
二本高校,理工专业 3~5 k,二线城市
经过分析,可以得到,以下结论:
1) 985高校毕业生对薪资要求较高,更倾向于一线城市
2) 专业不是影响就业的主要因素
3) 城市生源的毕业生倾向于二线城市,对薪资最低接受限度较低
对企业信息进行类似处理,得到以下置信度60%以上的规则 [5] (已经过合并):
一线城市,世界五百强,10 k+ 985高校,六级
海外城市,世界五百强,7~10 k 985高校,六级
二线城市,普通国企,5~10 k 211高校,四级
一线城市,普通私企,5~10 k 211高校
经过分析,可以得到以下结论:
1) 五百强企业主要分布在一线及海外城市,且工资普遍较高。最看重毕业生的条件是毕业院校和外语水平,要求偏高。
2) 国企和私企大多分布在二线和一线城市,对毕业生的要求院校依旧偏高,但不高于五百强企业,对外语水平的要求比较宽松。
3) 家庭条件不是影响就业的主要因素。
结合两者分析,可得:
1) 毕业生和企业在高校、外语等方面的供需关系是比较平衡的。
2) 毕业生和企业在薪资方面有一定矛盾。毕业生需求较高,企业提供的较低。
基金项目
2018年度河南省大中专院校就业创业研究立项课题JYB2018074。
参考文献