1. 引言
在图像处理领域中,图像匹配是一个研究热点,它可以广泛应用于目标识别与跟踪 [1] 、遥感影像处理 [2] 等领域。
图像匹配通常分为三个步骤:图像特征点的检测、特征点的提取及特征点的匹配。国内外学者对于图像匹配也有许多出色的研究,例如2004年David G. Lowe整理完善所提出的SIFT算法 [3] ,它对于光线、噪声、微视角改变的容忍度较高;2006年Herbert Bay等人提出了SURF算法 [4] ,该算法的优点在于所提取的特征具有平移、缩放、旋转的不变性,且相较于SIFT算法来说,计算速度得到了提高;Calander等人提出的BRIEF算法 [5] 和Stefan提出的BRISK算法 [6] 均是生成二进制链码描述符,且都加速了特征向量匹配过程,但是BRIEF描述符对于旋转非常敏感,造成了其具有一定的局限性;而BRISK算法相对而言较为稳定,有更好的尺度与光照不变性,且它的特征点的检测和描述子的计算比BRIEF的速度要快一个数量级;Alahi等人于2012年提出了FREAK算法 [7] ,该算法是从人眼识别物体的原理中得到启发的,它利用人类视网膜的特性来进行采样点的选择,算法较为新颖,但是该算法不具备尺度不变性,在图像尺度发生变化的情况下,特征点的匹配准确率会大大降低。
本文的主要工作有:1) 使用BRISK算法对图像的特征点进行检测;2) 用FREAK描述子对特征点进行描述;3) 使用BF匹配算法对图像的特征点进行匹配;4) 研究对比本文所提出的BRISK + FREAK + BF方法与传统的BRISK算法与FREAK算法,比较分析后得知本文所提出的方法在特征点的数目及匹配的正确率上均有了一定的提高,且在不同尺度与不同光照下具有良好的鲁棒性。同时,使用GPU进行加速使本文算法的实时性也较高。
2. BRISK算法
2.1. BRISK算法
BRISK算法是于2011年提出的特征提取算法,它具有良好的旋转不变性、尺度不变性及较好的鲁棒性等。为实现尺度不变性,BRISK算法首先应用高斯差分滤波器把图像构建成N组S层的高斯差分DOG (Difference of Gaussian)金字塔 [8] ,如图1所示。高斯差分金字塔是由高斯金字塔构造得到的,它是对同一个八度的两幅相邻的图像做差得到插值图像,所有八度的这些插值图像的集合,便构成了高斯差分金字塔。
DOG金字塔的第一组第一层是由高斯金字塔的第一组第二层减去第一组第一层得到,第一组第二层是由高斯金字塔的第一组第三层减去第一组第二层得到的,依次类推,逐组逐层生成每一个差分图像,所有差分图像构成差分金字塔。高斯差分金字塔可用于后续的特征点的提取。
2.2. AGAST特征检测
BRISK算法中所采用的特征检测算法是AGAST算法,它可以提高尺度空间的准确性,AGAST算法 [9] 是由Mair等人提出的一种改进的FAST算法 [10] ,即自适应多尺度快速角点检测算法AGAST (Adaptive Generic Accelerated Segment Test)。该算法在尺度不变的要求下,有着更高的计算效率和实时性。
AGAST算法构建了更为精细的尺度空间金字塔,它由n个octave层
和n个中间层
组成(
) [11]。
是通过对原始图像
的一次半采样得到的,中间层
是对
的1.5倍采样得到的,其余内层依次对
半采样得到,如图2所示。

Figure 2. AGAST algorithm scale spatial feature point detection
图2. AGAST算法尺度空间特征点检测
AGAST特征点检测算法主要分为以下两个步骤:第一,在每一层和内层分别运用阈值为T的FAST9-16,即16个像素点中至少有连续9个像素点比中心像素点充分亮或者充分暗作为准则,来使用探测子检测潜在的兴趣域;第二,在尺度空间内对潜在的兴趣域中的各个像素点进行非极大值抑制;AGAST特征检测算法为了能更加准确地定位特征点,对所检测出的每一个极大值都进行连续尺度优化及亚像素校正 [12]。
3. FREAK算法
3.1. FREAK采样模式
生物学家研究表明,在人眼的视网膜区域中,感受光线的细胞的密度是不同的。根据感光细胞的密度将人眼的视网膜分为了4个区域:foveola、fovea、parafoveal、perifoveal [13]。其中,foveola区域主要是对高分辨率的图像进行处理,perifoveal主要是对低分辨率的图像进行处理,如图3所示。正是基于人类视网膜的结构,Alahi等人才提出了FREAK算法。
FREAK (Fast REtinA Keypoint),即快速视网膜特征点提取算法,该算法采取了更接近人眼视觉系统接收图像信息的采样模式。该模式以特征点为中心,由7层同心圆环构成,每层圆环均匀取6个采样点。如果采样点离特征点的距离越近,采样点圆的半径越小,则采样点越密集;离特征点的距离越远,采样点圆的半径越大,则采样点越稀疏 [14]。FREAK算法对每个采样点进行了高斯平滑处理,每个圆圈的半径表示了高斯模糊的标准差。
3.2. FREAK特征点描述子
FREAK描述子由采样点对的强度比较结果级联组成,形成了二进制位串描述子 [14] ,用F表示,如下公式1、2所示:
(1)
(2)
式中,
表示当前采样点的位置,
表示采样点对 Pa 中前一个采样点的像素值,
表示后一个采样点的像素值。
假设共得到了M个采样点个数,则描述向量共有
维生成,但图像所包含的全部信息量并不全部存储于这些维度中,有些维度是冗余的,FREAK算法为了得到更具辨识度的描述子,对所得到的描述子进行筛选,保留信息量大的维度。
1) 首先构建一个矩阵D,D的每一行表示一个特征点二进制描述子,每一行有
列;
2) 计算矩阵D的每一列的均值,由于D中元素均是0/1分布的,且为了得到独特性较好的特征,所要求的方差应该较大,所以取列的均值为0.5;
3) 对所计算得到的每一列的方差进行由大到小的排序;
4) 最后选取前512列作为最终的二进制描述符,也可以选择256、1024等,但是发现只有前512列是最相关的,再增加列数对结果并没有很大的提高。
上述筛选完成之后,FREAK描述符周边的采样区域生成了低维度的描述向量,而高维度的描述向量则生成在FREAK描述符中心的采样区域中。由此我们可以得到,FREAK描述符周边的采样区域可以将目标图像的基本信息描述出来,而目标图像的细节信息则会被FREAK描述符中心的采样区域所描述出来。
3.3. 为特征点分配方向
使用FREAK算法进行图像特征匹配之前,还需要为所提取到的特征点分配主方向和记录梯度特征。由于特征点周围有43个采样点,可产生
个采样点对,FREAK算法选取其中45个长的、对称的采样点对来提取特征点的方向,如下图4所示:
其特征点方向计算公式为:
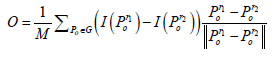 (3)
(3)
其中,O表示图像的局部梯度信息,M表示采样点对的个数,G表示采样点对的集合,
表示采样点对的位置。
3.4. 特征点匹配
本文所采用的特征点匹配方法为BF算法,即暴力(Brute Force)算法 [15] ,它是一种普通的模式匹配算法,它的思想是将目标串S的第一个字符与模式串T的第一个字符进行匹配。若相等,则继续比较S的第二个字符和T的第二个字符;若不相等,则比较S的第二个字符和T的第一个字符,依次比较下去,直到得出最后的匹配结果。
BF算法应用于图像特征点匹配领域中,首先在第一幅图像中选取一个特征点然后依次与第二幅图像的每个关键点进行距离测试,最后返回距离最近的特征点。BF算法较为直接,是一种蛮力算法,时间复杂度为O(M*N),虽牺牲了时间但换取了该算法的准确性,所以本文采用该匹配方法。
4. GPU加速
GPU (Graphics Processing Unit) [16] 即图形处理器,又称显示核心、视觉处理器、显示芯片,它可以工作于多种场合,例如个人电脑、游戏机等。由于在现代的计算机中图形处理变得越来越重要,所以需要一个专门的用于图形处理的核心处理器,这时候GPU便显示出它优越的性能,GPU可以进行并行计算,显著提高了图形处理的实时性。它是显示卡的“心脏”,相当于是专用于图形处理的CPU,在图像处理领域中它更专业更强大,且它的工作效率要远高于CPU。
NVIDIA提供了调用GPU的CUDA核心的接口,CUDA是一个并行计算架构,它为GPU并行提供了一个平台,并利用虚拟指令来访问并行计算资源,可以使大量程序员能运用所学语言进行编程。GPU适合较大规模的数据计算,相比CPU来说,能大大缩短运行时间,提高实时性。所以本实验在Visual Studio2015的基础上安装了CUDA9.0并配置了环境变量,确保了实验的顺利进行。
5. 实验及结果
本实验平台是基于windows7 + Visual Studio2015 + Opencv3.3.1 + CUDA9.0,所采用的测试图像为anne、michel,其像素分别为720 × 288、320 × 240,图像匹配结果如下所示。本文实验首先使用BRISK特征检测算法检测出图像的关键点,其次使用FREAK算法提取出图像的特征点,最后利用BF匹配算法对所提取到的特征点进行匹配,得到图像的匹配结果。
5.1. 尺度不同对比实验
对于尺度变化的图像来说,例如图像anne,所得到的图像匹配结果如下图5所示:
 BRISK算法
BRISK算法  FREAK算法
FREAK算法 本文算法
本文算法
Figure 5. Matching image for each algorithm of anne
图5. Anne的各算法的匹配图像

Table 1. Match results of each algorithm of anne
表1. Anne的各算法的的匹配结果
表1通过对不同尺度的图像的匹配结果进行分析,我们发现BRISK算法与FREAK算法所提取到的特征点较少且匹配的正确率不高,由于FREAK算法不具备尺度不变性,可以发现FREAK算法虽提取到的特征点较BRISK算法来说较多但正确率却有所降低。而本文的算法考虑到了BRISK特征检测的尺度不变性,与FREAK描述子进行结合所得到的匹配结果具有一定的尺度不变性。本文算法与FREAK算法相比来说,匹配数目有了近3倍的提升;与匹配的正确率较高的BRISK算法相比来说,本文算法的正确率也提高到了90.91%,可以看出本文算法在对图像有一定的尺度差异的情况下具有良好的鲁棒性。从程序的运行时间来看,本文算法使用了GPU并行处理,所用时间比BRISK和FREAK两种算法都少,并且相较于速度较快的BRISK算法来说,本文算法的运行速度提升了38.88%。
5.2. 亮度不同对比实验
对于光照变化的图像来说,例如图像Michel,所得到的图像匹配结果如下图6所示:
 BRISK算法
BRISK算法  FREAK算法
FREAK算法  本文算法
本文算法
Figure 6. Matching image for each algorithm of Michel
图6. Michel的各算法的匹配图像
Table 2. Match results of each algorithm of Michel
表2. Michel的各算法的匹配结果
表2通过对不同光照条件下的图像的匹配结果进行分析,仍然也可以发现,BRISK算法所提取到的特征点较少,但匹配的正确率却比FREAK算法高;FREAK算法所提取的特征点较多但正确率却有所降低,这是由于FREAK算法不具有光照不变性,本文算法较其余两种方法来说特征匹配数目及正确率均有所提高。本文算法与FREAK算法相比来说,匹配数目有了近5倍的提升,且本文算法的正确率较BRISK来说提高到了92.38%,所以本文算法在对图像有一定的光照差异的情况下也具有良好的鲁棒性。同时,经过GPU的加速,本文算法的运行时间仅为14 ms,相比BRISK算法来说提高了39.13%。
6. 结论
通过上述表述,我们对比了BRISK算法、FREAK算法以及本文提出的BRISK + FREAK + BF算法,并且研究了本文算法在不同尺度及不同光照条件下的图像匹配结果,研究结果表明,本文算法无论是在尺度不变性还是光照不变性上都优于这两种算法。BRISK算法优点在于其运行速度很快,但同时该算法所提取到的特征点也较少;FREAK算法由于不具备尺度不变性与光照不变性,所以其匹配准确度过低,匹配结果误匹配较多。而本文提出的算法则很好地结合了这两种算法的优点,本文只选取了两组较具有代表性的图像结果,但经过大量的实验图像数据表明,本文算法的特征匹配的数目较FREAK算法来说提高了3~5倍,匹配的正确率较BRISK算法来说从50%~60%提高到了90%左右,且本文算法运行于GPU加速平台上,相比BRISK算法来说,速度提高了35%~40%左右。可以证明本文算法对图像的尺度差异及光照差异具有良好的鲁棒性,且实时性有了较大的提高。同时,本文也存在不足的地方,如何进一步提高算法的匹配准确率及实时性将是未来的研究方向。