1. 研究的主要问题
利用参考文献给出的商业银行的大量数据用主层次分析法,多元线性拟合等方法来建立不同的模型求解问题。
在问题1中,首先,用相关系数和标幺值来探求各省分行的盈利与全国总盈利的相关度和之前年份各种影响宏观经济总的因素的变化趋势,其次,运用主成分分析方法来得到影响宏观经济总量较为重要的主成分,即GDP、CPI以及工业同比增加量(季)。再利用多元线性回归来得到主成分与存款总量之间的关系,最终,拟合出下一年的存款总量。在不考虑备付水平的情况下,存款总量减去法定准备金量即为贷款总量。
在问题2中,引入净差率来描述银行的盈利,我们在第二个模型里用加权的净差来描述最大收益;当我的净差达到最大时,每个省市的资金分配就是最优解,我们从此角度来计算出合理的分配方案。
在问题3中,引入了外部评价因子GDP同比增长影响因子;通过外部影响因子和净差来调配目标函数的权重;通过外部因素的影响我们可以观察到GDP的同比增长无法影响全局的贷款分配;但对于GDP增长比较快的城市,有着明显的影响;比如重庆,贵州。
在问题4中,为了保证每日交易的正常进行,各个分行要预留一定的备付金额来维持银行的正常运转,但备付金额不能太多以至于减少银行的利润,通过各分行每日的存取款金额之差拟合出正态分布曲线模型,并在置信度99%的条件下计算出置信区间,来得出各个分行应预留的最少备付金额。
在问题5中,考虑到由于实际中影响商业银行的贷款投放量有很多因素,主要探讨了不良贷款率,国际政策导向以及地区差异受国家政策影响的情况。最后得出减少不良贷款率高地区的贷款投放,提高国际政策导向地区以及国家政策扶持地区的贷款投放量。
2. 问题重述
商业银行的主要业务范围是吸收公共存款、发放贷款以及办理票据贴现等。贷款的投放是否合理直接决定了商业银行的经营运作能力。其贷款投放的简单模型是:从客户端吸收存款,缴存法定准备金,预留一定比例备付水平,剩余资金用于贷款投放或其他资产配置。而对于大多商业银行而言,贷款规模的大小通常是由存款规模来决定的,存款总量多了,才能有足够的资金进行贷款投放等一系列的商业活动。具体一般来说,商业银行在全国存款总额中所占比例相对稳定,一般不会发生大的变动。从宏观经济指标上来看,社会存款增长量受到与它有关因素的密切影响,例如GDP、CPI、工业增加值等。在贷款分配模式中,商业银行在之前使用了预分配和年度配额管理模型,即每年年初对全年所有部门的预分配一次发放,年度内不再增调。这种模式存在着效率低、弹性差、环境变化和需求变化等诸多弊端。目前,商业银行采用的是以存定贷、存贷结合、资产与负债动态平衡的模式。商业银行不仅要努力获得全行的最大利益,还要平衡各地区发展的差异,调动各单位的积极性,支持重大项目、关联政策和民生工程。支持实体经济的有效发展。因此,如何进行合理、有效的贷款投放也是一个非常具有现实意义的问题。请根据你所掌握的有关知识回答以下问题:
假设该银行除客户存款外无其他资金来源,且暂不考虑备付水平。请根据参考文献 [1] 商业银行A各项存贷款历史数据及参考文献 [2] 宏观经济指标历史数据,建立数学模型,预测该银行2018年存、贷款增量情况。
假设该银行除客户存款外无其他资金来源,且暂不考虑备付水平。请根据问题1预测的结果并结合参考文献 [3] 相关数据,建立数学模型,给出2018年商业银行A各分行贷款规模的分配方案,使得全行增量存贷款利息净收入最大,并将该分配方案填入表8。
若商业银行A将于2018年5月1日发行500亿规模的15年期商业银行普通债(利率约为5.1%),请结合该条件对问题2进一步优化,暂不考虑备付水平情况下,重新设计商业银行A各分行贷款规模的分配方案,使得全行增量存贷款利息净收入最大,并将该分配方案填入表8。
为保证每日交易正常进行,各家分行每日需预留一定的备付资金(备付资金不足易引起客户不满,严重的会引起社会恐慌,引发挤兑;预留资金过多,会降低银行盈利水平),以确保最低的备付水平(备付水平 = 备付资金 ÷ 存款余额)。假设每个客户存取款的行为是随机的,请根据参考文献 [4] 各分行2017年每日存取款交易数据,建立数学模型,计算在置信水平99%的情况下,2018年商业银行A各分行日常经营所需最低备付金额,并将结果填入表8。
在贷款规模分配问题上,为了帮助商业银行A处理好收益与风险、企业经营与国际政策导向,区域化差异与分行公平考核等之间的关系,以期达到双赢或多赢,请对以上模型进行改进,并给出相关建议。
3. 问题分析
3.1. 问题一的分析
假设该银行除客户存款外无其他资金来源,且暂不考虑备付水平,则该银行的贷款量即为存款量减去法定准备金量。所以首先要预测出2018年该银行的存款量。而存款量又跟宏观社会经济指标有着密切的关系,所以需要找到主要影响存款量的主要宏观社会经济指标。
我们先引入标幺值对各种宏观经济指标多年的数据进行分析,发现大多因素都较为稳定,也有少量因素波动较大无法判断哪些因素的影响更大。于是我们引入主成分分析方法经过数据处理得到主成分。再通过对这些主成分和之前存款总量的多元线函数拟合,最后带入计算出2018年的存款总量,再和存款趋势进行比较,评价模型。
3.2. 问题二的分析
我们引入净差率来描述银行的盈利,我们在第二个模型里用加权的净差来描述最大收益;当我的净差达到最大时,每个省市的资金分配就是我的最优解;在描述各省市的资金分配的上限和下限时,我们认为资金分配的上限应不大于三年内存款的最大值,资金分配的下限应不大于三年内贷款的最小值。
3.3. 问题三的分析
通过对模型2的分析我们知道净差越大地方资金的吞吐量越大那么这个地方的资金承受能力就越大,通过查找外部数据,对比了各个省市的GDP增速;通过GDP的增速排名和增速比例我们重新调整权重因子在原有贷款的基础上加上这笔钱重新进行分配,调整的原则依据于省市的GDP增速比例。我们认为一个省市的GDP增长越快,那么它对资金的需求就该越大,但由于省市的资金吞吐量并不能正比与它的GDP增长所以我们要综合地去考虑这个问题,我们通过对两个权重再次进行权重分配来调节,通过网络上大数据的查询,我们拟算对净差决定的权重因子取0.7,对GDP增长率决定的权重因子取0.3。
3.4. 问题四的分析
备付金是商业银行保护存款人利益,满足存款支付,确保资产流动性所做的准备。它包括库存现金和在人民银行备付金存款。备付金在商业银行资产项目中盈利性小,其管理原则是既要确保支付,又要尽量减少不必要的占用,既控制在正常需要的最低限。问题四要求根据每日用户的存取款来计算99%置信水平下,各分行日常经营所需的最低备付金额。
该问题要求我们建立一个综合分析,预测的模型,我们结合题中给出每日分行资金的进出情况,算出每日资金的净变化量,因为用户的存取款是随机行为,所以净变化量理想状态下应服从正态分布函数模型,经过MATLAB正态检验,得出净变化量大致服从正态分布的关系。因此,建立正态分布模型来计算净变化量在置信度99%条件下的置信区间,得出各分行最低的备付金额。
3.5. 问题五的分析
在实际的贷款规模分配问题上,除了要考虑使增量存贷款利息净收入最大之外,还要考虑某地区不良贷款规模、国际政策导向以及平衡区域化差异顺应相应国家政策等因素。只有在经过综合各种因素的条件下,才能在双赢或多赢的基础上实现利润最大化。
4. 模型假设
1) 假设附件中提供的数据符合一定客观规律,且较为准确。
2) 假设短时间内国家经济未收到大型外来冲击,各省份经济正常发展。
3) 假设在前三个问题中该商业银行存款中除法定准备金外的资金全部用于贷款。
4) 假设国家的相应政策不发生重大改变。
5) 假设该银行没有受到挤兑和其他银行或企业的冲击。
6) 假设一年中经济发展平稳,用户存取款波动不大,且是随机过程。
5. 符号说明
符号说明见表1。
6. 模型的建立与求解
6.1. 问题一的模型建立与求解
6.1.1. 建模的前期准备工作
1) 关于数据来源的说明
在参考文献 [2] 中给出了2010~2017年宏观经济指标的情况,在参考文献 [1] 中给出了各省份各项存贷款历史数据,在参考文献 [3] 中给出了各分行存贷款利率水平,所有数据均来源于相应的官方网站。
2) 建立评价指标
商业银行在全国存款总额中所占比例相对稳定,每年可增长的存款量受限于社会资金总量的增长情况。参考文献 [2] 中给出了各季度影响宏观经济总量即存款增量的相关指标,为了更加准确的得到各项相关指标对经济总量的影响情况并且希望利用较少的新变量代替原来较多的旧变量,同时这些新变量尽可能反应宏观经济总量的变化情况,故可以利用主成分分析方法筛选出主成分来简化问题 [2] 。
3) 标幺值预分析
由于影响存款量的因素的量纲不同,我们想要把他们放在一个图中考虑,所以引入标幺值的概念,假设以各因素2010到2017年各季度的加权平均值作为基准值,则可以在一个图里分析各因素的变化趋势。各因素的变化趋势分析见图1。
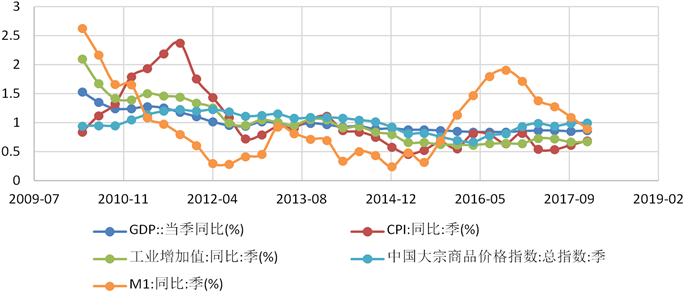
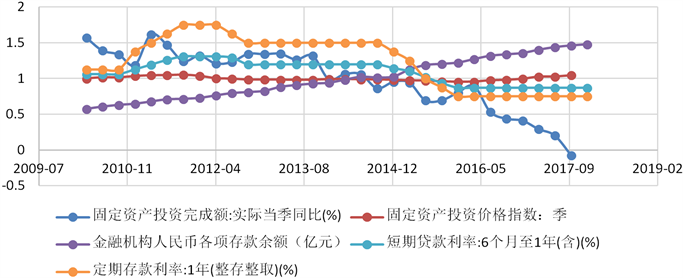
Figure 1. Analyzes the variation trend of each factor
图1. 分析各因素的变化趋势
由图1可以看出在给出的因素中,大多因素比较稳定,但也有少量因素起伏较大如PPI (注:图1未画出)。因此无法判断哪些是影响存款总额的主要因素,接下来引入主成分分析方法来确定主要因素。
4) 主成分分析确定主要因素
设
为参考文献 [2] 中影响宏观经济总量的20个因素。记
,
。
另设
为取自总体
的一个容量为30的简单随机样本。设
为样本协方差矩阵,其特征值
,相应的单位正交特征向量
,则第k个样本主成分表式为
(1)
当依此代入观测值
时,便得到第k个样本主成分的30个观测值。这时
的样本方差为:
(2)
样本总方差为:
(3)
则第k个主成分
的贡献率为
,前m 个样品主成分分析的累计贡献率为
。
5) 确定主要成分
确定主要成分见表2。

Table 2. Determine the main components
表2. 确定主要成分
由上表格计算结果表明,GDP的贡献率为0.4415 = 44.15%,GDP和CPI的累计贡献率为0.7084 = 70.84%,GDP,CPI和工业同比增加值达到了0.8455 = 84.55%,实际中可只取前三个主成分。
6.1.2. 预估2018年该商业银行存款总量模型的建立
设Y代表各年份存款总量的变量,它受到非随机变量因素
(GDP),
(CPI),
(工业同比增加值)和随机误差𝜀的影响。则:
(4)
其中
是固定的未知参数,称为回归系数,随机误差𝜀均值为0。记:
,
,
,
则模型的矩阵形式可以表示为:
(5)
6.1.3. 预估2018年该商业银行存款总量模型的求解
经过matlab仿真求解,求得
,即:
(6)
由此可求得2018年该商业银行的存款总量为44,642亿元。存款增量为
亿元。由题意知如暂不考虑备付水平,该商业银行2018年的贷款总额为存款总额减去应缴纳的法定准备金,即
亿元。则贷款增量为:
亿元。
6.1.4. 模型拟合结果展示
通过以上方法可以预测2018年商业银行的存款总量,将预测的结果进行拟合可以得到图2。
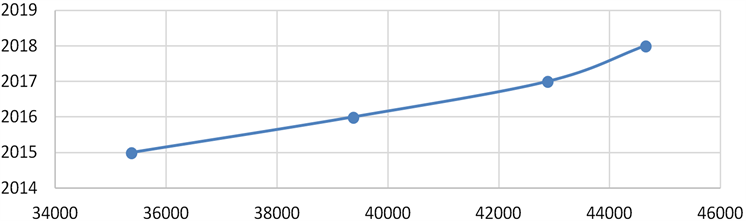
Figure 2. Fitting curve of total deposit of commercial bank
图2. 商业银行存款总量的拟合曲线
从图2我们可以发现存款总量进一步的增加,符合我国良好发展的经济形势,因此可以证实模型结果的正确性。
6.2. 问题二的模型建立与求解
引入净差率的概念:
净差 = 银行当年的存款利率 × 银行当年的存款 − 银行当年的贷款利率 × 银行当年的贷款;利用净差来描述各地分行放款资金吞吐能力以及盈利能力;净差的绝对值可以描述资金吞吐能力,净差的正负代表了银行的盈利能力或亏损能力(由常识我们知道一个银行的存款应当大于贷款;否则这个银行就不正常) [1] ;当银行的净差率为负时只能有两种情况:
6.2.1. 银行的净差率为负的情况之一
由于国家政策的原因,通过资金投入来刺激经济发展,比如说北京市。
6.2.2. 银行的净差率为负的情况之二
银行处于亏损状态。通过计算我们得到了各个省市的三年的净差,下面以10个省市的净差来分析:10个省市的净差见表3。
Table 3. 10 net difference between provinces and municipalities
表3. 10个省市的净差
通过对比我们会发现资金吞吐能力最强的省市:江苏、浙江、广东、上海、湖北;这与我国目前的经济发展是契合的。
在模型二里我们通过前3年的净差用一元二次回归 [3] 。
(7)
(8)
(9)
(10)
来求出回归系数,并预测18年的净差其中ε是随机误差,服从正态分布N(0, n2);
p1,p2,p3为回归系数,由于权重因子 = 各个省市净差/总净差;所以本文就不展示各个城市的净差了。通过各个省市的净差占总的静差的比例作为我18年30个城市贷款变量的权重因子,30个城市贷款变量的权重因子见表4。
Table 4. 30 weighting factors of loan variables in cities
表4. 30个城市贷款变量的权重因子
表中:1、2、3分别代表北京、江苏、广东,其余类推。
通过对30个城市贷款因子进行多元线性规划来求得最大值:
多元线性规划:
St:
(11)
(12)
其中St是各个城市的权重因子(比如S1 = 0.001348);
代表代号为i的城市的贷款分配量(i = 代表北京);
的范围由三年内的存款量和贷款量决定;原则是
的下限由三年内最低贷款量决定,
的上限由最大存款量决定;当然某些地方有政策原因应反过来;包括某些西部地区。这是每个城市对应的贷款分配具体数额:(1代表北京),每个城市对应的贷款分配具体数额见表5。
Table 5. The specific amount of loan allocation in each city
表5. 每个城市对应的贷款分配具体数额
总和为39,284亿元。
6.3. 问题三的模型建立与求解
通过对模型2的分析我们知道净差越大地方资金的吞吐量越大那么这个地方的资金承受能力就越大,通过查找外部数据,对比了各个省市的GDP增速,GDP增速代表着当地的经济活跃程度,也就意味着更多的企业可能会用到这一笔应急贷款,通过GDP的增速排名和增速比例我们重新调整权重因子在原有贷款的基础上加上这笔钱重新进行分配,调整的原则依据于省市的GDP增速比例,我们认为一个省市的GDP增长越快,那么它对资金的需求就该越大,但由于省市的资金吞吐量并不能正比与它的GDP增长所以我们要综合地去考虑这个问题,我们通过对两个权重再次进行权重分配来调节,对净差决定的权重因子取0.7,对GDP增长率决定的权重因子取0.3,表6是我们外部数据出处:2016年各省区市GDP排名一览见表6。
Table 6. Shows the GDP ranking of each province, region and city in 2016 [4]
表6. 2016年各省区市GDP排名一览 [4]
然后通过对权重因子调整带入模型二,求得重新分配的方案:得到了我们关于净差因素的权重因子和GDP的权重因子及第三次资金分配结果与第二次的对比一览表:净差因素的权重因子和GDP的权重因子及第三次资金分配结果与第二次的对比一览表见表7。
通过表我们可以得到第三次改变的城市有:贵州、江西、云南、吉林、重庆、辽宁由表6中的GDP增速比对这是符合现实的。
6.4. 问题四的模型建立与求解
对于问题四,我们首先用MATLAB的正态检验函数检测各分行净变化量的数据是否服从正态分布 [5] ,以广东分行的数据为例,检测的图像如图3。
Table 7. Comparison of weighted factors of net difference factors and GDP and the results of the third capital allocation with the second
表7. 净差因素的权重因子和GDP的权重因子及第三次资金分配结果与第二次的对比一览表
可以看到,广东分行的净变化量满足正态分布的条件,于是可以拟合出正态分布图像以及每个正态分布函数的总体均值(muhat)和方差(signahat),如图4所示:正态分布图像以及每个正态分布函数的总体均值(muhat)和方差(signahat)见图4。
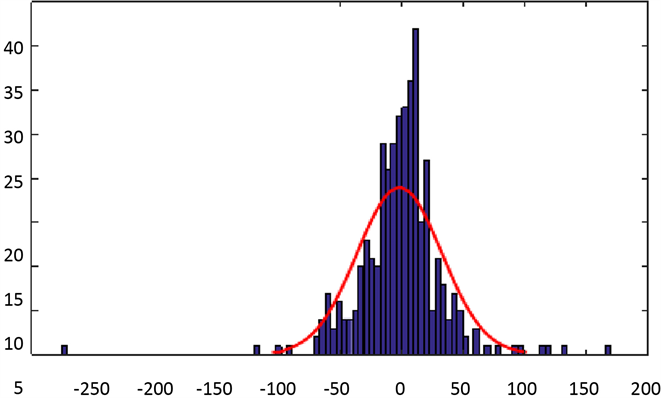
Figure 4. Normal distribution image and population mean (muhat) and variance (signahat) of each normal distribution function
图4. 正态分布图像以及每个正态分布函数的总体均值(muhat)和方差(signahat).
muhat = −0.9863,sigmahat = 34.4104,下一步即利用概率论与数理统计的知识,算出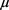 的置信区间,易知样本均值
是
的无偏估计,现在要利用
所提供的信息,由
来确定
,
,为此需要把阔行不等式中间的变量化为有确定分布的样本函数,经简单变化得:
的置信区间,易知样本均值
是
的无偏估计,现在要利用
所提供的信息,由
来确定
,
,为此需要把阔行不等式中间的变量化为有确定分布的样本函数,经简单变化得:
(13)
以上样本函数
,且
不依赖于任何未知参数,因此对给定的置信水平
,由上
上分位点的定义,
有:
(14)
若令
,
,可得 的一个置信水平为
的区间为:
的一个置信水平为
的区间为:
(15)
于是可得广东省在99%置信水平的条件下,
的置信区间为(−5.6501, 3.6775),解得最低的备付金额为5.65亿元。
其他城市的最低的备付金额依照此方法依次计算,计算结果列入总表。另外,部分省市的正态检验函数图像和拟合正态分布图像在参考文献 [4] 中有体现。
6.5. 问题五的求解
经过以上贷款规模的分配,可知在不考虑其他因素的条件下全行增量存贷款 利息净收入达到最大。但现实中往往还要受到很多其他因素的影响,为了更好的 帮助该银行的分配与决策,现引入某地区不良贷款规模、国际政策导向以及平衡 区域化差异顺应相应国家政策等因素来对模型进行改进。
假设某地区的不良贷款规模占总贷款量的比值为u,则u值越大说明该地区的信用等级越低。对于一些u值较大的省份,要慎重的选择给与他们贷款或者相应的减少贷款量。经过查阅数据显示不良贷款率区间散布:9省市不良贷款率超越2%内蒙古是不良贷款率最高的省份,高达3.97%;福建、浙江、山西、山东、云南、广西、江西和四川的不良贷款率也在2%以上;18省市不良贷款率超越2%除上述银行,不良贷款率较高的省份还有陕西、青海、安徽、黑龙江、湖南、辽宁等,不良率均在1.6%以上;4省市不良贷款率超越2%西藏区域2015年的不良率最低,为0.23%,此外,海南、北京和重庆的不良贷款率别离为0.69%、0.84%和0.99%。因此在2018年可对于一些不良贷款率值较大的省份,要慎重的选择给与他们贷款或者相应的减少贷款量。31家省市商业银行不良贷款率(2016~2017年)见表8。
Table 8. Non-performing loan ratio ranking of 31 provincial and municipal commercial Banks (2016-2017) [6]
表8. 31家省市商业银行不良贷款率 [6] (2016~2017年)
若某地区国际政策导向较好,则即便该地区存款较少,也可以加大对该地区的贷款投放量,为未来谋得更好的发展。如一带一路沿线省份(新疆、西藏、贵州、云南、黑龙江、海南、甘肃和内蒙古等)。若某地区由于区域化差异致使该地区较为落后存款量较少,但又由于国家的战略要求要大力发展该地区,则应加大对该地区的贷款投放量,帮助该地区发展。如国家的西部大开发战略,中部崛起战略等。
7. 模型结果
模型结果见表9。
8. 模型评价、改进及推广
8.1. 模型的评价
8.1.1. 模型的优点
第一问运用主成分分析和多元线性拟合方法选择出有代表性的3种元素并进行多元拟合,有较好的模拟能力和较高的信任程度,第二问中,用线性规划解出30个变量的最优解,结果较为准确,第四问则用matlab模拟正态分布函数,拟合度很高,结果也更加准确。
8.1.2. 模型的缺点
在我们的模型假设中,忽略了一些对问题影响的次要因素,比如在第一问中,我们只考虑了前三个宏观经济指标,忽略了其他次要指标对模型的影响,这或多或少是问题得到了简化,但必然会产生一些误差;主成分方法的使用不够准确,可做更深一步的研究。另外,解决问题的方法是有很多的,在有些的模型中只用了少数的几种方法,思维可能比较局限;另外,我们建立的模型本身可能有一定的优势和缺陷,使得结果不尽如人意。
8.2. 模型的改进
模型通过主成分分析的出来的是综合在考虑宏观经济指标时可以多考虑几个甚至全部考虑进去,也可以给每个省市提供贷款额度时,依据实际情况,比如不良贷款率,经济发展情况,国家扶持政策等因素来改变最终的分配方案。或者考虑适用度更高的算法建立模型,是结果更加准确。
8.3. 模型的推广
该模型只是模拟了商业银行的情况,这也可以推广到其他企业运营当中,考虑到自身盈利的各个方面和因素,将利益短期最大化或者选择长期发展。
9. 结束语
通过对以上问题的研究,模拟了商业银行的情况,该研究对国内外同行有着十分重要的意义和参考价值。