1. 引言
党的十八大提出,要确保国家粮食安全和重要农产品有效供给。近年来,由于耕地减少、人口增加、水资源短缺、气候变化等问题日益凸显,加之国际粮食市场的冲击,我国粮食产业面临着潜在的风险。因此,研究我国的粮食保护政策具有十分重要的作用和意义。
粮食保护政策体系主要由三大支持政策组成:粮食生产支持政策、粮食价格支持政策和收入支持政策。粮食最低收购价政策就属于粮食价格支持政策范畴。然而,自粮食最低收购价政策投入实施后,各界学者对此政策议论纷纷,持不同意见。历史上看,连续实行多年的最低收购价政策给市场带来粮价刚性上调的预期,造成了粮价越来越高、国内外价差扩大等现象,长期来看,扭曲了粮食市场,不利于粮食的稳产和农民增收,会议提出的“改革粮食价格形成和收储机制”势在必行。为认真贯彻中央关于“以我为主、立足国内、确保产能、适度进口、科技支撑”的国家粮食安全战略和习近平总书记、李克强总理的重要指示,大力实施粮食收储供应安全保障工程,坚决守住“种粮卖得出,吃粮买得到”的底线,确保不出现农民卖粮难,确保不发生粮食供应脱销断档的问题。因此,分析影响粮食种植面积的因素、衡量粮食最低收购价政策实施的效果以及建立粮食最低收购价的合理定价模型等是当前迫切需要解决的问题。
2. 理论模型的选取
2.1. 灰色关联度模型
大千世界里的客观事物现象复杂,影响粮食种植面积的因素繁多。我们需要系统进行因素分析,以确定这些因素中哪些对系统来讲是主要的,哪些是次要的,哪些需要发展,哪些需要抑制,哪些是潜在的,哪些是明显的。这对我们简化和优化模型是必要的。本节采用灰色关联度分析 [1] 的方法来对系统进行关联性分析。
作为一个发展变化的系统,关联分析实际上是动态过程发展态势的量化比较分析。所谓发展态势比较,也就是系统各时期有关统计数据的几何关系的比较。
选取参考数列
其中t表示时刻,假设有m个比较数列
则称
为比较数列
对参考数列
在k时刻的关联系数,其中r为分辨系数,称上式中
与
分别为两级最小差及两级最大差。则
(1)
关联度,是把各个时刻的关联系数集中为一个平均值,把过于分散的信息集中处理。经过关联度的分析,我们可以选择合理的因素研究粮食的最低收购价。
2.2. 回归模型
回归模型(regression model) [2] 对统计关系进行定量描述的一种数学模型。要研究粮食的最低收购价就要先研究影响粮食种植面积与影响因素的关系,最直接的关系就是对粮食种植面积起促进作用还是制止作用,因此我们先选线性回归模型进行研究。
线性回归模型是回归模型中的一种,假设y是一个可观测的随机变量,非随机因数
和随机误差e对y有影响,并且它们之间存在线性关系
(2)
其中
为未知参数。e是均值为零,方差为
的误差项,它表示除
之外的其他因数对y的综合影响,以及试验或测量误差。经过数据处理后,误差可以假定为
。
经分析和观察,对线性回归模型进行了修正,得到下面的模型
2.3. 预测模型
由前面的模型,得到了种植面积,下面跟据种植面积对粮食的最低收购价进行预测。一般用指数模型进行预测。但利用指数曲线外推来进行预测时,存在着预测值随着时间的推移会无限增大的情况。这是不符合客观规律的。因为任何事物的发展都是有一定限度的。例如某种畅销产品,在其占有市场的初期是呈指数曲线增长的,但随着产品销售量的增加,产品总量接近于社会饱和量时。这时的预测模型应改用修正指数曲线。
(3)
在此数学模型中有三个参数a,b和K要用历史数据来确定。
修正指数曲线用于描述这样一类现象。
1) 初期增长速,随后增长率逐渐降低。
2) 当
时,
,即
。
当K值可预先确定时,采用最小二乘法确定模型中的参数。而当K值不能预先确定时,应采用三和法。
把时间序列的n个观察值等分为三部分,每部分有m期,即
。
第一部分:
;
第二部分:
;
第三部分:
令每部分的趋势值之和等于相应的观察值之和,由此给出参数估计值。三和法步骤如下:
记观察值的各部分之和
由于
得
由上面的式子,解得
至此三个参数全部确定了,于是就可以用(3)式进行预测。
值得注意的是,并不是任何一组数据都可以用修正指数曲线拟合。采用前数据进行检验,检验方法是给定数据的逐期增长量的比率是否接近某一常数b。
2.4. Logistic模型
为了使预测更加准确,本文做了进一步的模型预测。Logistic曲线(生长曲线) [3] 模型:生物的生长过程经历发生、发展到成熟三个阶段,在三个阶段生物的生长速度是不一样的,例如南瓜的重量增长速度,在第一阶段增长的较慢,在发展时期则突然加快,而到了成熟期又趋减慢,形成一条s型曲线,这就是有名的Logistic曲线(生长曲线),很多事物,如技术和产品发展进程都有类似的发展过程,因此Logistic曲线在预测中有相当广泛的应用。
Logistic曲线的一般数学模型是
其中y为预测值,L为y的极限值,r为增长率常数,
。解此微分方程得
其中c为常数。
下面我们记Logistic曲线的一般形式为
(4)
检验能否使用Logistic曲线的方法,是看给定数据倒数的逐期增长量的比率,是否接近某一常数b。即
Logistic曲线中参数估计方法如下:
作变换
得
令每部分的趋势值之和等于相应的观察值之和,由此给出参数估计值。三和法步骤如下:记观察值的各部分之和
类似的得到
(5)
3. 实证分析
首先建立影响粮食种植面积的指标体系和关于粮食种植面积的数学模型,讨论、评价指标体系的合理性,然后研究他们之间的关系,并对得出的相应结果的可信度和可靠性给出检验和分析,最后对粮食最低价进行预测。
3.1. 指标选取
一般来讲,粮食的种植面积是决定粮食供给的关键因素,也是保障粮食安全的重要前提。衡量粮食最低收购价政策实施的效果,主要是比较政策实施前后粮食种植面积是否有显著性变化。然而,可能影响粮食种植面积的因素有很多,除了粮食最低收购价政策外,还可能有其他很多的影响因素,如农业劳动力人口、粮食进出口贸易、农民受教育程度、城乡收入差距、家庭负担等。经研究发现,城镇化率也是影响粮食种植面积的一个重要因数。下面我们对影响因数的选取进行说明。
因为粮食进出口贸易比较复杂,其中影响粮食的进出口贸易的主要因数就是粮食的出口数量,我们
用粮食的出口数量表示粮食进出口贸易,设为x1;家庭负担用
,设为x2;劳动力人口数设
为x3;城乡收入差距设为x4;由文献 [1] 知城镇化率与粮食的种植面积是息息相关的,设为x5;为了将农民的受教育程度数据化,我们用教育费用这个指标表示农民的受教育程度,设为x6。
确定这些指标后,我们首先建立一般的线性回归模型,初步了解相关各指标之间的关系,然后对模型进行合理性分析,最后对模型进行修正,建立最终模型,最后进行合理的粮食最低价预测。
3.2. 数据分析
本文选取的数据为2000年到2014年这个时间段的数据(数据来源于2000~2015统计年鉴 [4] )。
用SAS的PROC REG过程对以上的指标分析发现,农民的受教育程度与家庭负担存在典型相关关系,得到相关系数为0.9896,因此,我们将受教育程度这个变量去掉,只考虑前五个因数(自变量)。
在多指标综合评价中,由于各指标所代表的物理涵义不同,因此存在着量纲上的差异。无量纲化,也称作数据的标准化、规格化,是一种通过数学变换来消除原始变量量纲影响的方法。
本文中采用均值化公式:
其中
是每个因数的原数据,
是均值,
是无量纲化处理后的数据。该方法在消除量纲和数量级影响的同时,保留了各变量取值差异程度上的信息。为了方便观察,我们将数据制成表格如下表1:

Table 1. Data of the main variables
表1. 各主要变量的数据
3.3. 指标合理化分析
将数据代入模型一中,用MATLAB [5] (见程序1)得到关联矩阵
从关联矩阵R可以看出:
1) 第4个值最小,但是也是大于0.5的,表明各种城乡差距对粮食的种植面积影响相对较小,即随着城乡收入差距的变化,并没有对农民的生活有太大影响。
2) 第2个值最大,表明农村的家庭负担对粮食的种植面积的影响很大,即当农民家庭负担重时,有的就去城市打工了,导致农田荒废,耕地面积减少。
3) 第5个值相对较大,说明城镇化率对种植面积的影响较大,即随着城镇化率的加大,房地产也随之发展,导致建房子用地增多,粮食种植面积减少。
4) 以上分析表明这五个因子对粮食的种植面积有较大影响。
3.4. 回归模型的建立
设粮食种植面积为因变量y,自变量x1为粮食进出口贸易、自变量x2为家庭负担、自变量x3为劳动力人口数、自变量x4为城乡收入差距,自变量x5为城镇化率。则可以建立如下的线性模型
用SAS求解后得到如下结果(表2,表3)。
由表3我们得到如下线性模型
3.5. 原模型的检验和分析
结果分析:由表2得
,
。检验假设:
至少一个非零,检验统计量
,观测值
,取检验水平
,则检验的P值为0.0988、0.1091、0.2838、0.5570、0.6584、0.3625 > 0.05,
,从而拒绝
,这表明y与
的关系是显著。由图3得到各参数的估计值
相应的检验p值分别为这表明对y与
的线性的假设不合理。
另一方面,从各变量与种植面积关系的图形(图1~5)得到各个变量与种植面积不是成简单的线性关系,而从下函数关系图像可以看出种植面积与粮食进出口贸易、劳动力人口数、家庭负担、城镇化率成指数关系,而与城乡收入成三次函数关系。
3.6. 模型的优化
由3.4的分析我们得到了种植面积与各指标的关系是满足如下形式的模型
求解得到系统的优化模型:
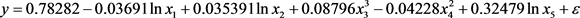
Figure 1. The relationship between the planting area and the import and export trade of grain
图1. 种植面积与粮食进出口贸易的关系
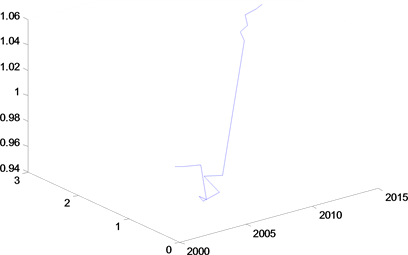
Figure 2. The relationship between the planting area and the family burden
图2. 种植面积与家庭负担的关系
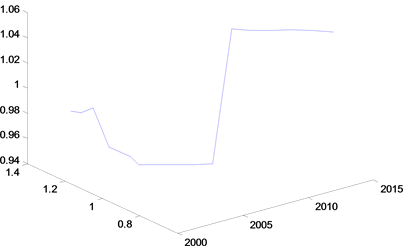
Figure 3. The relationship between the planting area and the number of labor population
图3. 种植面积与劳动力人口数的关系
Figure 4. The relationship between the area of planting and the gap between urban and rural areas
图4. 种植面积与城乡差距的关系

Figure 5. Relationship between the urbanization rate of planting area
图5. 种植面积城镇化率的关系
3.7. 优化模型的检验分析
结果分析:由附录(2)有上述模型的
,
。
检验假设:
至少有一个非零,检验统计量
,观测值
,取检验水平
,则检验的p值为
,从而拒绝
,这表明y与
性关系是显著得到了估计值,相应的检验p值分别为 0.0001、0.00915、0.03642、0.02115、0.0842、0.0035 < 0.05这表明y 与
的上述模型是合理的。
用SAS得到模型的QQ图6:
图形大致在一条直线上,说明了误差正态性假设合理,同时也说明了所建立模型的模型是合理的。
模型:粮食最低收购价的合理定价模型。
3.8. 模型的建立与求解
本模型是以水稻和小麦为代表研究粮食最低收购价的合理定价模型,并对2017年的粮食最低收购价的合理范围进行了预测。
数据的选择与处理
下面的模型先以稻谷的从2000年到2014年的每50公斤的最低收购价为例子建立模型取值是三个等级的平均值,再用同样的方法对小麦的最低收购价进行建模,取值是白小麦的第三等级的数据,最终对稻谷和小麦的最低收购价进行合理范围的预测。种植面积是从2000年到2014年的数据,单位是百万公顷。
由图7、图8可知种植面积是先随着最低价格的增加而增加,最后趋于平稳,与指数模型和人口模型很相同。下面就选用指数模型预测和logistic模型,这两种模型都是有这种趋势的,因此用这两个模型进行预测。
将数据带入模型三,用MATLAB计算的到预测函数
预测结果与原结果差距很大。这说明指数模型不可取。下面我们来将数据代入logistic模型。

Figure 7. The relationship between the planting area and the minimum purchase price
图7. 种植面积与最低收购价的关系

Figure 8. The relationship between the planting area and the minimum purchase price (× 104)
图8. 种植面积与最低收购价的关系(× 104)
用MATLAB得
,
,再由(5)式得
从而得到水稻的最低收购价的logistic模型为
以同样的方法建立小麦的最低收购价的logistic模型
(6)
现在研究时间t与种植面面积之间y的关系经过SAS模拟发现两者之间成多项式关系,其中检验统计量为
,当
,检验的
,从而拒绝
,这说明拟合效果很好。
得到时间t与种植面面积之间y的关系为:
(7)
综合(6)和(7)有粮食最低价的合理范围的预测模型为
水稻:
小麦:
3.9. 合理性评价
根据上述模型,得到了如下表4的预测值,如下表示的水稻和小麦的实际最低收购价格和预测最低收购价格及误差值。
根据2000到2014的种植面积最大为13538.6,最小为1217.6,那么为了达到“十二五规划”的结果,种植面积的范围应在5%内上下波动,则种植面积应在之间,有上述模型有小麦的最低价合理的范围为
。水稻的最低价合理的范围为
。我们用误差值 = (最低收购价 − 最低收购价的预测值)*100/最低收购价的预测值来评价可见“十二五规划”期间国家发展与改革委员会公布的粮食最低收购价的合理性。
由表2知,“十二五规划”的值与预测值的误差值不超过5%,可见“十二五规划”期间国家发展与改革委员会公布的粮食最低收购价是合理的。
Table 4. A comparison between the actual minimum price and the estimated purchase price
表4. 实际最低价收购价和预测收购价的比较
4. 总结
该模型最后的结论是很好的,不仅找到了粮食最低收购价与各指标间的关系,而且从2000年到2014年的结果预测与原始价格的拟合度都在5%以内,在对2017的粮食最低收购价的预测也很合理。结论中的预测模型优于用时间序列模型 [6] ,本文提出的模型时间这一“不可控”因数的影响力弱化,得到了粮食最低价与影响种植面积的“可控”指标的关系,我们可以通过改变这些指标来调整粮食最低价,充分发挥最低收购价引导作用。通过调节粮食最低收购价,从而引导粮食生产结构性调整,从宏观层面发挥政策指导作用,最低收购价容易激发种粮大户和部分农民的生产积极性,从某种程度可以改善粮食生产结构。