1. 引言
随着金融市场的风险持续增加,金融风险管理已成为了预防风险,化解风险和维护市场稳定快速发展的重要内容,而风险度量也随之而生。
度量股票风险的方法很多,在险价值VaR (Value at Risk)是最近发展起来并被广泛应用的一种度量股票风险的方法。VaR基于概率统计理论的基本知识,采用适当、科学合理的数学模型,借助先进的计算机技术,对市场的数据进行分析和计算,能更加精确地对市场金融风险进行度量,而且易于操作,还能综合反映市场各方面的风险状况,因此得到了相关金融机构和监管部门的广泛的应用。计算VaR的方法分为参数方法、非参数方法和半参数方法三种。参数方法需要假设收益率的分布形式,一般假设为正态分布或者t分布,相应的模型为方差–协方差模型、GARCH族模型等。非参数方法无需提前假定收益率的分布。由于金融市场的复杂性和不完善,经过统计检验,中国大陆股市的对数收益率大多不符合正态分布,而具有尖峰厚尾特征。
本文对所研究的数据的分布形式进行检验,发现9只股票的对数收益率均不服从正态分布,但都服从t分布,因此本文对所考虑的9只股票分别用参数方法和非参数方法计算在险价值VaR。具体地说,给定一定置信水平时,应用GARCH族模型和分位数回归模型两种方法度量股票的VaR,并运用事后检验的方法对模型结果的有效性及精度进行比较,发现基于分位数回归模型计算得到的VaR值精度较高。
本文内容安排如下:首先介绍VaR、应用GARCH族模型和分位数回归模型计算股票VaR的基本原理,然后对市场数据进行实证分析,分别应用这两种模型对VaR进行计算。
2. 在险价值VaR
2.1. VaR的定义
VaR通常定义为:给定置信水平
,某一金融资产或投资组合在未来特定时间段内所面临的最大可能损失 [1] 。VaR的值非负。从统计学角度上讲,VaR的定义为:
(1)
其中:prob表示随机事件的概率,Y表示资产(或投资组合)收益,收益为负时代表损失。VaR表示置信水平
下的资产的VaR值。VaR的值等于指定时间段内资产(或投资组合)收益率分布的分位点 [1] 。
2.2. 基于GARCH族模型的VaR计算方法
依据是否假设收益率数据的分布情况,将度量VaR的方法分为参数法(如方差–协方差法、GARCH族模型等),非参数法(如历史模拟法、Bootstrap法等)和半参数法(如CAViaR等)三种 [2] 。其中GARCH族模型可以生动的描述资产(或投资组合)收益率的波动情况,这与其VaR值有着紧密的联系,以下是常用的GARCH族模型。
Robert Engle在1982年提出了ARCH模型,但是为了充分描述数据的波动情况,1986年Bollerslev建立了GARCH(p,q)模型,其满足如下方程:
其中:
代表收益率序列,
代表资产收益率的无条件期望,
代表随机误差项,
代表期望为0,方差为1的独立同分布的随机变量族,
为随机误差项
的条件标准差,
为滞后系数,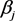 为方差系数 [3] 。
为方差系数 [3] 。
若假设资产收益服从t-GARCH(1,1),在置信度水平
下,VaR为:
,其中:
,则
,
为收益率
所满足的待估参数为
的t分布的下
分位数。
3. 基于分位数回归的VaR模型
3.1. 分位数回归的基本思想
Koenker与Bassett在1978年研究了分位数回归方法,在很大程度上解决了最小二乘估计的局限性。分位数回归没有假定误差项所满足的分布形式,它在被解释变量的条件分位数对解释变量进行回归的同时考虑了误差项的异方差性 [4] 。
对于随机变量
(d为正整数),设n次样本观测值为
,已知x,则y的条件
分位数函数为:
表示已知x的条件下y的分布函数,
表示预先设定的分位点。线性分位数回归的
条件分位数函数为:
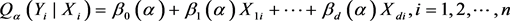
其中
是
个未知参数 [5] 。
分位数回归模型的参数估计值为使得加权残差绝对值之和最小的数值,则
分位数的样本分位数线性回归需满足以下条件:
其中定义损益函数为
[6] [7] 。
3.2. 分位数回归VaR模型
一般的VaR求解方法通常认为金融资产的收益率分布为正态分布,但实际情况下其分布形式大体存在着尖峰,厚尾的特征,不满足正态条件。VaR可以看作资产(或投资组合)的收益率分布的分位数,而分位数回归方法是分析不同分位点上解释变量对被解释变量的影响程度,且不需要考虑解释变量的分布形式,因此采用分位数回归的方法计算金融资产的VaR。
Koenker和Zhao提出了Quantile-ARCH模型 [5] ,其回归模型如下:
(2)
并且其误差项
满足:
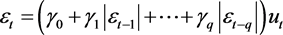 (3)
(3)
其中,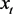 是
维向量回归因子,且其第一个元素正则化为1,
,
和
均为未知参数向量,同时
定义为一组独立同分布随机变量且其均值为0,方差为常数 [5] 。
是
维向量回归因子,且其第一个元素正则化为1,
,
和
均为未知参数向量,同时
定义为一组独立同分布随机变量且其均值为0,方差为常数 [5] 。
定义
是t−1时刻的信息集,
。在ARCH模型中,
通常包含因变量
的滞后值,例如,
可以表示为
,这里
且
是一些外生解释变量 [5] 。
在
已知的情况下,
的条件
分位数为:
(4)
其中,
和
分别是
和
的条件
分位点。令
,则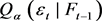 可表示为:
可表示为:
(5)
其中:
是
的
分位点。
由VaR定义可知,在信息
下
的VaR表示为:
(6)
从表达式(3.5)可以得到,
的VaR等于它的
分位点,则根据表达式(4)和(5)可以求得:
(7)
4. 实证分析
4.1. 数据选取
本文从主板市场,中小板市场,创业板市场各选取了三只大盘股2016年1月4日到2017年12月31日的收益率数据,其中远兴能源、上汽集团和平安银行选自主板市场,科伦药业、巨轮智能和煌上煌选自中小板市场,阳光电源、同花顺和上海钢联选自创业板市场。利用R语言编程,根据数据特点选取对应的方法计算股票的VaR值并对不同的计算方法进行了事后检验。数据来源于RESSET金融研究数据库。
4.2. 基本统计特征分析
我们首先对数据进行了初步分析,选取2016年1月4日到2017年12月31日9只股票每日的收益率数据为样本,其中收益率为:
(
为当天的收盘价,
为前一天的收盘价),对其进行了简单的描述性统计分析,其基本描述性统计特征值如表1所示。
从表1可以看出,9只股票的收益率均值都很小,在0上下浮动,其中巨轮智能,同花顺和上海钢联的收益率均值为负,从偏度可以看出,9只股票的收益率分布存在有偏性,其中远兴能源,科伦药业,阳光能源和上海钢联的收益率序列相对正态分布呈左偏性,其余股票的收益率数据呈右偏性,而远兴能
源,上汽集团,平安银行,科伦药业,巨轮智能,同花顺和上海钢联的峰度均大于标准正态分布的峰度3,和正态分布相比,其收益率的分布峰度较高,尾部较厚。
对9只股票进行Jarque-Bera检验,这一检验基于正态分布的偏度为0,峰度为3。假设
是一组独立同分布的数据,则JB检验统计量定义为:
(8)
其中:n表示样本数量,S表示偏度,K表示峰度。若假定数据取自满足正态分布的总体,则JB统计量近似满足自由度为2的卡方分布,若检验p值小于指定的概率值,则拒绝样本服从正态分布的原假设 [8] 。由表1可以看出,J-B检验得到的p值都远远小于2.2e−1,拒绝原假设,则9只股票的收益率数据的分布均不是正态分布。
4.3. 平稳性检验
对9只股票的收益率数据进行建模前,首先要检验收益率数据的平稳情况,采取了ADF,PP,KPSS三种检验方法,其中ADF和PP方法的H0:原始序列存在单位根,而KPSS方法的H0:原始序列是平稳的,检验结果如表2所示。
从表2可以看出,9只股票的ADF和PP方法的p值均为0.01,故拒绝原假设,认为9只股票的收益率数据均是平稳的,KPSS方法得到的p值均为0.1,不能拒绝原假设,故认为原始序列是平稳的,综上可知9只股票的收益率数据均为平稳序列。
4.4. 条件异方差检验
对9只股票的收益率序列建立均值方程: 。
。
其中,
为t时刻的股票收益率,
为条件均值,
为均值,
为随机干扰项。计算生成残差序列,然后对残差平方进行ARCH-LM检验,LM检验的基本思想为:如果残差序列表现出异方差性,那么残差平方序列之间有相关关系。H0:残差平方序列之间互不相关,H1:残差平方序列存在异方差性。当检验p值小于指定的概率值时,拒绝H0,则该残差平方序列之间有相关关系。
根据LM检验得到的9只股票的p值如表3所示,从表中可以看出9只股票的p值都非常小,拒绝

Table 2. ADF, PP, KPSS Test
表2. ADF、PP、KPSS单位根检验表
原假设,认为这9只股票的残差平方序列之间有明显的相关性,即收益率残差序列存在ARCH效应。
4.5. 基于GARCH族类模型的VaR计算
首先基于GARCH族类模型计算VaR,根据上述对于GARCHA族模型方法的介绍,运用GARCH族模型对9只股票的收益率数据进行分析,尝试GARCH(1,1),ARCH(1),EGARCH(1,1)模型,以AIC准则和系数显著性为判断标准,发现GARCH(1,1)模型的AIC最小,系数估计均显著,对拟合模型的残差和残差的平方进行白噪声检验,发现其均不拒绝原假设,故认为拟合模型的残差序列为白噪声序列且没有ARCH效应,故选取GARCH(1,1)模型对9只股票数据进行分析。
根据上文对9只收益率数据的基本特征分析,可以看出9只股票的收益率数据均不满足正态分布的特征,且分布呈现尖峰厚尾的特征,尝试采用t分布对样本数据进行拟合,得到的t分布的自由度的估计值如表5所示,为进一步检验收益率数据是否服从t分布,采取了KS检验方法,这一检验方法通过样本数据的经验分布函数和假定的分布形式对比,若两种分布形态的差异较小,则认为该样本满足指定的分布形式。H0:样本的分布形式满足指定的分布形式,H1:样本的分布形式不满足指定的分布形式 [9] 。对于9只股票的收益率数据进行KS检验,得到的p值如表4所示,从表可以看出p值均相对较大,不拒绝原假设,认为9只股票的收益率数据服从t分布。
应用t-GARCH(1,1)模型对9只股票的收益率数据进行建模。本文使用R软件在95%的显著水平下对模型参数进行估计,得到t-GARCH(1,1)模型的各个参数的估计如表5所示。
t-GARCH(1,1)模型:
接下来,根据上述估计的t-GARCH(1,1)模型来计算9只股票的收益率分布的风险价值。其中VaR的计算公式为:
,其中:
为给定时刻t下预测t+1时刻的条件标准差,
为在置信水平
下待估参数为
的t分布的下
分位数,
为t时刻的收益率数据,
为t分布的待估参数,
为给定的置信水平 [5] 。由此得到在置信水平95%下,9只股票的VaR值如表6所示。
Table 5. t-GARCH(1,1) Model
表5. t-GARCH(1,1)模型参数估计
Table 6. Caculation of VaR by t-GARCH(1,1) Model
表6. 基于t-GARCH(1,1)模型的9只股票的VaR估计
4.6. 基于分位数回归方法的VaR的计算
基于VaR的定义,我们可以看出VaR相当于在给定置信水平下一组收益率数据的条件分位点,因此提出了建立分位数回归模型计算VaR,本文选取Quantile-ARCH(1)模型对于9只股票的收益率的VaR进行计算。
其中Quantile-ARCH(1)为:
其中
为收益率
的均值,
为一组独立同分布的随机变量且其均值为0,方差为常数,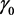 和
为未知参数。根据前面介绍的分位数回归方法,在给定信息集
下,关于Quantile-ARCH(1)模型中因变量
的
条件分位数为
,而已知VaR的定义为:
,则可以得到在置信水平
,VaR的计算公式为:
,得到9只股票的VaR估计值如表7所示。
和
为未知参数。根据前面介绍的分位数回归方法,在给定信息集
下,关于Quantile-ARCH(1)模型中因变量
的
条件分位数为
,而已知VaR的定义为:
,则可以得到在置信水平
,VaR的计算公式为:
,得到9只股票的VaR估计值如表7所示。
4.7. 两种VaR计算模型的比较
绘制两种模型计算得到的95%置信水平下的各时刻VaR值与实际值之间的相互关系图,具体图像见附图1~附图9。本文以平安银行的收益率数据为例,如图1所示,横坐标表示收益率数据时间,纵轴表示股票的收益率,黑线表示平安银行收益率数据的时序图,其中绿线部分表示运用分位数回归模型计算的VaR值,红线部分表示运用GARCH族模型方法计算出的VaR值。由图可以看出,两种模型都可以较好的覆盖掉收益率数据的最大损失,且两种VaR模型估计曲线都基本位于收益率数据的下方,且在收益率波动时,两种VaR模型估计曲线也随之剧烈波动,能很好反映收益率的变动情况,及时反映出市场变化。由此可以看出,运用Quantile-ARCH(1)模型计算的VaR和市场收益率的拟合度比运用t-GAECH(1,1)模型计算出的VaR的拟合度高,故分位数回归模型更适用于度量大陆股市风险。
为进一步探究两种模型的有效性,进而判断VaR计算方法的准确率。本文选择了失败率检验法和似然比检验两种方法,来对VaR计算模型的准确性进行探究。
假定在
置信水平下,观察天数为n,实际损失大于VaR的序列记为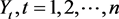 ,当实际损失
,当实际损失
Table 7. Caculation of VaR by Quantile-ARCH(1) Model
表7. 基于分位数回归方法的9只股票的VaR估计值
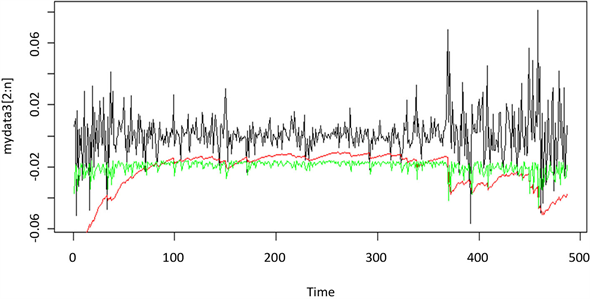
Figure 1. Yield curve & t-GARCH(1,1) VaR & Quantile-ARCH(1) VaR
图1. 平安银行收益率与t-GARCH(1,1)模型及Quantile-ARCH(1)模型预测的VaR对比
大于VaR值时,
为1,当实际损失小于VaR值时,
为0,则失败天数N为:
,失败率
。检验VaR模型的准确性即为检验失败率p是否显著不等于
,其中原假设
,
为给定的值。Kupiec在1995年提出了对零假设最合适的似然比检验,如下 [10] [11] :
若LR统计量大于给定显著水平下
的数值,则不接受原假设,认为VaR的计算方法不具有可行性,反之,则接受原假设,认为该估计方法具有可行性。
本文主要通过LR统计量和失败率两种方法来判定两种模型的可行性以及VaR的准确性。在95%的置信水平下,若0.001 < LR < 5.024时,不拒绝原假设;反之,拒绝原假设。若失败率与给定
值相差越小,则说明模型越准确。通过R软件计算出了,在显著为95%的情况下,基于t-GARCH(1,1)模型和基于Quantile-ARCH(1)模型计算的9只股票VaR的LR统计量,其结果如表8所示。从表8可以看出两种模型的LR均位于接受域内,均不拒绝原假设,故认为两种模型均可以计算9只股票的VaR,但从失败率可以看出,大部分股票基于Quantile-ARCH(1)模型计算的VaR的失败率与指定的
值更为接近,故认为
Table 8. Comparison of two models
表8. 两种模型的效果比较
基于Quantile-ARCH(1)模型计算的VaR比基于t-GARCH(1,1)模型计算的VaR更准确。
5. 结论
本文对来自主板市场,中小板市场,创业板市场的9只股票收益率数据应用t-GARCH(1,1)模型和Quantile-ARCH(1)模型两种方法估计其VaR,并使用似然比检验法和失败率检验法方法对模型估计VaR的有效性和准确性进行了比较。通过研究分析得到以下结论:
根据对9只股票的基本的统计特征分析可以看出,9只股票均不服从正态分布,表现出尖峰厚尾的分布特征,而不同市场的股票间也存在很大的差异,从股票收益率的时序图可以看出,其波动幅度最大的是创业板市场的股票,其次是中小板市场的股票,最后是主板市场的股票。由于主板市场是我国资本市场的重要组成成分,其上市标准对于股票市场发行人的要求较高,而中小板市场一般指的是股票市场发行人不满足主板市场上市要求的企业。创业板市场的公司主要从事高新技术产业,有着很好的发展前景,但公司人数较少且创立时间较短,创业板市场是小公司聚集最多的市场,故其股价的波动幅度最大,进而会影响到股票收益率的变动情况,面临的风险也较其他市场更大。
而从后文的实证分析表6和表7也可以看出,风险较小的为主板市场的平安银行和上汽集团两只股票。主板市场的公司具有一定的公司规模,且资金总额多,故总体发展较稳定。而风险最大的为中小板市场的煌上煌股票,这说明股票风险的大小不仅与其所处的市场有关,也与其所处行业有关,餐饮业所必须的原材料与自然条件密切相关,有可能在特定时段存在无法预估的风险,同时,近年来,在严控“三公”消费的背景下,一部分高端的餐饮企业的收益出现一定幅度的下滑。因此,在评估股票风险时,不光要考虑VaR值的大小,还要和其所处市场及行业特征相结合,更加合理有效的选股。
通过对t-GARCH(1,1)模型和Quantile-ARCH(1)分位数回归模型的VaR比较,可以看出分位数回归模型计算VaR更为精确,分位数回归模型不需要对收益率的分布进行假设,且无需对异方差性进行处理,可以更好的反映我国证券市场的风险情况。
附录
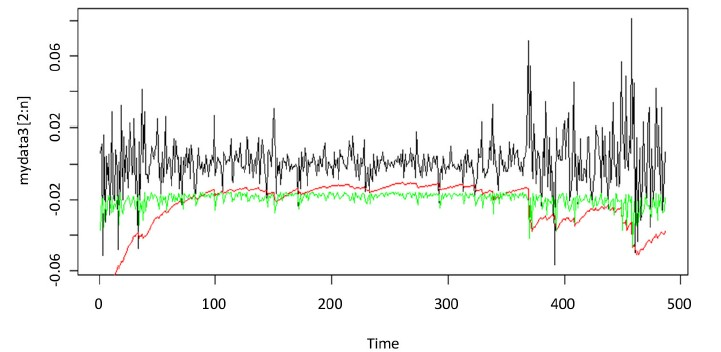
Figure 1. Yield curve & t-GARCH(1,1) VaR & Quantile-ARCH(1) VaR
图1. 平安银行收益率与t-GARCH(1,1)模型及Quantile-ARCH(1)模型预测的VaR对比
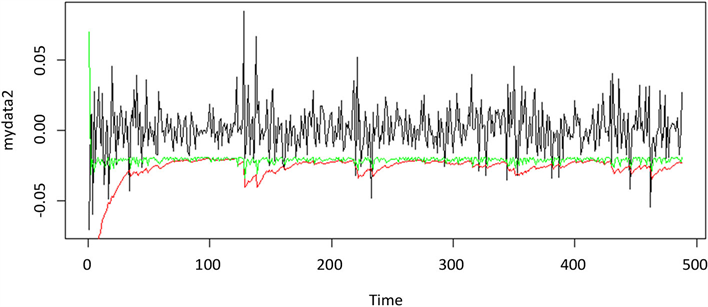
Figure 2. Yield curve & t-GARCH(1,1) VaR & Quantile-ARCH(1) VaR
图2. 上汽集团收益率与t-GARCH(1,1)模型及Quantile-ARCH(1)模型预测的VaR对比
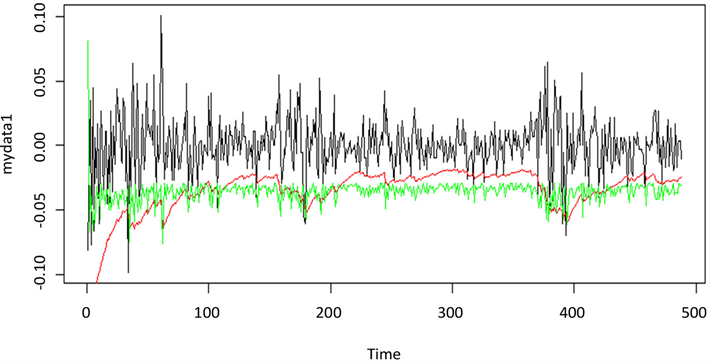
Figure 3. Yield curve & t-GARCH(1,1) VaR & Quantile-ARCH(1) VaR
图3. 远兴能源收益率与t-GARCH(1,1)模型及Quantile-ARCH(1)模型预测的VaR对比
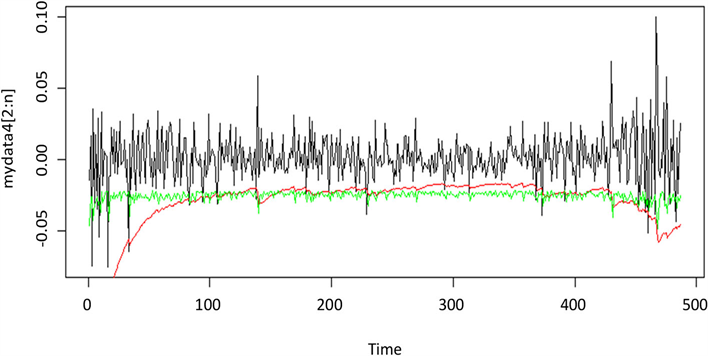
Figure 4. Yield curve & t-GARCH(1,1) VaR & Quantile-ARCH(1) VaR
图4. 科伦药业收益率与t-GARCH(1,1)模型及Quantile-ARCH(1)模型预测的VaR对比
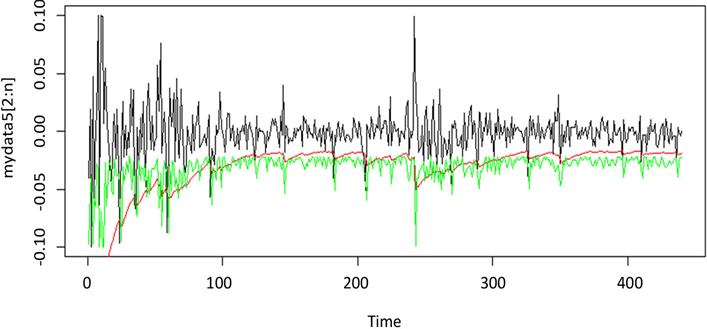
Figure 5. Yield curve & t-GARCH(1,1) VaR & Quantile-ARCH(1) VaR
图5. 巨轮智能收益率与t-GARCH(1,1)模型及Quantile-ARCH(1)模型预测的VaR对比
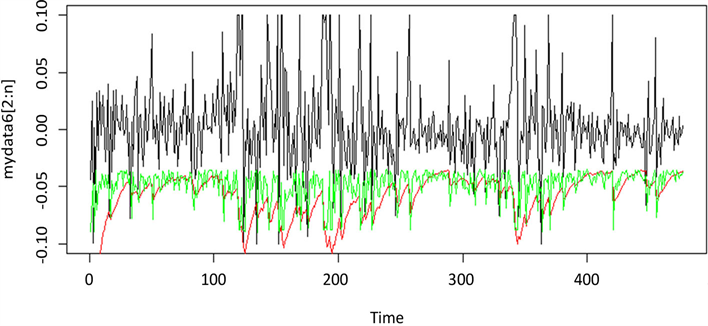
Figure 6. Yield curve & t-GARCH(1,1) VaR & Quantile-ARCH(1) VaR
图6. 煌上煌收益率与t-GARCH(1,1)模型及Quantile-ARCH(1)模型预测的VaR对比
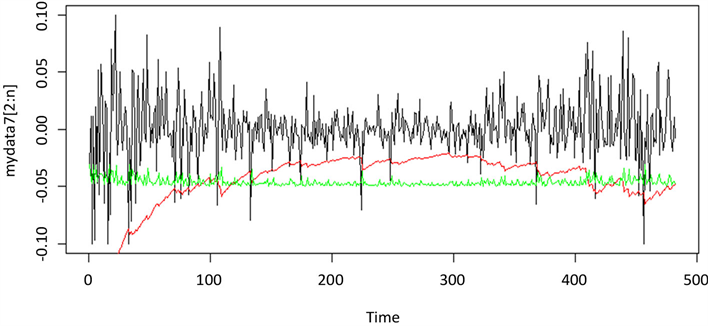
Figure 7. Yield curve & t-GARCH(1,1) VaR & Quantile-ARCH(1) VaR
图7. 阳光电源收益率与t-GARCH(1,1)模型及Quantile-ARCH(1)模型预测的VaR对比
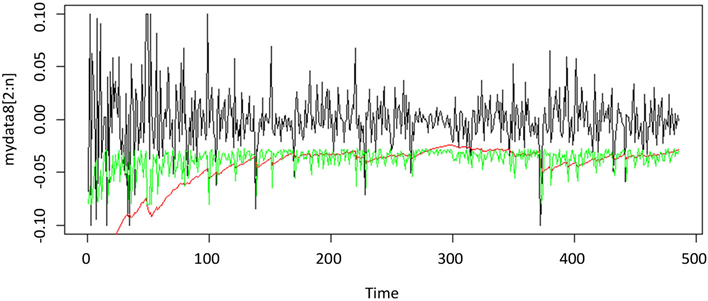
Figure 8. Yield curve & t-GARCH(1,1) VaR & Quantile-ARCH(1) VaR
图8. 同花顺收益率与t-GARCH(1,1)模型及Quantile-ARCH(1)模型预测的VaR对比
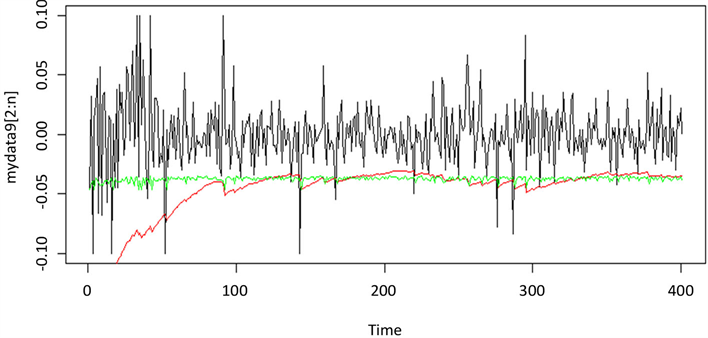
Figure 9. Yield curve & t-GARCH(1,1) VaR & Quantile-ARCH(1) VaR
图9. 上海钢联收益率与t-GARCH(1,1)模型及Quantile-ARCH(1)模型预测的VaR对比