1. 研究背景
我国烟草行业现在实行的是国家专卖专营制度,即“统一领导,垂直管理,专卖专营的管理体制”,是国家最主要的纳税主体之一,承担着重要的纳税责任与义务。精准预测卷烟销量有以下几个优点:一、可以科学制定营销策略。通过预测卷烟销量,烟草公司可以针对市场的变化做出判断,制定策略;二、可以为生产计划提供依据,降低库存的成本;三、可以提高客户的满意度,降低卷烟的滞销率。因此,通过预测卷烟销量来制定烟厂的运营生产计划成为了必不可少的环节。
2. 国内研究现状
卷烟销量预测主要有两种方式:第一种方法是通过设定影响卷烟销量的宏观经济变量和微观个体变量,拟合出影响因素与卷烟销量的回归模型进行预测。宏观指标中就包括有人口指标和经济指标两大类,如地区人口数量,地区GDP总量,居民人均收入,居民消费水平等因素。微观指标指由于个人因素的不同导致卷烟需求量的不同,如烟龄,教育水平,每天吸食量等。高洪利 [1] 通过对影响卷烟销量因素的分析,从宏观因素和个体因素两个方面提出相关的影响变量,再利用随机森林回归的方法建立卷烟需求预测模型,对北京2011年至2015年的卷烟销量进行预测。
第二种方法就是通过历史卷烟销量数据对未来数据进行预测,主要的方法有神经网络、马尔可夫链、时间序列模型等。第二种方法数据更易于收集且数据更为可靠,因此得到的预测结果更为精准。邹亮 [2] 通过怀化卷烟历史销售数据,采用趋势外推法、时间序列分解法和多元回归法对历史数据进行分析,通过组合误差的方差最小原则来确定权重,应用组合预测的方法,将三种分析方法进行综合,证明得到的组合预测模型有效提高精度,减少误差。朱俊江,李孝禄 [3] 等提出通过小波变换对卷烟销售序列分解,将原始序列分为频带成分不同的分量。根据分量的不同特性分别对每一分量进行模型拟合,低频分量采用AR模型,中频分量采用ARMA模型,残差分量采用神经网络算法。最后将各分量预测结果加总得到混合模型预测值,相比于采用单一模型预测的卷烟销量更加精准。王伟民 [4] 全国卷烟销量呈现出逐渐向上的趋势并有一定的波动,因此采用灰色模型GM(1,1)对数据进行拟合,并根据马尔科夫链理论修正灰色模型得到预测结果,得到结果预测的波动性更加符合历史数据。曹鲁东 [5] 建立
的乘积季节性时间序列模型,应用该模型对2009年至2012年国内一类卷烟的月度销量数据进行了预测。
3. 理论模型选择
3.1. 时间序列分解模型
时间序列的各种变化可以归纳成四类影响因素,即长期趋势:该因素会影响导致序列呈现出明显的长期趋势;循环波动:该因素会导致序列呈现出从低到高再由高到低的反复循环波动;季节性变动:该因素会导致序列呈现出和季节变化相关的稳定的周期波动;随机波动:除了长期趋势、循环波动和季节性变动外,序列还会受到各种其他因素的综合影响,而这些影响导致序列呈现出一定的随机波动。按照它们的影响方式不同可以设定为不同的组合模型,常用的乘法模型和加法模型两种。
加法模型: 。
。
乘法模型:
。
3.2. 移动平均法
移动平均法 [6] 的基本思想是对于一个时间序列
,我们可以假定在一个比较短的时间间隔里,序列的取值是比较稳定的,它们之间的差异主要是由随机波动造成的。根据这种假定,我们可以用一定时间间隔内的平均值作为下一期的估计值。n期移动平均是一种常用的平稳序列预测方法,使用n期移动平均方法,向前预测 期,各期的预测值为:
移动平均期数对原序列的修匀效果影响很大,一般移动平均的期数越多,修匀曲线越平滑,表现出的长期趋势就越清晰,如果时间的发展有一定的周期性,一般以周期长度作为移动平均的间隔长度。
3.3. 季节指数
凡是呈现出固定周期性变化的事件,都称它有“季节”效应。季节指数采用移动平均趋势剔除法 [7] ,基本步骤分为三步:第一步:计算移动平均值,并对其结果进行中心化处理,也就是将移动平均的结果在进行一次二项移动平均,得出中心化移动平均值。第二步:计算移动平均的比值,即将序列的各观察值除以相应的中心化移动平均值,然后计算出各比值的季度平均值。第三步:季节指数调整。将第二部计算出的每个季节比率的平均值除以他们的总平均值。
4. 数据来源及处理
本文数据采用2004年第一季度至2017年第四季度的全国卷烟季度销量,详细数据见表1。将卷烟销量绘制成时间序列曲线图(图1),从图1中可以看出,全国卷烟季度销量总体有缓慢上升的趋势,具有明显的季节性和周期性变化,波动幅度明显。可以采用时间序列分解模型中的乘法模型对该数据进行分析。

Table 1. The first quarter of 2004 to 2016 in the fourth quarter of the national cigarette sales quarterly sales data
表1. 2004年第一季度~2017年第四季度全国卷烟销量(亿支)
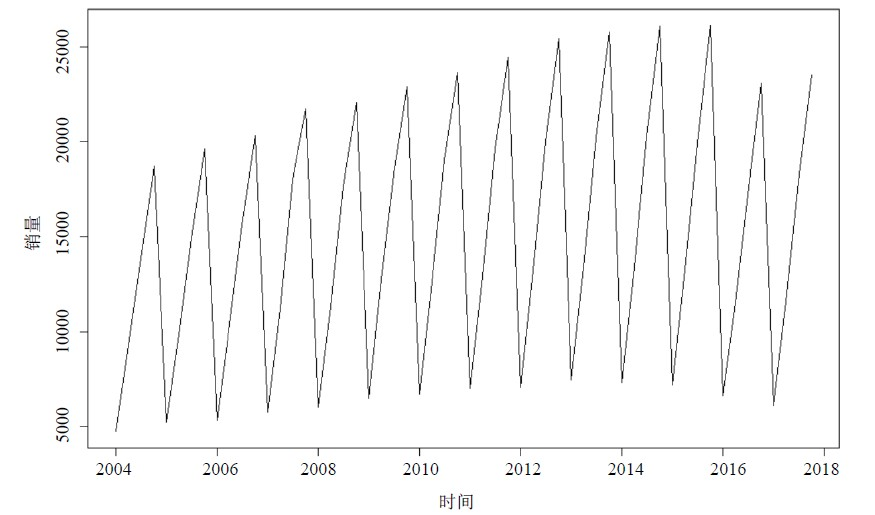
Figure 1. Line: The first quarter of 2004 to 2016 in the fourth quarter of the national cigarette sales quarterly sales data
图1. 2004年第一季度~2017年第四季度全国卷烟销量时序图
根据表1数据做出趋势图(图1)可以看出,卷烟销量从2004年至2014年每年的需求量有明显的上升趋势,从2015年开始销量开始下降,这个原因主要是2015年是中国控烟履约出台政策举措最多、措施最严厉的一年。2015年开始推行的控烟政策从两方面影响了卷烟需求:1) “提税顺价”,购烟成本上涨:经国务院批准,从2015年5月10日起,卷烟消费税大幅提升;2) 加强烟草宣传限制:修正《广告法》和《卷烟包装标识的规定》,对烟草的宣传和标志进行限制和规范。卷烟需求开始出现下滑。由于卷烟消费偏刚性需求,随着消费者对涨价接受度的提高,卷烟需求从2017年开始逐步回升。2017年后卷烟销量数据较少不再对2017年后的数据进行拟合,仅使用2004年第一季度至2016年第四季度的销量数据。
5. 全国卷烟销量时间序列分解模型
5.1. 趋势变动分析
为了分析全国卷烟销量的总体趋势,对原数据做以4为步长的中心值移动平均,将原序列中的随机波动I和季节变动S消除,使得到的移动平均结果中只包含趋势变动T,所得结果见表2。
Table 2. Resulting data of moving average
表2. 移动平均结果
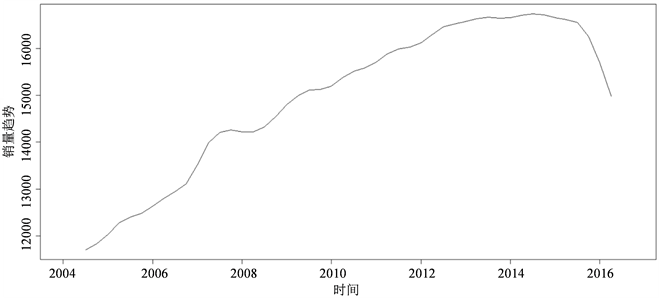
Figure 2. Curve: national cigarette sales trend
图2. 全国卷烟销量趋势图
从趋势图(图2)可以看出,折线的转折点在t = 42的位置,所对应的是2014年第四季度。可以将该序列分段拟合成两个一元线性回归模型。
第一段:
时描绘散点图(图3),进行线性估计,由最小二乘法的估计参数得出
,
远小于0.05显著性检验通过,即当
时,
。
第二段:
时描绘散点图(图3),进行线性估计,由最小二乘法的估计参数得出
,
小于0.05显著性检验通过,即当
时,
。
综上所述,总趋势的分段模型为
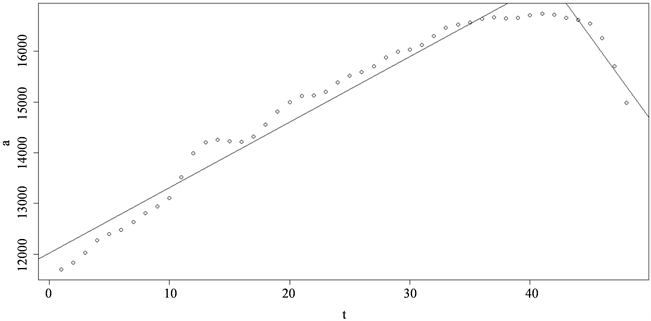
Figure 3. Scatter plot and fitting line after moving average
图3. 移动平均后散点图及拟合直线
5.2. 季节效应分析
使用移动平均趋势剔除法计算季节指数,结果见表3。通过
剔除了趋势项后,新的序列只包含了季节波动S和随机波动I,即
。将每年相同季度的
计算平均数,再分别除以总平均数,就得到了季节指数S。通过表3的季节指数可以看出每年的一二季度为销售淡季,三四季度为销售旺季。
Table 3. Resulting data of seasonal index
表3. 季节指数结果
5.3. 模型的拟合
通过上面对趋势和季节的分析,分别得拟合出了趋势模型和季节指数,不规则变动I无法进行预测,根据乘法模型
,将上述结果带入得到:
根据该式对历史数据进行测算和比较,结果见表4。
通过表中的结果可以看出模型的拟合效果与实际数据相当接近,除2007年第三季度和2009年第二季度的误差率略高以外,其余季度的误差率均在5%左右,可以看出由该模型得到的预测值有较高的参考价值。
6. 结论
本文采用时间序列分解模型对全国卷烟市场销量进行了定量分析,通过对历史数据进行检验,结果较为理想,可以使用该模型对全国卷烟销量进行预测,对于正确制定卷烟营销策略有一定的帮助。该模型采用历史数据进行定量分析,相对于定性分析中以个人或专业集体的主观经验为依据来预测发展趋势更为客观。
Table 4. Comparison of historical data with predicted values
表4. 历史数据与预测值比较
本文的不足之处:一、确定性因素分解的方法把序列的变化都归于四个因素的综合影响,不能充分提取观察序列种的有效信息,可能会导致模型拟合的精度不够;二、由于烟草行业受国家政策影响较大,2015年国家颁布了相关的控烟政策,导致我国卷烟销量下降,由于2017年后的数据较少,仅用2004年至2016年季度数据来拟合模型,用历史数据来检测模型准确度,2017年后卷烟市场开始回暖,因此无法用该模型预测2017年后的全国卷烟销量,2017年后的卷烟销量预测需要更多的数据支持并且重新修改该模型参数后即可应用。