1. 引言
布尔网络是描述人工智能系统、神经网络系统、基因调控网络等的一种简单可行工具 [1] [2] [3] [4] ,在1969年,Kauffman首次提出用布尔网络来描述、模拟基因网络 [5] ,但是由于布尔网络在描述一些实际问题时难免会有一定的局限性,例如:温度高低,天气阴晴,人的年龄老少等,因此,这时,多值逻辑网络和混合值逻辑网络应运而生。在一定程度上,多值逻辑网络是布尔网络的自然推广。同时逻辑网络在博弈论中也有应用。在一个网络演化博弈中,当局中人的对策是多个或者不同多个时,我们可以用多值逻辑网络来建模,详细结果参见 [6] [7] [8] 。2011年程代展及其团队提出了矩阵半张量积的概念,将传统的普通矩阵乘法推广到一般的矩阵上,即,不再需要前一个矩阵的列数与后一个矩阵的行数相等,然而它却保持着矩阵的普通乘积的基本性质。这种工具有效地将逻辑表达融入到基本的数学运算框架中,在专著 [9] [10] [11] 中详细介绍了矩阵的半张量积的定义与性质,并讨论了其在非线性系统、布尔网络、模糊逻辑等领域中的应用。
多值逻辑网络比布尔网络的应用更为广泛,所以在研究多值逻辑网络时同样可应用矩阵的半张量积。如文献 [12] 讨论了如何从演化动态博弈导出多值逻辑系统的优化控制问题,并在多值逻辑系统下讨论平均收益和带贴因子的总收益两种性能指标下的最优控制的基本结论和算法,同时从逻辑动态系统的最优控制中导出演化博弈的纳什均衡。文献 [13] 在博弈理论框架下对无穷时域上逻辑控制网络的最优控制问题进行求解。讨论逻辑控制网络的代数形式下对周期的计算。文献 [14] 研究了人与机器之间重复无穷的囚徒困境模型,从逻辑控制网络的代数形式出发,讨论逻辑控制网络的拓扑结构,最后将这一结果推广到带有记忆的博弈中。文献 [15] 研究了兼具逻辑表达式和代数表达式的布尔网络的最优控制问题。经查阅相关文献,对有限博弈的最优收益问题研究比较少,因其系统是逻辑形式描述,而目标泛函须用代数式表达,将逻辑表达式和代数表达式在统一的框架下处理有一定的难度。本文利用矩阵半张量积的方法研究了多值逻辑网络的最优收益问题,将多值逻辑动态表达式转化为对应的半张量形式,在此基础上给出目标泛函的半张量形式,得到等价的半张量形式的最优控制问题,进而利用动态规划法求解半张量系统的最优控制问题,再根据等价公式得到系统的最优解。最后给出一个算例。
2. 准备知识
在这一节里,我们将本文的符号,涉及到的半张量积的定义和性质总结归纳如下。
2.1. 符号的说明
为叙述方便,做以下的符号说明:
l
维实矩阵集合;
l
;
注:在博弈中也用
这时,将
,即可
l
为单位阵
的第k列;
l
:为矩阵A的第i列,矩阵A的列集合记作
;
l
;这里
;
l 一个矩阵
称为逻辑矩阵,如果它的列满足
;
l 矩阵
,记为v。
2.2. 矩阵的半张量积的定义及性质
定义2.2.1 [9] :设
和
。记n与p的最小公倍数为
定义A与B的半张量积为
这里
是矩阵的Kronecker积(亦称张量积)。
注:当
时,矩阵
满足等维条件,定义化为普通矩阵乘法,因此,半张量积是普通乘法的推广。本文所说的半张量积均为左半张量积。
命题2.2.1 [9] :若
,则矩阵半张量积满足
1) 结合律
2) 分配律
命题2.2.2 [9] :设
和
,关于半张量积的置换,有:
为了进一步实现交换运算,为此定义换位矩阵。
定义2.2.2 [9] :换位矩阵
是一个
矩阵,定义如下:它的行和列都是由双指标
标注,列是按照索引
排列,行是由双指标
标注按照索引
排列,并且位于
上的元素的值为
当
时,我们简记
。
命题2.2.3 [9] :设
。则
其中
称为k维降价矩阵。
利用降价矩阵与换位矩阵,我们可以降低计算逻辑函数的结构矩阵的计算量。
通过换位矩阵,引入半张量积的重要性质——伪交换性。
命题2.2.4 [9] :给定矩阵
,
设
为行向量,则
设
为列向量,则
设两个行向量
,
,则
设两个列向量
,
,则
2.3. 博弈的定义
本文只关心有限博弈。
定义2.3.1 [16] :一个(有限)正规博弈,有三个部分组成:
,其中
1)
表示这里有n玩家(局中人);
2)
称为局势,其中
是第i个玩家的策略集,它表示第i个玩家有
个策略可供选择,局势是所有玩家策略的笛卡尔积。
3)
,其中
是第i个玩家的收益函数为方便计,策略集通常记
这里“有限”博弈指:
a) 玩家数
,
b) 策略数
3. 多值逻辑网络最大收益问题
本文我们考虑单输入输出有限博弈(参与者与行动集有限)的动态过程,并假定部分玩家被视为“机器”,其策略固定已知,另一部分玩家作为“人”,他的策略选择的准则是使其收益最大化。本文讨论所有玩家的策略都只有1步记忆的情形。
根据如上假设,此类博弈问题可以转化为下面的多值逻辑控制网络的优化问题。
控制系统为:
(1)
其中 为状态表示k时刻“机器”采取的行动;
为状态表示k时刻“机器”采取的行动; 为控制输入表示k时刻“人”采取的行动,“机器”的策略f为从
为控制输入表示k时刻“人”采取的行动,“机器”的策略f为从 到
到 的多值逻辑函数,即:
的多值逻辑函数,即:

容许控制集为:

最优控制问题(P):假设初始时刻 、初端
、初端 和终端时刻
和终端时刻 已定,终端满足约束
已定,终端满足约束

机器策略 按(1)更新的情况下,寻找人的最佳策略
按(1)更新的情况下,寻找人的最佳策略 ,使得系统状态从给定的初始状
,使得系统状态从给定的初始状 到N时刻达到给定的终端状态
到N时刻达到给定的终端状态 ,并使得目标泛函最大化
,并使得目标泛函最大化
 (2)
(2)
其中c为每一步的收益函数, 为折扣因子。
为折扣因子。
针对这种多值逻辑控制的最优控制问题不但包含状态系统的逻辑运算,而且又包含了性能指标的代数运算,如果仅仅只有单一的逻辑系统或一般最优控制方法是很难解决的,为解决此类问题。我们引入矩阵半张量工具将逻辑动态网络转化为对应的代数状态方程。
4. 多值控制网络最大收益问题的半张量方法及其问题的求解
4.1. 多值控制网络最大收益问题的半张量表示
定理4.1.1 [9] :给定一个n元多值逻辑函数 ,则存在一个唯一的逻辑矩阵
,则存在一个唯一的逻辑矩阵 ,使得f在半张量形式下可表示为
,使得f在半张量形式下可表示为
 (3)
(3)
这里, ,
, 称为f的结构矩阵。称上式为多值逻辑函数f的代数形式。
称为f的结构矩阵。称上式为多值逻辑函数f的代数形式。
根据定理以及矩阵半张量积的性质,问题(P)可以等价表示为如下问题:
状态方程

其中
初始状态 ,终端
,终端 容许控制集
容许控制集
收益函数所对应的半张量形式为:
目标泛函为
 (4)
(4)
(P为 对应的收益矩阵,
对应的收益矩阵, ;即:“人”相对于“机器”的收益值)。
;即:“人”相对于“机器”的收益值)。
最优控制问题 :寻找
:寻找

4.2. 最优控制问题的求解
变分法、庞特里亚金最大值原理、动态规划法是求解最优控制问题经典的三种方法,本文采用动态规划法求解离散系统的最优控制问题。针对半张量积表示的最优控制问题( ),有如下定理:
),有如下定理:
定理4.2.1:若 是最优策略,则对于任意
是最优策略,则对于任意 。它的子策略
。它的子策略 对于
对于 ,
, 确定的
确定的 为起点的第k到N后部子过程而言,也是最优策略。
为起点的第k到N后部子过程而言,也是最优策略。
证明:以max为例证明此定理,反证法:
假设子策略 对于
对于 ,
, 确定的
确定的 为起点的第k到N后部子过程而言,不是最优策略。则必定存在
为起点的第k到N后部子过程而言,不是最优策略。则必定存在 和策略
和策略 ,使得
,使得

令 ,则
,则

这与 是最优策略矛盾。证毕。
是最优策略矛盾。证毕。
下面我们将定理4.2.1的思想,转化为可计算的递归算法。对于任意给定的 和
和 ,考虑如下的受控系统
,考虑如下的受控系统
 (5)
(5)
设其性能指标为
则最优控制问题 为:对于给定
为:对于给定 ,
, 对于系统(5)找到策略
对于系统(5)找到策略 ,使得
,使得 ,并
,并
当 且
且 时,问题
时,问题 即为我们需求的最优控制问题
即为我们需求的最优控制问题 ,定义如下值函数:
,定义如下值函数:
 (6)
(6)
则有如下定理:
定理4.2.2:对 ,有
,有
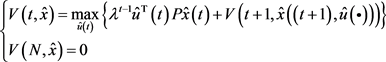

证明:由值函数 的定义可知:
的定义可知:

两端关于序列 取最大泛函
取最大泛函

对任何序列 ,有
,有

证毕。
4.3. 动态规划算法
根据定理4.2.2,我们容易得到如下算法。
逆推算法4.3.1:
Step 1:利用终端条件 开始由后向前逆推基本方程,计算出最优收益函数
开始由后向前逆推基本方程,计算出最优收益函数 ,最后通过计算
,最后通过计算 从而得到最优决策序列
从而得到最优决策序列

Step 2:根据状态方程 和初始条件
和初始条件 ,从
,从 开始由前向后确定
开始由前向后确定 。
。
应用此算法通过反复的迭代和回代从而得到
最优轨线
最优策略
4.4. 应用实例
考虑有限的人机博弈,双方均有三个可选择的策略 。支付双矩阵见表1。
。支付双矩阵见表1。
这里机器采取的策略为:在本次博弈中如果赢或平,下次不改变策略,如果本次博弈输,则下次采用对手的策略。
给定初始状态 ,终端状态
,终端状态 ;性能指标为
;性能指标为

其中, 为逻辑变量表示机器的策略,
为逻辑变量表示机器的策略, 为控制变量表示人的策略,
为控制变量表示人的策略, 为人的收益函数,求使性能指标最大的控制序列。
为人的收益函数,求使性能指标最大的控制序列。
解:令 ,
, ,
, ,则上述博弈可以写成
,则上述博弈可以写成

其中

 为状态变量,表示机器t时刻的策略。
为状态变量,表示机器t时刻的策略。
 为状态变量,表示人t时刻的策略。
为状态变量,表示人t时刻的策略。
初始条件 ,终端
,终端 性能指标
性能指标

求使性能指标最大的控制序列 。
。
应用动态规划法求解

有, 。
。
当 时,
时, 取最大值为,其值为:
取最大值为,其值为:

有, 。
。
则当取 时,
时, 取得最大值,其值为:
取得最大值,其值为:

有, 。
。
则当取 时,
时, 取得最大值,其值为:
取得最大值,其值为: 。
。
因此所求的最优控制序列为: ,最优轨线为:
,最优轨线为: ,性能指标为
,性能指标为 。
。
将向量转化为标量则最优控制序列为: ,最优轨线为:
,最优轨线为:
 ,性能指标
,性能指标 为:
为: 。则人的最大收益为:
。则人的最大收益为: 。
。
注4.4.1:本文只研究了单输入输出的决策最优控制问题,本文所应用的定理和算法对于多输入多输系统的决策最优控制问题仍然适用。
5. 总结
本文研究了有限动态博弈过程中多值逻辑控制网络的收益优化问题,利用矩阵半张量积的方法将逻辑系统转化为对应的代数系统,并给出了半张量形式下目标泛函的表达式。在引入值函数的情况下对其最优性原理进行了证明并给出了算法,同时举例说明算法的有效性。
基金项目
国家自然科学基金(No. 11761021),贵州民族大学科研基金资助项目(No. 2017ZD017)。