1. 引言
市场需求预测 [1] 是指通过对消费者的购买心理和消费习惯的分析,以及对国民收人水平、收人分配政策的研究,推断出社会的市场总消费水平。市场需求预测非常关键。准确的预测能够使企业设定正确的库存水平,为其产品正确定价,并了解如何扩大或收缩其未来的业务。错误的预测会导致销售损失、库存耗尽、客户满意度下降以及收入损失。市场瞬息万变,竞争激烈,市场需求预测的准确性决定了市场需求分析的准确结果以及与公司发展相关的重要决策。因此,比较市场需求预测的现有结构,并在此基础上形成市场需求的有效预测原则,是特别重要的。
通常,市场需求 [2] 预测有两种方式,即非数学建模法和数学建模法。非数学建模法主要包括购买者意向调查法、销售人员意见法、专家意见法和市场试验法。数学建模法主要指的是时间序列分析法。该方法将某种经济统计指标的数值,按时间先后顺序排列形成序列,再将此序列数值的变化加以延伸,进行推算,预测未来发展趋势。随着社会的进步和发展,关于市场需求的数据量突增。海量的市场需求数据为我们带来了机遇与挑战。如果应用程序场景复杂,数据规模较大,传统的数据处理技术和模型将很难在预测工作中获得好的结果。在这样的背景下,人工智能尤其是深度学习技术 [3] 开始在大数据处理 [4] 领域崭露头角,并为我们预测市场需求提供了全新的思路。
基于以上研究,我们对新加坡境内几个不同区域的天然气市场需求数据集进行了分析,并且引入了一种基于GRU和EEMD [5] 的市场需求预测模型(DeepMDF)。实验结果表明,我们的工作能够很好地完成市场需求预测的任务。我们的工作的主要贡献如下:
1) 我们提出了一种能够预测非平稳、非线性的市场需求数据的DeepMDF模型。DeepMDF主要包括两部分,它们分别是用于对具有复杂模式的市场需求数据进行分解的EEMD和用于建模时序数据的GRU。EEMD的分解过程针对市场需求时序数据本身,且不依赖于任何先验的基函数。因此,EEMD是局部的、自适应的、有效的。在对原始的市场需求时序序列进行分解后,我们使用GRU分别对不同的本征模态分量(IMF)和余项(Res)进行预测。最终的预测结果是对所有IMF和Res预测结果之和。
2) 对不同的IMF和Res进行建模的过程是相互独立的,即针对不同的IMF和Res,GRU在建模时的参数调优过程是不同的。因此,针对不同的模态,建模的过程是不同的、有针对性的、适用的。
3) 对于任何企业来说,市场需求预测都是一个关键的过程。库存、生产、存储、运输、营销和运营的各个方面都受到市场需求的影响。确定消费者的偏好及其购买可能性,能够使这些公司能够在产品线及其供应链上做出更好的决策,确保货架库存充足,并最大限度地降低库存短缺或超额的风险。
2. 研究方法
2.1. 用EEMD方法分解时序数据
经验模态分解(EMD)是一种分析非线性不稳定数据的方法。它可以将任何复杂数据分解为有限的、数量很少的IMF,分解方法是自适应的、高效的。该方法的关键是引入了基于数据局部特征的IMF,这使得瞬时频率变得有意义。而复杂数据的瞬时频率的引入,消除了对非线性和非稳定数据的谐波的需要。EMD的最大问题是频率特征的模式混合,这不仅会导致严重的时间—频率分布混淆,还会使IMF的物理意义丧失。因此,EMMD被提出用于改善模态混合现象。EEMD将真实的IMF视为样本的均值,每个样本为信号加上一个有限振幅的白噪声。然后通过EMD分解样本数据,并保存结果。如果这样做的次数足够多,噪声的影响会互相抵消。样本均值即被视为是真实结果。随着样本量的增加,剩下的就是信号本身。EEMD可以显著地改善模式混合和间歇性问题。
(1)
如公式(1)所示,经过EEMD方法处理,原始市场需求时序数据D(t)可以被表示为所有的IMF分量IMFi(t)与余项Res(t)之和。其中,n表示分解出来的IMF的个数。
2.2. 用GRU对时序数据进行建模
GRU是传统的循环神经网络(RNN)的一个变种。与长短期记忆(LSTM)网络一样,它能有效地捕捉长序列数据之间的语义关联,缓解梯度消失或梯度爆炸的现象。同时,它的结构和计算过程比LSTM简单,计算效率也比LSTM高。
如图1所示,首先GRU计算更新门(z)和复位门(r)的门值。计算方法是用X(t)和S(t − 1)进行线性变换,然后GRU用Sigmoid激活函数来处理结果。之后,复位门的值经过处理得到S(t − 1),它代表了前几个时间步骤的信息可以被使用的程度。下一步是使用复位后的S(t − 1)进行基本的RNN计算,即使用X(t)进行线性变化,GRU使用Tanh激活函数获得S(t)的新值h。最后,更新门的值将作用于新的S(t),1减去门的值将作用于S(t − 1),然后将两个结果相加,得到最终的隐含状态输出,即S(t)。这个过程很好地阐释了更新门具有保留先前结果的能力。当门的值趋向于1时,输出为S(t);当门的值趋向于0时,输出为S(t − 1)。这种结构大致有两个优点:首先,GRU的参数数量不大,减少了过度拟合的风险。与参数数量较大的LSTM相比,GRU具有更快的训练速度和收敛速度。其次,针对市场需求变化时序数据,数据集相对较小。因此,LSTM在处理时间上并不具有优势。基于GRU的计算过程的公式如下。
(2)
(3)
(4)
(5)
在公式(2)~公式(5)中,σ代表Sigmoid激活函数,Ur和Wr代表GRU计算r时的两个参数矩阵,Uz和Wz代表GRU计算z时的两个参数矩阵,Uh和Wh代表GRU计算h时的两个参数,@也代表两个矩阵的乘法操作。
2.3. 模型设计
如图2所示,使用DeepMDF模型预测市场需求主要有三个主要步骤。首先,原始数据D(t)被EEMD方法分解为n个IMF分量和一个余项(Res)。其次,对于提取的每个IMF成分和余项,我们用GRU模型分别对它们进行时序依赖性建模和预测。如公式(6)所示,ri表示对第i个IMF的预测结果;
表示第i个IMF的实际值;rRes表示对余项的预测结果;
表示余项的实际值;τ表示损失值。每个建模和预测过程都是独立的,我们选择均方误差作为损失值进行反向传播计算。最后,我们将所有的预测结果进行加权,将加权后的Rf作为最终预测结果,如公式(7)所示。
(6)
(7)
总而言之,DeepMDF预测模型应用了“分解和集成”的思想。分解是为了简化预测任务,而集成是为了对原始数据形成具有共识性的预测。将各个时间尺度上的建模结果进行集成,可以挖掘不同尺度上的有效信息,以提高预测性能。
3. 实验
3.1. 数据与基准模型介绍
我们选择使用新加坡境内三个不同城市功能区的天然气市场需求数据进行实验。数据的时间范围是从2005年到2017年。数据的采样频率为1次每月。我们将2005年到2015年共计11年的天然气市场需求数据作为训练集进行训练,将2016年到2017年共计两年的天然气市场需求数据作为评估集进行预测和评估。为了数据的保密性和隐私性,我们仅用“需求量”表示实际的需求数据值,不设置数据的具体单位。

Figure 2. Framework of the DeepMDF model
图2. DeepMDF模型框架
我们在实验中选择的基准模型如下:
1) EEMD + RNN:针对市场需求时序数据,我们先使用EEMD方法进行分解,然后使用RNN进行分别预测,最后将所有预测结果进行集成。RNN的记忆单元会保存循环层的状态,并在t + 1时刻,将记忆单元的内容和t + 1时刻的输入一起给到循环层。
2) EEMD + 差分自回归移动平均模型(ARIMA [6] ):类似于EEMD + RNN,最终的预测结果是所有ARIMA的预测结果的集成。将自回归模型、移动平均模型和差分法结合,我们就得到了ARIMA。
3) EEMD + 季节性差分自回归移动平均模型(SARIMA [7] ):它是在ARIMA的基础上加入季节性特征后的产物。它适用于时间序列中带有明显周期性和季节性特征的数据。
4) GRU:GRU的输入输出结构与普通的循环神经网络(RNN)相似,而且它的处理逻辑与LSTM相似。与LSTM相比,GRU少了一个“门”结构。GRU的可训练参数也比LSTM少。然而,GRU却能达到与LSTM相似的精度。考虑到硬件的计算能力和时间成本,GRU是更多研究人员的选择。
3.2. 实验设置与评估指标
我们在实验中使用的计算机的配置如下:
1) CPU:Intel(R) Xeon(R) w-2133。
2) GPU:NVIDIA GTX 1080Ti。
3) 内存:64 GB。
每个训练过程需要200轮;初始学习率被设置为0.001;训练过程中的梯度优化器被设置为Adam优化器;损失函数设置为均方误差损失。
本实验使用了两种指标来评估模型的性能,包括平均绝对误差(MAE)和均方根误差(RMSE)。公式(8)和公式(9)分别是MAE和RMSE的表达式。其中,n表示样本个数;Ypredt表示t时刻的预测值;Yt表示t时刻的真实值。MAE可以衡量一个模型的预测精度,但是它是基于绝对误差的计算过程。虽然绝对误差能够获得一个评估值,但是我们无法获知这个评估值所代表的模型性能的优劣情况。因此,RMSE也被用于本实验的评估过程。RMSE被用于衡量预测值与真实值之间的偏差,能够很好地反应预测结果的精度。
(8)
(9)
3.3. EEMD对市场需求时序数据进行分解
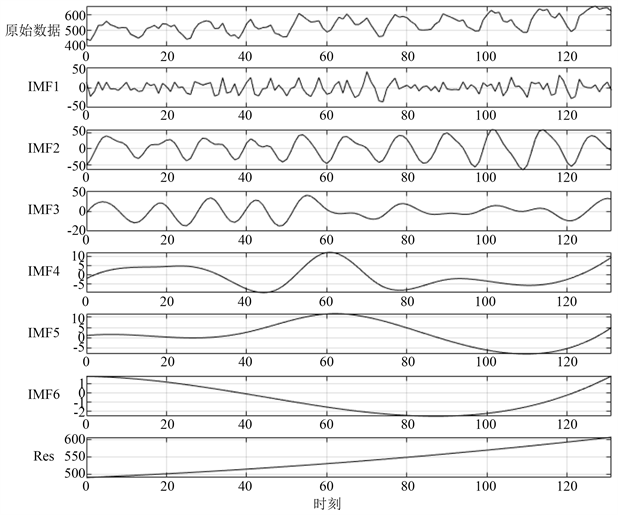
图3中的(a)、(b)、(c)分别代表三个不同的城市功能区在2005年到2015年间的天然气能源市场需求变化情况。其中,横坐标表示时刻的变化;纵坐标表示需求量。图4中的(a)、(b)、(c)分别表示对图3中(a)、(b)、(c)这三个市场需求时序序列的EEMD处理结果。我们可以发现,对于三个不同的天然气市场需求时序序列,经过EEMD方法分解后都得到了6个IMF和一个余项。此外,分解得到的前三个IMF都是频率相对较高的,而IMF4、IMF5和IMF6的频率较低。相比于原始市场需求时序序列,经过分解得到的IMF规律性更加明显、数值分布更加均匀,能够有效地被神经网络进行建模和预测。
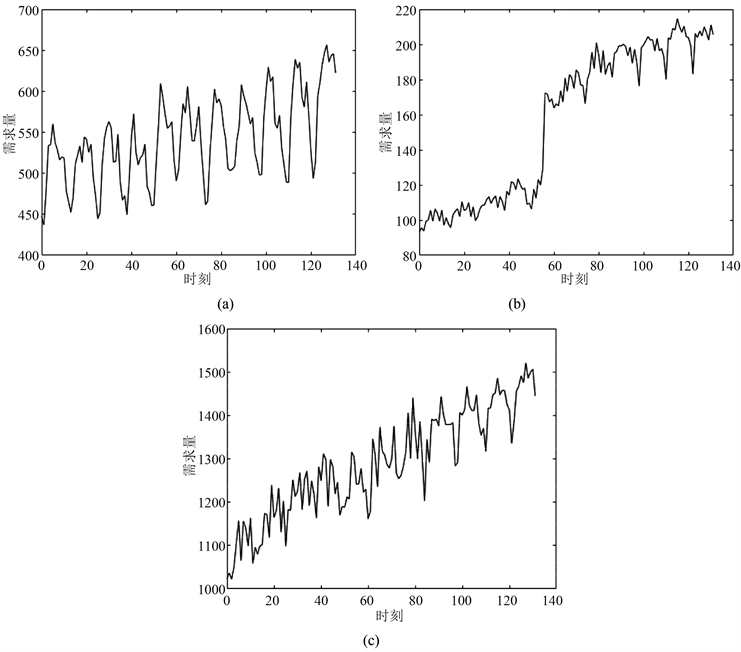
Figure 3. Time-series changes in market demand for the three sub-datasets (three urban functional areas)
图3. 三个子数据集(三种城市功能区)的市场需求时序变化情况
 (a)
(a) 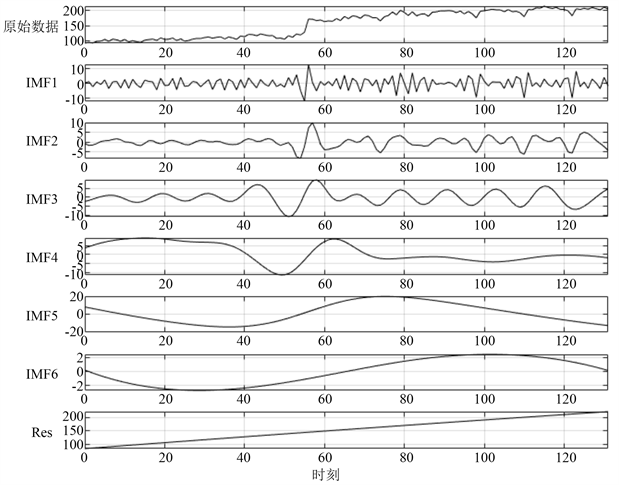 (b)
(b) 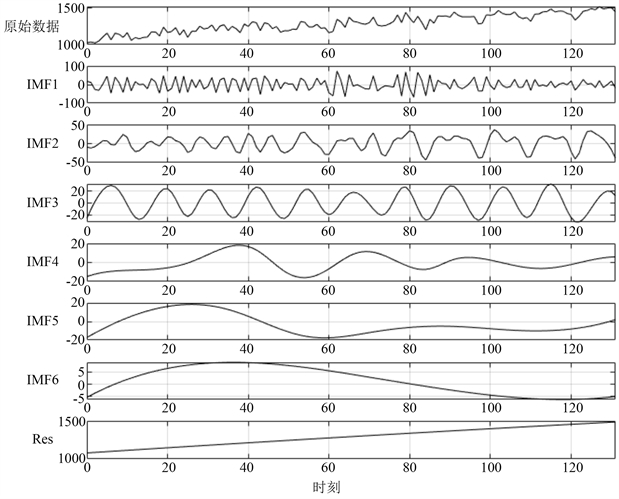 (c)
(c)
Figure 4. Results of EEMD processing on three sub-datasets (three urban functional areas)
图4. 对三个子数据集(三种城市功能区)进行EEMD处理的结果
4. 结果
4.1. 定量分析
所有模型的评估结果如表1所示。ARIMA是传统的处理时间序列的模型,由于它无法对EEMD方法分解后得到的高频IMF的季节性变化特征进行捕捉,因此EEMD和ARIMA的混合模型在实验中效果最差。相比于ARIMA,引入季节性变化规律的SARIMA模型在实验中效果较好,甚至超过了RNN。从理论上讲,RNN有能力处理市场需求时序数据这种具有“长距离依赖”关系的数据。不幸的是,在实践中,RNN似乎无法有效地对长期市场需求时序数据进行建模。这是因为,在实际的实验环境中,RNN会发生梯度消失现象。RNN的梯度消失不是指损失函数对参数的总梯度消失了,而是对较远时间步的梯度消失了。相比于基准模型,我们提出的DeepMDF模型的性能最佳。GRU在RNN的基础上引入门控机制来控制信息的传播,能够有效地针对长期市场需求时序数据进行建模。此外,相比于LSTM,GRU的参数量少,过拟合的风险小。针对本工作中选择的小规模数据集,GRU的建模显得更加迅速且有效。相比于其他基准模型的预测结果,DeepMDF分别平均在MAE和RMSE上降低了约71.87%和70.35%。
4.2. 定性分析
如图5所示,EEMD + ARIMA混合模型的预测值均偏大,而且预测值的波动性非常大。对于原始市场需求时序数据的变化规律和极值都没有准确拟合。相比于EEMD + ARIMA混合模型,EEMD + RNN混合模型和EEMD + SARIMA混合模型的效果更好。然而,RNN建模长期时序序列的能力较差。随着时间的推移,EEMD + RNN混合模型的预测精度逐渐下降。SARIMA模型在建模时要求时序数据是稳定的,或者是通过差分化后是稳定的,它在本质上只能捕捉线性关系,而不能捕捉非线性关系。因此,SARIMA在预测时也不能实现准确拟合。相比于这些基准模型,我们提出的DeepMDF模型能够相对精确地拟合原始市场需求数据的局部极值和非线性波动规律。

Table 1. Comparison results of models
表1. 各个模型的对比结果
 (a)
(a)  (b)
(b)  (c)
(c)
Figure 5. Comparison of the prediction results of DeepMDF and baselines
图5. DeepMDF与基准模型的预测结果比较
4.3. 消融研究
我们设置了消融实验为了探索EEMD在分解市场需求时序序列中的有效性。实验结果表明(如图6所示),虽然GRU也能够拟合出市场需求时序序列的波动性规律和极值变化,但是GRU对某些局部峰值的拟合程度并不好。这是因为市场需求时序数据中的非稳定性因素和诸多噪声数据使得GRU达到了性能瓶颈。EEMD将复杂的时序序列数据分解为诸多较稳定的、数值分布均匀的IMF和余项,使得GRU能够快速且稳定地提取这些分量的时间相关性特征。事实证明,EEMD对局部峰值的拟合帮助很大。如表2所示,相比于GRU,DeepMDF在MAE和RMSE上平均降低了约74.86%和67.76%。
 (a)
(a) 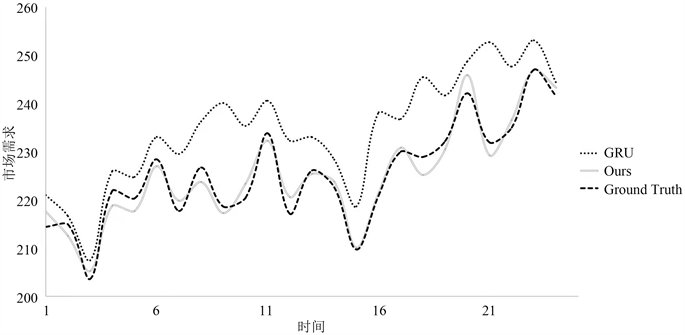 (b)
(b)  (c)
(c)
Figure 6. Comparison of the prediction results of DeepMDF and GRU
图6. DeepMDF与GRU的预测结果比较
Table 2. Comparative results of ablation studies
表2. 消融研究对比结果
5. 讨论
市场需求预测是所有计划活动的基础。具体而言,市场需求预测作为预测分析任务被认为是了解未来需求的重要工具。准确的市场需求预测保证了合适的供应链管理,并通过防止库存缺货来提高客户满意度。市场需求预测问题可以表述为时间序列预测问题。时间序列预测 [8] 已应用于各个应用领域,例如市场需求预测、信用评分 [9]、电力负荷预测 [10] 和出行需求预测 [11] 等。现有的市场需求预测方法包括传统的时间序列模型(如ARIMA和卡尔曼滤波),机器学习模型(如支持向量机(SVM)和随机森林)以及深度学习模型(如RNN、LSTM和GRU)。
在传统的时间序列数据挖掘中有大量的经典方法,如AR、MA和ARMA等。AR模型相对简单,它考虑到未来的时间点可以通过历史时间点的线性组合来预测。MA模型与AR模型相似,但MA是白噪声的线性组合;ARMA模型包含AR和MA的特征。此外,Ampountolas [12] 还提出了SARIMAX等改进的模型以适合不同的应用场景。然而,如果应用场景复杂,数据规模较大,传统的时间序列模型将很难在预测工作中获得好的结果。
许多研究人员也使用机器学习的手段进行市场需求预测。机器学习 [13] 是人工智能及模式识别领域的共同研究热点,其理论和方法已被广泛应用于解决工程应用和科学领域的复杂问题。产品销售预测是采购管理的一个关键方面,采用预测分析有助于估计市场需求并确定库存水平。Tu等人 [14] 使用基于支持向量机(SVM)的机器学习算法创建预测模型,得到了对产品销售的准确预测结果。人工神经网络(ANN)从信息处理角度对人脑神经元网络进行了抽象,是20世纪80年代以来人工智能领域兴起的研究热点。研究人员们通过建立某种简单的模型,可以按不同的连接方式组成不同的网络。Yuan [15] 开发了一个用于识别和预测复杂的销售模式和市场营销风险的ANN模型;Kandananond等人 [16] 研究了基于人工神经网络和支持向量机的消费产品需求预测;Ticknor [17] 提出了一种人工神经网络模型,以实现对股票市场的预测分析。
近年来,深度学习在各个领域都取得了显著的成就。深度学习是学习样本数据的内在规律和表示层次,这些学习过程中获得的信息对诸如文字,图像和声音等数据的解释有很大的帮助。它的最终目标是让机器能够像人一样具有分析学习能力,能够识别文字、图像和声音等数据。为了为市场资源调度提供智能的决策,新的深度学习技术成为市场需求预测的关键工具。Abbasimehr等人 [18] 提出一种基于多层LSTM网络的市场需求预测方法。所提出的方法通过使用网格搜索方法考虑给定时间序列的LSTM超参数的不同组合,自动选择最佳预测模型。它能够捕获时间序列数据中的非线性模式,同时考虑非平稳时间序列数据的固有特征。值得一提的是,LSTM被证明可以对复杂的长期时序信息进行建模。相比于只考虑最近时刻状态的RNN,LSTM中的神经元会对信息进行判断,符合规则的信息会被留下,不符合的信息会被遗忘。Li等人 [19] 构建了一个具有注意机制的混合GRU-Prophet模型来预测市场销售量。在该混合模型中,分别使用Prophet模型和带有注意机制的GRU模型来捕获时序序列的线性和非线性特征。相比于LSTM,GRU的参数更少,更容易收敛,适用于小规模数据集 [20]。但是数据集很大的情况下,LSTM的表达性能更好。
然而,市场需求时序数据具有复杂的非线性波动模式和诸多的噪声数据。仅仅依靠深度学习技术对市场需求时序数据建模是远远不够的。EEMD是一种针对非线性和非平稳数据的自适应分析方法。它可以根据时序数据的局部特征时间尺度将复杂数据分解为一组规律性较强的IMF和余项,并被广泛应用于辅助建模领域。Wang等人 [21] 利用基于EEMD的ARIMA提高年度径流时间序列的预测精度。此外,他们利用基于EEMD的人工神经网络 [22] 提高了中长期径流的预测精度。
基于目前的工作,我们的工作做出了一些改进。针对非平稳的市场需求时序序列,我们考虑使用EEMD对其进行分解,然后使用GRU分别对得到的IMF和余项进行建模。考虑到数据集规模较小,我们选择训练速度更快、参数量更少的GRU进行预测建模,而非LSTM。实验证明,我们提出的DeepMDF模型的各种评估指标都很好,相比于诸多基准模型,DeepMDF具有更好的泛化能力。尽管我们的工作可以实现对诸如市场需求这种具有复杂模式的非线性时序序列的预测,但仍然存在着一些不足。我们应该考虑对于不同的IMF和余项,使用不同的深度学习模型进行建模。或者,使用传统的时间序列模型和深度学习模型进行混合建模。因此,市场出行需求的预测工作还需要深入探索。
6. 结论及未来的工作
我们提出了一种基于深度学习技术和EEMD的DeepMDF模型,用于预测具有复杂模式的市场需求时序序列,并以新加坡境内不同城市功能区的天然气需求时序序列为例进行了实验。为了挖掘市场需求数据中的复杂规律和非线性模式,我们用EEMD方法对原始的市场需求序列进行分解。为了对分解后得到的IMF和余项进行建模,我们使用适合于小规模数据集的GRU对这些IMF和余项分别进行时序依赖性的计算,且每个计算过程均相互独立。DeepMDF不仅具有较高的精度,而且具有稳定的性能。总的来说,与基准模型相比,DeepMDF具有更好的泛化能力,可以对市场需求时序序列进行准确预测。准确地预测市场需求是企业成功的关键,任何错误的预测都可能导致库存积压或存货不足,从而引起销售额下降以至销售中断等不良后果的发生。
仍有一些问题需要进一步研究。一方面,我们应该深入分析影响市场需求时序序列的影响因素,在建模时融入这些影响因素。另一方面,根据不同的因素对市场需求序列影响程度的不同,我们应考虑在建模融合这些因素时给予它们不同的权重。
致谢
我们感谢来自中国科学院大学经济与管理学院的三位匿名审稿人对此稿件提出的建议。此外,我们感谢两位来自英国伦敦大学学院的英语母语者对英文摘要的撰写所提出的建议。
NOTES
*通讯作者。