1. 引言
保证粮食安全是我国的基本国策,农业植保是农业生产中最重要的环节之一。而当前国内农业植保装备比较落后,农作物保护形式仍以人工、半机械化作业为主。据相关统计,我国目前使用的植保设备仍以手动和小型电动喷药机为主,其中手动施药药械、背负式机动药械分别占国内植保机械的93%和5.5%以上,拖拉机悬挂式植保机械占不到1% [1] 。传统农作物保护形式农药用量大,浪费严重,作业成本高,工作效率低,无法保障植保质量与作物质量产量,同时也带来了严重的环境污染等问题 [2] ,这与现代化农业发展的趋势相悖。更令人担心的是,传统植保作业方式易造成人身药害,据统计,每年有数十万人遭遇农药中毒事件,其致死率高达8.9% [3] 。为缓解上述问题,农业植保正在向更为现代化、专业化的方向发展。
在植保航空领域,美国、日本、澳大利亚等国处于领先地位。其中日本的情况与我国相似:人均耕地面积小,不适合有人驾驶的大型农用飞机进行作业 [4] [5] 。美国近些年在农业航空方面,应用了一系列的新技术 [6] [7] 。随着植保无人机应用走向市场,无人机植保作业量将会迅猛增加,如何快速匹配植保无人机用户租赁需求与农业生产用户植保作业需求至关重要。尽管在植保无人机监管系统中已有了多种便捷的植保作业检索方式,但是这一过程仍然需要用户主动去搜索,尚不够智能,尚无无人机植保作业匹配方法或系统发表。为了能够使无人机与植保作业的匹配更为便捷、有效,提升系统效率与用户体验,本文考虑利用用户行为日志设计一个科学、合理的无人机植保作业推荐算法,把可能感兴趣的植保作业推荐给用户,供用户选择。
日志分析可通过批量离线处理或实时计算来进行。离线批处理涉及Hadoop大数据处理技术,如薛文娟 [8] 设计了基于层次聚类的日志分析技术;杨锋英、刘会超 [9] 基于Hadoop的在线网络日志分析系统。而实时日志分析,需要用到常见的实时计算框架,如Spark、Storm、Dremel等,如刘季函 [10] 基于Spark的海量日志数据分析平台;屈国庆 [11] 基于Storm设计并实现了实时日志分析系统;孙思源 [12] 基于MongoDB分布式数据库的高效Web日志分析方案;陈飞、艾中良 [13] 基于Flume、ElasticSearch、Kibana等技术研究并实现了一种分布式的日志采集分析系统。由于植保作业的喷药期有比较严格的时间限制,为了能够及时计算出用户可能感兴趣的植保作业,本系统选择使用实时计算。而在实时计算框架中,常见的计算框架有Storm和SparkStreaming。Storm平台以其纯实时的流式计算、极高的运算速度、清晰的拓扑结构和编程接口而成为了工业界最流行的实时计算框架,与Spark相比它拥有更低的计算延迟、更完善的事务机制、更好的健壮性,但吞吐量相较逊色。考虑到植保作业推荐系统对于高实时性、高可用性的需求,本文选择Storm。
前人针对推荐算法的研究成果为本文设计提供了可贵的借鉴。王嫣然 [14] 等设计了基于内容过滤的科技文献推荐算法;庄景明 [15] 等将内容过滤算法应用在农业信息推荐系统上;袁先虎 [16] 设计了基于混合用户模型的协同过滤推荐算法;胡勋 [17] 等混合了内容推荐算法与基于用户的协同过滤算法;刘树栋 [18] 等基于位置设计了社会化网络推荐系统。推荐系统已成为最重要的个性化技术发展方向 [19] [20] 。在植保无人机用户匹配植保作业的过程中,需要将农业作业的地理空间属性、作业时间属性以及用户属性均考虑在内,才能获得较为理想的作业推荐算法。通过研究与实践,本文基于Strom框架设计、采用内容过滤算法、协同过滤算法、以及多种方法混合的推荐算法最终实现了一个智能化的无人机作业快速推荐算法。
2. 材料与方法
2.1. Storm技术
Storm是一个分布式的流式数据处理系统 [21] 。Storm内部组件处理流程图如图1所示。它把任务分配给不同的任务处理流,流中的每个组件负责处理一项特定的任务。Storm中的数据接收单元为Spout,每个Spout都会把数据传递给一个或多个数据处理单元Bolt,经过处理后Bolt把数据保存到某存储器中,或者传递给其他的Bolt继续进行处理,数据就如流水一样经过这些组件,完成整体处理流程。
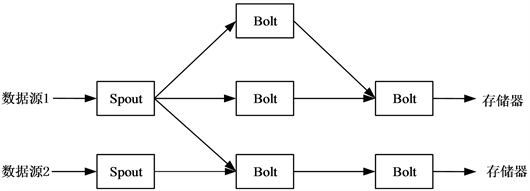
Figure 1.The processing flow of Storm’s internal components
图1. Storm内部组件处理流程图
2.2. 日志获取
在本文开发的植保无人机飞行监管系统中,为了实现植保无人机作业推荐,设计了相应字段来记录无人机用户对植保作业的操作内容作为日志信息,如表1。
利用以上信息,一方面可以计算出用户对哪一类的植保作业比较感兴趣;另一方面可以利用基于用户的协同过滤算法计算出用户之间的相似度,并以此作为植保作业推荐的依据。
2.3. 作业推荐算法
2.3.1. 协同过滤算法
协同过滤算法包括基于记忆的协同过滤和基于模型的协同过滤 [22] 。对于农业植保作业用户来说,根据其无人机的不同类型、植保作业类型以及执行项目所在区域等信息可较为精确地定位植保作业用户的适宜项目,因此本研究采用基于记忆的协同过滤算法实现用户作业推荐。
基于记忆的协同过滤算法具体分为基于用户的协同过滤和基于项目的协同过滤。基于用户的协同过滤根据用户之间的相似性来互相推荐可能感兴趣的项目,其原理如图2(a)所示。假设用户X喜好项目1和3,用户Y喜好项目2和4,用户Z喜好项目1、3和4。从这些历史喜好中,可以推论用户X和用户Z具有相似偏好。由于用户Z还喜好项目4,那么用户X也可能喜好项目4,因此可以向用户X推荐项目4。
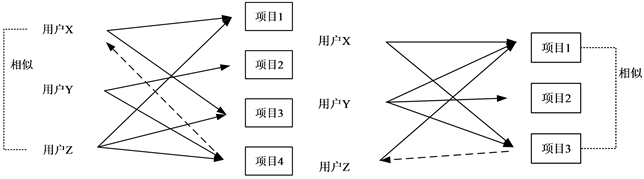 (a) (b)注:虚线段表示相似的用户或项目,实线箭头表示用户喜好,虚线箭头表示向用户推荐
(a) (b)注:虚线段表示相似的用户或项目,实线箭头表示用户喜好,虚线箭头表示向用户推荐
Figure 2. The principle of collaborative filtering based on memory
图2. 基于记忆的协同过滤原理
图2(b)中展示了基于项目的协同过滤。用户X喜好项目1和3,用户Y喜好项目1、2和3,用户Z喜好项目1。从这些历史记录可发现,喜好项目1的用户大多同时也喜好项目3,因此可以认为项目1和3类似,而用户Z喜好项目1,因此可以把项目3推荐给他。
2.3.2. 内容过滤算法和人口统计学算法
内容过滤算法根据用户的喜好记录分析出喜爱哪一类的项目,最后便可以把这一类项目推荐给用户,其原理如图3所示。假设用户X喜好项目1,通过相似度计算,发现项目1和3具有较高相似,由此推论,用户X也喜好项目3。于是将项目3推荐给用户X。
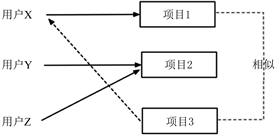
Figure 3. The Content filtering recommendation
图3. 基于内容过滤推荐原理

Figure 4. The Demographics recommendation
图4. 基于人口统计学推荐原理
图4中展示了基于人口统计学推荐算法,根据特征计算用户间的相似度,用户X喜好项目1,系统通过计算发现用户X和Z具有较高相似度,就会把用户X喜好的项目推荐给Z。
3. 设计与实现
3.1. 基于Storm框架的日志实时计算系统搭建
为了搭建分布式日志实时分析系统,在单台服务器上部署了4台虚拟机,分别命名为node1,node2,node3,node4,这些虚拟机承担着Web服务器和日志分析的任务。其中,Web服务器部署在node1上,作为网站的主节点;Flume为单点部署,部署在node1,方便日志的收集;Kafka为分布式部署,共3台虚拟机,分别部署在node2,node3,node4上;Storm为分布式部署,共4台虚拟机,其中node1为Master节点,即Nimbus;而node2、node3、node4则为Worker节点,即Supervisor;Zookeeper分布式集群管理组件共3台虚拟机,分别部署在node2、node3、node4上。系统拓扑结构如图5所示。

Figure 5. Topological diagram of plant protection operation recommendation system
图5. 基于日志分析的植保作业推荐系统拓扑图
3.2. 混合用户特征与协同过滤的植保作业推荐算法
考虑到植保作业和无人机都有着较强的地理属性,而无人机仅能在有限的地理范围进行服务,这意味着一般来说无人机只为本地的植保作业提供服务。因此,无人机所属的地理因素强烈地影响着用户对于植保作业的偏好,本系统默认无人机的位置即用户的位置,因此用户地理位置可以作为用户特征,以人口统计学推荐算法进行推荐。本文将人口统计学推荐与基于用户的协同过滤推荐相结合,以取得改进的效果。本文取植保作业记录并混合用户地理属性来计算用户相似度,具体用户作业评分数据结构为:
{用户ID:{同省:分值,同市:分值,同区:分值,作业1:分值,作业2:分值,作业3:分值},… }
获得了目标用户与其他用户的上述评分结构后,就需要计算哪个用户距离当前最近。在计算 最近邻时,皮尔逊相关系数和余弦夹角相似度都可用于离散评分和连续评分。皮尔逊相关系数主要用于衡量用户公共评分的相关程度 [23] ,但由于植保作业推荐算法混合了基于用户特征的推荐,因此获取的某些记录可能与目标用户不存在公共评分,因此本文选用余弦夹角相似度算法,具体计算方法如式(1)所示。
(式1)
式中,c与v分别代表两个用户,
代表两个用户之间的相似度。二者的评分向量分别为
和
。
计算出目标用户与其他用户的相似度评分后,将结果排序,分值范围在0~1之间,分值越高,相关程度越好。排序后选择固定数量的最近邻用户,通过最近邻来进行评分并预测目标用户可能感兴趣的项目(植保作业)。此时采用加权求和方法,计算得到的相似度作为评分的权重,所有相似度的加权评分总和即为结果。最后将相关植保作业评分排序,取前若干条作业作为推荐结果,具体流程见图6。

Figure 6. The plant protection operation recommendation algorithm based on mixing user characteristics and collaborative filtering
图6. 混合用户特征与协同过滤的植保作业推荐算法流程图
3.3. 基于内容过滤的植保作业推荐算法
在推荐植保作业时,首先从MySQL数据库中,获取该用户的地理偏好因素的最新一条记录,利用记录的地理位置偏好坐标,在植保作业R树空间索引中搜索该坐标附近的若干条植保作业。而作为相对次要的植保类型偏好和作物类型偏好,将影响已经获得的若干条植保作业的排序。首先从MySQL数据库中,获取最新若干条的该用户的类型偏好因素记录,统计出用户最感兴趣的植保类型和最感兴趣的作物类型。然后对已经从R树中获取的若干条植保作业进行排序,排序规则如下:用户最为感兴趣的植保类型的作业排在靠前,不是的排在靠后;而在前两部分中,用户感兴趣的作物类型排在靠前,不是的排在靠后。基于内容过滤的植保作业推荐算法流程图如图7所示:
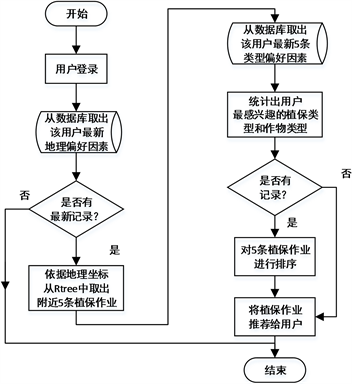
Figure 7. The plant protection operation recommendation algorithm based on content filtering
图7. 基于内容过滤的植保作业推荐算法流程图
4. 结果与分析
4.1. 混合用户特征与协同过滤的植保作业推荐结果与分析
首先测试了目标用户是新注册用户。用户2与3有相关操作记录。按照规则,在目标用户没有记录时,仅按照用户之间的行政区划位置关系来评价相似度,用户2的评分应比用户3 的评分高。经过余弦相似度计算用户2为1分,用户3为0.816分,作业A到作业E的加权分数分别为:8.16、9.08、10、4.08、10分。
接着测试了目标用户已有对植保作业操作的情况,用户2与3有相关操作记录,目标用户则申请了作业A和D,可见目标用户与3更为相似。此时同时考虑作业记录的相似度和行政区划位置的相似度。经过余弦相似度计算用户2为0.775分,用户3为0.868分,作业B、作业C、作业E的加权评分分别为8.21、7.75、7.75分。为了对比,做如下测试,测试数据描述如表2所示。
目标用户申请了作业A和D,目标用户与用户1和3比较相似。同时考虑作业记录的相似度和行政区划位置的相似度。经过余弦相似度计算用户1为0.956分,用户2为0.775分,用户3为0.868分,作业B、作业C、作业E的加权评分分别为8.21、7.75、17.30分。目标用户得到的结果如图8所示。
从上述测试结果可以看出,混合用户特征与协同过滤的植保作业推荐算法,能够计算出与目标用户相似度最好的邻居用户,并能够预测出与目标用户评分最高的植保作业,即目标用户最可能感兴趣的植保作业。此外,由于混合了用户特征中地理位置这一属性,使得本算法在一定程度上缓解了协同过滤算法的冷启动问题:新注册用户无需对植保作业进行操作,只要附近有其他的用户有过操作记录,就可得到推荐结果。
4.2. 基于内容过滤的植保作业推荐结果与分析
本文在实验中设计了一些模拟数据,分布在北京市海淀区和东城区等地。对基于行政区划搜索日志的推荐进行实验,模拟了用户利用行政区划搜索植保作业,对北京海淀区的植保作业进行了筛选,之后返回首页。推荐了海淀区中心点附近5条植保作业。此时仅按照距离远近排序,最近的排在最上。接着又搜索了北京市朝阳区的植保作业,距离朝阳区中心点最近的5条作业。由此可以得出结论,基于行政区划搜索日志的推荐可以根据用户搜索的不同地点而更有针对性地推荐附近的植保作业。对基于Rtree的区域搜索日志的推荐结果进行了验证。首先利用区域搜索植保作业功能,搜索了海淀区香山一带的植保作业。又搜索东城区东直门一带的植保作业,推荐结果如图9所示。

Figure 9. Recommendation results based on Rtree region search log (Beijing, Dongcheng District, Dongzhimen)
图9. 基于Rtree区域搜索日志的推荐结果(北京市东城区东直门)
由此可以得出结论,基于Rtree区域搜索日志的推荐可以根据用户搜索的不同区域而有针对性地推荐附近的植保作业。
验证类型偏好的推荐结果,本文通过点击查看多个植保作业详情获得了相关模拟数据。首先查看了作业类型为液态药,作物类型为高秆作物的作业。对比可见,在查看了液态药、高秆作物的植保作业后,推荐结果得到了正确的排序结果。首先液态药作业类型排在靠前的位置,粉状药靠后,其次高秆作物排在靠前,果树排在靠后。接着,又查看了粉状药、高秆作物的植保作业和粉状药、果树的植保作业。结果如图10所示。首先粉状药作业类型排在靠前的位置,液态药靠后,其次高秆作物排在靠前,果树排在靠后。实验显示该算法得到了正确的结果。

Figure 10. Recommendation results based on type preference (Beijing, Dongcheng District, Dongzhimen)
图10. 基于类型偏好的推荐结果(北京市东城区东直门)
5. 结论
本文研究并实现了基于日志处理的高效、可靠的无人机植保作业推荐算法,该推荐算法提高了植保无人机飞行监管系统的可用性、实用性、便利性和智能性,对于充分优化资源配置和保障农作物植保作业具有重要意义和实用价值。系统经过验证和实验,得出结论如下:
1) 混合用户特征和协同过滤的植保作业推荐算法,能够计算出与目标用户最相似的邻居用户,并能够基于此计算出目标用户可能评分最高的植保作业,并推荐给用户;基于内容过滤的植保作业推荐,基于用户的搜索与查看记录,能够为用户推荐可能感兴趣的植保作业。本文推荐算法能够产生正确且有意义的推荐结果,说明其具有智能性。
2) 使用Strorm框架实现了植保无人机监管和作业推荐系统,其具有较好的实时性、便捷性以及实用性。
3) 目前仅设计了针对植保无人机用户的植保作业推荐算法,未来可以为农业生产用户提供植保无人机的推荐,让双方都能获得理想的推荐结果。
致谢
感谢郑立华老师及所有在写作期间给予我指导的老师们!
基金项目
北京市科委重大专项——智能型农业植保无人直升机系统研发及工程应用(D1511000012150002)。
NOTES
*通讯作者。