1. 引言
当某一测量值受多种因素的随机影响时,该值常呈对数正态分布,对数正态分布在实际中有着重要的应用,例如它主要被广泛的用于描述如在金融市场的理论研究中,著名的期权定价公式以及许多实证研究都用对数正态分布来描述金融资产的价格。另外在工程、医学和生物学领域里对数正态分布也有着广泛的应用,很多研究都会用它来拟合寿命数据以及人口收入数据。往往人们会得到不同背景下的服从对数正态分布的数据,对于这些有着共同均值的不同总体,我们会充分利用他们之间的信息,来估计共同均值,这就是本文所研究的内容。
2. 广义枢轴量和广义置信区间
定义1:对数正态分布
若随机变量
,则随机变量
服从两参数的对数正态分布,其密度函数为:
其均值
。
2.1. 广义枢轴量和广义置信区间
定义2:广义枢轴量和广义置信区间
形如
的广义枢轴量是X,x和
的参数,其中
,
是兴趣参数,
是讨厌参数,并且满足以下条件:
1) 对给定的
,
的分布与未知参数
无关;
2) 观测值
与讨厌参数
无关。
假设给定广义枢轴量
和置信系数
,寻找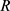 的样本空间的一个子集
,使得
的样本空间的一个子集
,使得
取
则称
为参数
的一个置信系数为
的广义置信区间。
广义枢轴量法解决了传统枢轴量法无法解决的问题,即当分布含有讨厌参数时枢轴量很难或者无法构造的问题。
事实上,广义检验变量
和广义枢轴量
之间有如下关系:
,其中
为兴趣参数的函数,因此可以通过构造广义枢轴量的方法来进行假设检验,且其相应的广义
值可以通过二者的关系计算得到。
2.2. Fiducial广义枢轴量
定义3:Fiducial广义枢轴量
设
是关于X,x和
的参数,其中
,
是兴趣参数,
是讨厌参数,并且满足以下条件:
1) 对给定的
,
的分布与未知参数
无关;
2) 观测值
。
则称
为兴趣参数
的Fiducial广义枢轴量。
可以看出Fiducial广义枢轴量是广义枢轴量的特殊情况,这也使得Fiducial广义枢轴量可以通过构造参数的Fiducial分布得到,且已经有了较为成熟的构造方法,下面的部分将主要通过实例来做假设检验问题。
3. 提出的方法
3.1. 广义枢轴量的构造
考虑
个独立的有公共均值
的对数正态总体。令
是从第
个对数正态总体中抽取的随机样本,且有:
,因此我们有:
,
。
令
和
分别表示从第
个对数正态总体样本数据做对数转换后的均值与方差,
,且令
和
分别表示他们的观测值。由于:
其中
是服从标准正态分布的随机变量,
是服从自由度为
的卡方分布的随机变量,且两者相互独立。因此可以构造广义枢轴量:
, (1)
(2)
因此
(3)
对于第
个总体,其极大似然估计为
[4] , (4)
其中
,
。
的样本方差可以近似为:
[5] (5)
从而我们所研究的对数正态的均值
的广义枢轴量是基于
个广义枢轴量
的加权平均值,具体形式如下:
, (6)
其中:
(7)
(8)
3.2. 算法
对给定的观测值 :
:
1) 计算
和
,
。
2) 产生
的实现值,然后按(1)给出的公式计算
,
。
3) 产生
和
的相互独立的实现值,然后根据(2)给出的公式计算
,
。
4) 根据公式(3)计算
,
。
5) 重复步骤2~3共
次,根据公式(7)和(8)计算
。
6) 根据公式(6)计算得到
。
7) 重复步骤2~6共m次,得到一系列
。
8) 将这以系列
案从小到大排列。
通过得到的有序的
数列,取其2.5%分位点与97.5%分位点,得到
的置信水平为95%的置信区间。
4. 模拟研究与结论
在本次模拟实验中,取总体个数为2个,样本量分别为
,作了对数变换后的数据的总体均值我们定,为
和
,共同均值
的值取0.3,0.5,0.8,1.0,1.2,1.5和2.0。下面以表格的形式对比广义推断的方法与大样本方法得到的95%置信区间的覆盖率,见表1。
其中比率是两总体参数
的比率:
。

Table 1. Empirical coverage probabilities of 90 percent two-sided confidence bounds for the common mean
表1. 共同均值θ的置信水平为95%的双侧置信区间的主要覆盖率
从上述结果来看,当样本量较小时,广义枢轴量的方法的真实覆盖水平明显高于大样本方法,显示出其良好的估计性能。当样本量逐渐增加时,大样本的优良效果逐渐明显,广义枢轴量的方法仍具有良好的性能。