1. 引言
随着技术发展的不断加快和人们对土壤质量的关注,目前土壤质量问题越来越受到人们的重视 [1] [2]。传统的土壤质量评价方法是基于大量人力物力,从采样到室内分析,人们几乎要参与到各个方面,如果仅仅靠手工来做分析,那无疑是最耗时的。随着实验设备的不断改进,产生了大量的数据,这就需要快速的分析和产生结果。因此,引入机器学习并合理参考相关成熟算法来解决地学中的相关问题是非常重要的 [3] [4] [5]。目前关于土壤重金属污染的研究主要还是基于传统的地质统计学方法,包括地累积系数法、富集系数与变异系数、多重分形、相关分析等。
随机森林是利用多棵决策树基于统计学对样本进行训练,提炼出某种规则,并将该规则用于预测的一种组合分类器,已成为在面临分类问题上,可以优先选择的算法之一。Scarpone等人提出了一种使用随机森林分类器和遗留土地数据定位加拿大不列颠哥伦比亚省南部山地景观中EB区域的方法,与传统的土地覆盖图相比,使用射频模型后,电子地图的精确度从48%提高到88% [6]。到目前为止,随机森林算法已经被广泛用于生物信息学、生态学、遗传学、环境监控、金融学、遥感地理学等众多领域,却很少应用在重金属检测方面。本文引入随机森林算法,以欧洲地区为例,对该地区的表层土壤中重金属含量进行了分类预测,为了说明研究结果的合理性,最后采用C-A多重分形方法进行验证和对比。
2. 方法
随机森林属于一种集成方法,首先训练出多个模型,这些模型之间相互独立,然后把这些模型产生的结果放在一起,得票最多的为最终的预测结果 [7]。“森林”之意来源于随机森林包含多个相互无关联的决策树。该方法优于传统统计学方法的地方在于不需要事先了解或假设数据的分布情况,而且克服了决策树这种单分类器过度拟合和局部最优解的问题,同时也是一种非参数的模式识别分类方法,可以应用于大部分的数据分类场景。如果数据是高维的,那么随机森林在学习速度、抗噪音能力、预测精度上的优势就越发明显。
2.1. 集成学习方法Bagging
Bagging获取训练集的方式是通过自助采样的方法(bootstrap sampling),按照随机原则,每次在大小为n的原始集合中获取m个样本,而这m个样本中可能含有多次被取到的样本i,同时也可能样本j永
远都没被取到 [8]。样本在m次采样中始终不被采集到的概率为
,取极限可得:
(1)
由公式(1)可知,通过Bagging方式得到的训练集与原始集合相比,有63.2%的重复率。这种有重复性的选取样本的方法可以增加各个学习器之间的差异性,使每个学习器之间尽可能的相互独立,那么组合起来的学习器在泛化能力上有更好的优势。
Bagging的算法步骤如下:
第一步:输入训练集
,弱学习算法L;训练次数T。
第二步:输出最终分类器
。
对
:首先用bootstrap sampling对集合T选样,得到集合
;然后再次使用该方法得出训练集
、学习基本分类器
,最后得出最终分类器
。
(2)
2.2. 构造决策树
本文在生成决策树时利用ID3算法。
ID3算法选择熵作为寻找分裂特征的指标,每个节点会选择导致最大熵降幅的特征用于分裂,熵的减少量称为信息增益 [9]。计算过程如下:
1) 计算每个节点在分裂前的熵:
(3)
其中,
表示特定目标类别 在总样本量中的占比。
在总样本量中的占比。
2) 根据特征A将数据集T分裂为k个子集后的熵:
(4)
其中,
代表第
个划分的权重,划分的纯度随着
的减小而强。
3) 由公式(11)和公式(12)可得出信息增益:
(5)
其中,
表示信息增益。
2.3. 构造随机森林
详细步骤如下所示:
step 1:假设含N个样本的数据集
,采用有放回随机抽样的方式再次组成一个大小为N的集合
。
step 2:假设每个样本具有M个属性,随机选取m个属性(m < M),根据构造决策树的原理,通过比较选择最佳属性作为分裂节点在不进行剪枝的情况下递归生成一棵决策树。
step 3:重复步骤1、2中决策树构造过程,形成多棵相互独立的决策树,从而构成随机森林。
3. 实例研究
3.1. 数据来源
本文以欧洲表层土壤为研究对象,数据源于地球化学基准值填图计划 [10] ,采样按照全球参考网格(GRN),每个网格大小是160 km × 160 km,每有5个采样点,共计773个样本。样本点分布在整个欧洲(见图1),包括25个国家(见表1)。为保证数据的一致性和避免实验室之间存在分析偏差,所有样本均在同一实验室测量,同一种元素在同一实验室用同一种方法分析。

Figure 1. Distribution of soil sampling points in Europe
图1. 欧洲土壤采样点分布

Table 1. Statistics of sampling sites in European countries
表1. 欧洲各国采样点统计
3.2. 数据预处理
为了利用随机森林算法训练数据,根据国际土壤重金属含量标准,将原始数据分为四个层次(见表2)。
Table 2. Classification criteria of heavy metals in top soils under international standards (mg/kg)
表2. 表层土壤在国际标准下所含重金属分类标准(mg/kg)
3.3. Random forest模型建立与结果分析
我们使用欧洲地区采样点数据,建立Random forest模型,利用MATLAB软件编程,对数据训练后,输出预测的分类结果,并计算出分类精确度(见表3)。
Table 3. Precision of predicted results
表3. 预测结果精确度
从表3可知,Random forest模型的平均精确度为93.41%,精确度最低为74.08%,最高可达100%。
3.4. 模型改进
为了进一步提高模型的精确度,降低树与树之间的相关性,本文考虑考虑引入加入核函数的主成分分析(KPCA)来达到降维的目的,从而提高随机森林的分类性能。
3.4.1. KPCA实现步骤
KPCA是在PCA基础上的一种非线性推广,在处理非线性问题上具有一定的优势 [11]。
1) 对应给定的原始空间
,引入非线性映射
,使原始空间
投影到特征空间
,即: ,且满足
,则在
空间中的协方差阵为:
,且满足
,则在
空间中的协方差阵为:
(10)
2) 计算核矩阵
:
(11)
3) 中心化后的核矩阵
为:
(12)
其中,
为
的矩阵,
。
4) 计算出核矩阵
的特征根
,以及对应的特征向量
。
5) 用斯密特正交化后的特征向量为:
。
6) 空间
的核主成分为:
(13)
其中,
, 为第
个主成分的特征根。
为第
个主成分的特征根。
7) 输出数据: 。
。
3.4.2. KPCA-Random forest模型建立与结果分析
本文在用KPCA提取特征之前,需要先估计数据集的基本维数,此时我们使用最大似然估计来估计基本维;通过KPCA处理后,将数据集的维度从八个维度减少到四个维度;然后用随机森林算法训练和测试。用MATLAB编程实现后输出此模型的分类精度,与改进前的模型进行对比,结果见表4。
从表4可以看出,改进后的模型精度为94.67%,比改进前提高了1.26%。此外,运行时间也从12.530601 s缩减到9.437811 s。结果表明,KPCA处理的数据不仅可以用于支持向量机,还可以用于提高随机森林算法的分类精度,这为实现地理智能化处理提供了一种思路。
我们使用MAPGIS软件绘制了具体的空间分布情况,见图2。
Table 4. Precision comparison of model prediction
表4. 模型预测精确度对比

Figure 2. Distribution map of soil pollution under random forest model
图2. 随机森林模型下土壤污染分布图
4. 模型评价
4.1. 模型的优点
本文对建立的随机森林模型分别从可靠性、精确度和重用性上进行评价。
1) 模型可靠性
为验证模型是否可靠,本文采用常用的研究土壤污染情况的C-A分形方法 [12] ,通过GeoDAS绘制出重金属元素空间分布图,见图3。
对比可知,两种方法下提取的异常位置大体一致,从而可以看出随机森林模型对圈定化学异常位置上具有可靠性。
2) 模型精确度
对比分析表明,随机森林模型下缩小了异常范围,而且改进后模型的平均分类精度达到94.67%,在预测精确度方面具有很好的效果。
3) 模型可重用性
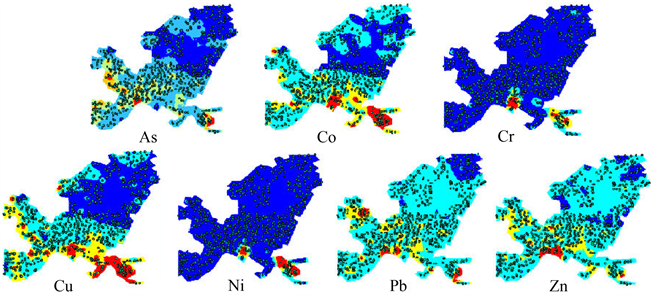
Figure 3. Distribution map of soil pollution based on c-a fractal method
图3. C-A分形方法下土壤污染分布图
相似数据可以直接用训练过的规则进行分类,不需要再训练,这比传统的地质分类方法具有更高的可重用性,同时效率也将大大提高。
4.2. 模型的缺点
本文建立的随机森林模型是在不考虑分布不平衡数据的情况下。该模型在面对类别分布不平衡的数据时,会出现分类效果不佳、误差率变高等一系列问题。
5. 结束语
本文使用了随机森林来研究土壤重金属污染问题,同时对建立的随机森林模型进行了改进。从实验结果来看,核主成分分析与随机森林结合建立的模型在分类效率和运行时间上均优于标准的随机森林模型,且评价结果与传统地质学中C-A多重分形得出的结果相符。在接下来的工作中,我们将考虑如何实现不平衡数据集下的随机森林模型,以及如何实现分布式并行计算,对于提高大数据时代的分类效率具有重要意义。