1. 背景
如今,就业人才供求的多元化,高校扩招政策的不断推进,我们国家的经济速度增长逐渐变缓,使得大学生的就业形势日益严峻,国家相继出台了一系列政策促进大学生就业。由于社会经济发展变化性导致高校所开设专业与社会的供求不完全匹配和教育质量的下滑,就会带来多多少少的就业压力。从学历上看,研究生初次就业率最高,本科初次就业率略低,高职高专初次就业率最低。从专业看,工科毕业生就业率较高,理科和文史哲类毕业生就业率较低。从毕业院校看,重点大学就业率较高,普通本科和独立学院就业率较低。
研究生的就业方向与所学的专业,以及自己的兴趣、爱好和性格特点密切相关。不同的人能力倾向是有差异的了解并分析自己的能力倾向,十分有助于毕业后的就业选择。本文通过收集某学校的统计学专业的2015级研究生的成绩,利用SPSS软件,进行聚类分析,客观分析其就业潜能,为其提供就业方向指导性意见。
通过聚类分析对学生潜能进行评价,是提高学生就业能力和就业质量的一种定量分析方法。所谓“聚类分析”,它是一种教育统计分析方法,是数据挖掘技术的重要组成部分,它能够在不同的潜在数据中发现数据分布模式,从而找出修正这一模式的方法 [1] 。换言之,通过采集学生的学习成绩数据,对学生的能力倾向进行“聚类分析”,从而有的放矢地对学生进行就业指导。具体操作是:首先,对学生的学业成绩进行“聚类分析”,把学生按某种能力属性分成若干小组(类);再根据各门课程的特点分析每类学生的能力倾向;最后,根据每类学生的能力倾向和不同职业特点进行科学的就业指导。
2. 建立数学模型及分析步骤
1、聚类分析原理
聚类分析又称群分析,聚类是将相近的样本合并为同一类,根据“物以类聚”的思想,研究样本分类问题的一种多元统计方法。所谓类,就是指相似元素的集合 [2] 。聚类分析的研究目的是把相似的东西归成类,根据相似的程度将研究目标进行分类,聚类分析的研究对象分为两种,一是对变量分析(R型),二是对样品进行分类(Q型)。聚类分析中,个体之间的“亲疏程度”是极为重要的,它将直接影响最终的聚类结果。对“亲疏程度”的测度一般有两个角度:第一,样品之间的亲疏程度;第二,变量之间的亲疏程度。衡量样品之间的亲疏程度通常通过某种距离来测度。变量之间的亲疏程度通常可采用简单相关系数或等级相关系数等 [3] 。定义样品间距离的方法也有很多,比如:欧氏距离、绝对值距离、切比雪夫距离、明考斯基距离等。常见的聚类分析方法有层次聚类和K-Means聚类。
2、数据来源
通过收集某学校统计专业的15名2015级研究生的16门主修课程的成绩,分别有经典著作选读、现代西方经济学、中国特色社会主义理论与实践研究、经济应用数学、应用数理统计、金融数学、英语、英语口语与听力、马克思主义与社会科学方法论、测度论与概率论基础、社会科学软件spss、MATLAB软件包、计量经济学的方法与应用、非参数统计、应用多元统计方法、时间序列分析,如表1所示。
将这16门主修课程的成绩输入SPSS17.0软件对其进行聚类分析。还有一些选修课程在表1中没有体现出来,选修科目是根据个人爱好选择的,包括数据模型与决策有13人选,空间统计学有14人选,随机过程与应用有13人选,现代统计模型有11人选,精算数学有5人选等等。还有一些学生的科研成果,综合成绩在表1中也没有体现出。
本文首先是对15名研究生主修成绩聚类分析做客观分析,其次是通过他们的三年来的科研成果和综合成绩做出一些主观分析。
3、建立数学模型
1) 本文所采用的是聚类分析数学模型:
样本间的距离用的是欧氏距离平方
其中
表示样品
与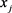 的距离。
的距离。
注:为方便运算把英语一和英语二合并取平均数。
度量变量间的亲疏程度关系用的是Pearson correlation皮尔逊相关系数,在统计学中,皮尔逊积矩相关系数用于度量两个变量X和Y之间的相关(线性相关),其值介于−1与1之间。在自然科学领域中,该系数广泛用于度量两个变量之间的相关程度。它是由卡尔·皮尔逊从弗朗西斯·高尔顿在19世纪80年代提出的一个相似却又稍有不同的想法演变而来的。这个相关系数也称作“皮尔森相关系数r”。
4、分析步骤
聚类分析有很多,比如系统聚类、动态聚类等,本文用的是系统聚类,所谓的系统聚类先将n个样品各自看成一类,然后规定样品之间的“距离”和类与类之间的距离。选择距离最近的两类合并成一个新类,计算新类和其它类(各当前类)的距离,再将距离最近的两类合并。这样,每次合并减少一类,直至所有的样品都归成一类为止。
第一步,建立15名学生成绩的Excel样本文档如上述(表1)。
第二步,打开并进入SPSS系统,在“文件”菜单中,将上述表中的数据导入系统中。
第三步,进入系统分析功能,在“分析”菜单“分类”中选择“系统聚类”命令。
第四步,在弹出的系统聚类分析对话框中,从对话框左侧的变量列表中选择“经典著作选读、现代西方经济学、中国特色社会主义理论与实践研究、经济应用数学、应用数理统计、……”等变量,使之添加到右边的变量框中。
第五步,确定变量的R型聚类,单击统计量按钮,选择相似性矩阵,聚类成员中选择单一方案,聚类成员写3。
第六步,单击绘制按钮,选择树状图,选择冰柱中的所有聚类,方向为垂直。
第七步,单击方法按钮,选中聚类方法项,并选择组间聚类,度量标准中的区间项选择Pearson相关性。
第八步,输出统计量和图。
第九步,单击确定按钮,SPSS自动完成分析过程。
3. 结果分析
1、第一部分输出的是系统Q型聚类的分析结果(见表2),从结果中可以看出15个样本都进入了聚类分析。
2、输出SPSS系统聚类分析各变量的距离矩阵(见表3)。这部分输出的是系统R型聚类分析结果。从中可以看出各个变量之间的距离。
3、聚类表(见表4)。在表格中的第一列表示的是聚类分析的第几步;第二列、第三列表示聚类中哪两个样本或小类聚成一类;第四列的系数表示的是相应的样本距离或小类距离;第五列、第六列表示本步聚类中,参与聚类的是样本还是小类。0表示的是样本,数据n (非0)表示由第几步聚类产生的小类参与本步聚类;第七列表示本步聚类的结果将在下面聚类的第几步中用到。如表4所示。
表5是R型系统聚类分析后,聚类成3个类时变量的分类情况。
a值向量间的相关性,已使用。
如图1,聚类分析后的冰柱图,不同的群集数可以分不同的几类。
4. 结果及讨论
根据上述分析所得到的3个分类以及我们分别对每个类的定义,可以看到(表6),第一类学生在“经典著作选读、现代西方经济学、中国特色社会主义理论与实践研究、经济应用数学、英语口语、听力、应用数理统计、测度论与概率论基础、金融数学、应用多元统计方法”等方面学习能力比较强,具有较
强的抽象思维、逻辑推理和外语基础,适合于从事科学研究工作,因此可以建议这些学生继续深造,有条件报考研究生的应动员其报考研究生,暂时不能考研的也要抓紧学习以争取进一步提高;第二类学生行政管理和政治敏锐力较强,建议他们可以去考公务员,将来可能会在政界取得比较大的成就;第三类学生,处理数据和动手能力较强,他们比较适合从事本专业技术方面的工作,建议他们进一步打好基础,深入掌握实际中的。根据个别同学的选修课程、综合成绩、科研成果进行一些个人的主观评价,仅供参考。15名学生中,有5个学生选修了精算数学,并且成绩在都在90分以上,说明他们有扎实的计算能力,可以考虑比如保险方面的工作,只有一个学生选修了英语口语、听力二,成绩为84,说明该学生在英语表达不错,有学习语言的潜力,可以考虑进一步学习或者在学习一些其他外语。综合成绩大家都在35分左右,最低33.64分,最高36.8分,差距不大,但在科研成果方面差距比较大有的为0分,最高为201分,大部分在五六十分,可以看出科研成果较高的人应该适合研究型,可以继续深造读博。
本文运用SPSS软件对15名在校研究生的考试成绩进行了聚类分析,根据聚类分析的结果判断其相应的就业潜能,具有一定的指导意义,相应地分析方法运用到大学生就业指导领域,为大学的教育教学和就业指导提供理论依据 [4] 。但是需要指出的是,决定学生就业潜能的因素是多方面的,考试成绩只能在一定程度上反映学生的学习能力,不能完全体现其就业潜能,仅仅凭借对课程成绩来判定学生的就业潜能具有片面性。因此,我们需要进一步研究和考察学生就业潜能分析,制定合理的评价体系,运用科学的统计方法,最大程度上准确断定学生的就业潜能。