1. 引言
学业预警是高校在教育管理实施过程中,对学生在校期间已经发生或者即将发生的学习方面的问题和学业上的困难进行危机干预,并有针对性地采取防范和补救措施,通过学校、学生及其家长三者之间的沟通与协作,帮助学生克服学业困难,使学生重返正常的学习、工作与生活常态并顺利完成学业的一种信息沟通和危机干预制度 [1]。
普渡大学的Course Signals (课程信号)系统是数据量化和监测学生学习状态的系统。对课程GPA成绩、等级考试成绩、排名、学术经历及学生登录课程网站频率等进行了分析。普渡大学的研究者发现,那些曾经被亮黄灯,即处在中度学业失败危险的学生,收到预警邮件后会在课堂上表现得更好。而那些直接被亮红灯,即处于高危群体的学生,即便收到了预警邮件,他们在课堂表现上也不会有太大改观。由此也可以看出,早期预警对成绩不佳的学生顺利完成学业十分重要。国外有预测系统性银行危机的模型,采用了信号方法和Logit模型的方法进行研究 [2]。为了防止钢铁企业事故发生,利用组合加权和灰色预测模型对钢铁企业事故预警系统进行了探讨 [3]。BP神经网络模型应用于寿险偿付能力预警体系,利用改进的BP网络预测寿险公司的偿付能力 [4]。
2007年广西师范学院的陈钦华按照以学生为本、过程管理和目标管理的统一、全面性、便利性原则,设计了学业预警机制 [5]。深圳大学管理学院华金秋介绍了我国台湾高校学业预警制度背景、规定和特点,然后就建立大陆高校学习预警机制进行了探讨 [6]。2009年苏州科技大学的丁福兴、蔡熹芸、翁丽祥针对苏州科技大学的现实情况,以该大学的学习困难群体为研究对象,选取2007年9月和2008年9月的学籍处理数据进行比较,得出的研究结论认为:实施学生学业预警措施在降低学籍处理率方面的绩效是显著的 [7]。2010年张海舰等提出了以学生的平均绩点来作为界限标准的建议,并就学业预警的工作程序和运行进行了论述,但是如何公平评价学生的问题没有得到解决 [8]。2011年范冰通过构建高职院校学业预警机制,提出应高度重视、加强防范初期的准备不足,应利用教务管理系统建立学生预警数据库,应加强辅导员的监管工作力度,应加强落实后期等措施 [9]。关于学业预警模型的建立,2015年郑俊玲基于核主成分分析建立了学业预警模型 [10]。
综上所述,国外各高校已经具备了相对完善、严格、科学的学业辅导制度,而我国的学业预警机制还没有深入实施,大部分停留在定性分析的研究上,因此,本文针对数据难以人工处理、复杂多样的特点,选取判别分析方法建立学业预警模型,对大量数据进行量化分析处理,对需要预警的指标进行分析和计算,利用现有数据总结得出判别分析方法的出错率低,为预警的确定和预警等级的划分提供直观的依据,有利于采用定量的方式为学业预警工作提供高效率高质量的保障,相关部门可依据分析完成后的数据商讨如何指导学业预警工作的展开,进行接下来的学业帮扶工作。
2. 大学生学业预警主要指标的选取
学业预警的前提是建立一套科学的预警评价指标体系,它决定着预警对象的准确性和预警程度的精确性,还直接影响着后续帮扶与激励的效果。指标的选取要能够反映评价对象的各方面状况,而且针对指标采集的数据应该容易收集、计算或估计的。
根据指标体系建立的原则以及文献资料,再结合本校的实际预警情况,本文选取了日常学习时间/周,学生选课数目,学期迟到、早退、逃课次数,学期补考课程学分,学期成绩总和共五个指标构成学业预警模型的指标体系。
数据采用黑龙江八一农垦大学的学业预警评价体系:根据学生的实际情况及所产生影响的程度,发出不同等级的预警信息,分为口头预警、蓝色预警、黄色预警、橙色预警、红色预警五个级别。此次选取了黑龙江八一农垦大学某学期获得学业预警40位同学的相关数据来进行模型的建立,采集的指标有日常学习时间,选课数目,学期迟到、早退、旷课次数,补考课程学分,学期六门成绩总和这五个指标。其中,las、xtg、erd、ers四位同学作为待判样本。借助的数学分析软件为SPSS。
3. 判别分析模型建立
判别分析是多元统计中用来判别样本类型的统计分析方法,在已知的主题下用某种方法分成几类情况,判断新样本属于什么类型的多变量统计分析方法。通常使用判别分析方法来测量新样本与每个已知样本的接近度,即判别函数,同时规定一种判别准则来判定新样本的归属。判别准则是衡量新样本与已知群体接近度的理论基础和方法标准。常用的有距离判别准则、Fisher判别准则、贝叶斯判别准则等。
3.1. 距离判别模型的建立
基本思想 [11]:首先根据已知分类的数据,计算每个类别的重心,即分组(类别)的平均值,距离判别准则是对任何新样本的观测值,如果它与第i类的重心距离最近则认为来自第i类。
1) 检验变量在各分类上均值是否有显著差异
SPSS软件中给出了表1单变量方差分析的结果,分别检验了日常学习时间,选课数目,学期迟到、早退、旷课次数,补考课程学分,学期六门成绩总和这五个变量在口头预警、蓝色预警、黄色预警、橙色预警、红色预警五类中的均值是否相等。原假设是各类均值相等,备择假设是不等,如果接受原假设,说明利用这五个变量进行判别分析没有意义。从该表中可以看出计算出的显著性除“选课数目”无法计算以外,其余都小于0.01,故可以参与判别分析,变量“选课数目”是不适合的。

Table 1. Tests of equality of group means
表1. 群组平均值的等式检定
a无法计算,因为在每一个群组中此变量都是常数。
2) 建立判别函数式
SPSS软件中的分类函数系数表给出了判别函数的系数和常数项见表2,从该表中得到距离判别中的判别函数为:
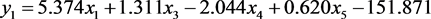
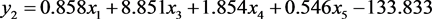
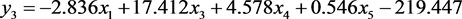


利用SPSS的Compute功能将所有样本的变量值带入到判别函数式,可以得到所有样本的判别函数式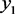 ,
, ,
, ,
,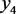 ,
,
 ,其中las的判别函数值分别为11.57,285.73,470.62,562.72,618.75;xtg的判别函数值分别为63.68,191.05,236.05,220.99,149.94;erd的判别函数值分别为104.85,143.92,107.41,28.52,−116.39;ers的判别函数值分别为115.13,148.93,106.59,23.00,−127.15。
,其中las的判别函数值分别为11.57,285.73,470.62,562.72,618.75;xtg的判别函数值分别为63.68,191.05,236.05,220.99,149.94;erd的判别函数值分别为104.85,143.92,107.41,28.52,−116.39;ers的判别函数值分别为115.13,148.93,106.59,23.00,−127.15。
因此将las归为第五类;将xtg归为第三类;erd归为第二类;将ers归为第二类。这正是表2给出的用此判别函数对待样品判别的结果。
3) 分类结果
从表3可以看出用此判别函数对所有样品判别的结果和误判概率以及用交叉验证法判别结果和误判概率。可见有100%的正确率。
3.2. Fisher判别法模型的建立
基本思想 [12]:将 组
组 维的数据投影到某一个方向,
维的数据投影到某一个方向,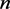 代表所选取的指标个数,投影就是将
代表所选取的指标个数,投影就是将 维空间的样本投影到
维空间的样本投影到 空间中。在
空间中。在 维空间中找到组间距离最大的线性组合作为第一Fisher判别函数,以此类推得到第二、第三Fisher判别函数。
维空间中找到组间距离最大的线性组合作为第一Fisher判别函数,以此类推得到第二、第三Fisher判别函数。
1) 建立判别函数
从SPSS中的典型区别函数系数表中可以得到未标准化典型判别函数的系数向量。根据此系数向量可以写出4个未标准化的典型判别函数:

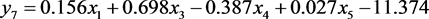


Table 2. Classification function coefficients
表2. 分类函数系数
Table 3. Classification resultsa,c
表3. 分类结果a,c
a100.0%个原始分组观察值已正确地分类;b仅会针对分析中的那些观察值进行交叉验证。在交叉验证中,每一个观察值都会依据从该观察值之外的所有观察值衍生的函数进行分类;c100.0%个交叉验证已分组观察值已正确地分类。
利用SPSS的Compute功能将所有样本的变量带入到以上4个判别函数中,可以得到所有样本的判别函数值(表4)。待判样品的函数值分别为(27.94, 2.44, −0.02, 16.56),(11.58, 0.25, −4.30, −18.41),(1.90, 0.05, −7.20, −20.30),(1.26, −0.44, −7.79, −20.36)。
2) 函数结果显著性的Wilks’ Lambda检验
表5给出了典型判别函数的有效性检验。Wilks’ Lambda范围在0至1之间,值接近0表示组均值不同,值接近1表示组均值在统计意义上没有不同。由于Wilks’ Lambda统计量的分布表不易找到,一般化为卡方统计量。df自由度是用于计算显著性水平的自由度。sig显著性水平是零假设被拒绝的概率,即拒绝零假设时犯第一类错误的概率。从表中可以看出判别函数显著性检验的sig值分别为0.000,0.518,0.930,0.796。除了第一个以外都大于0.05,故只有第一个判别函数显著,能够用来判别样品的归属。
3.3. 贝叶斯判别法模型的建立
贝叶斯的统计思想 [13]是假设对研究的对象已有一定程度的认识,常用先验概率分布来描述这种认识,然后抽取一个样本,用样本来修正已有的认识(先验概率分布),得到后验概率分布。各种统计推断都通过后验概率分布来进行,将贝叶斯思想用于判别分析就得到贝叶斯判别法。
1) 以口头预警、蓝色预警、黄色预警、橙色预警、红色预警所含学生的频率作为各类的先验概率,即
 ,
, ,
, ,
,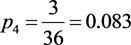 ,
,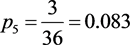
同表6结果。
2) 建立贝叶斯判别函数
表7给出了贝叶斯判别中式的判别函数的系数和常数项。
从该表可得贝叶斯判别中的5个判别函数为

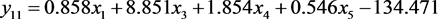



Table 4. Canonical discriminant function coefficients
表4. 典型区别函数系数
非标准化系数。
Table 5. Wilks’ Lambda (λ)
表5. Wilks’ Lambda (λ)
Table 6. Prior probabilities for groups
表6. 群组的事前机率
3) 判别函数准确性结果检验
利用回代法和交互验证法对判别结果的准确性进行验证。从表8可知,准确率为100%。
3.4. 学业预警模型比较
距离判别模型中的指标体系“选课数目”对分析无意义。但是预测方法得到的结果与实际情况一致,未出现误判现象,能够为学业预警提供技术支持。
Table 7. Classification function coefficients
表7. 分类函数系数
Table 8. Classification resultsa,c
表8. 分类结果a,c
a100.0%个原始分组观察值已正确地分类;b仅会针对分析中的那些观察值进行交叉验证。在交叉验证中,每一个观察值都会依据从该观察值之外的所有观察值衍生的函数进行分类;c100.0%个交叉验证已分组观察值已正确地分类。
Fisher判别模型中只有1个判别函数显著,能用来判别样品的归属,而且结果与距离判别结果不一致,得到的结果不准确。
贝叶斯判别方法中,在各类预警所含学生的频率作为各类的先验概率的情况下,所得判别分析的结果误判率为0。
4. 结论
本文就学业预警工作中的情况加以判别分析方法的应用,使学业预警工作由定性转变为定性定量相结合;确定了建立学业预警模型的指标,建立了距离判别分析模型、Fisher判别分析模型、贝叶斯判别分析模型对学业预警情况进行了预测,其中距离判别法、贝叶斯判别法的模型,这两种模型的误判率为0,预测精度高,可靠性强,同时为学业预警等级评价中提供可供参考的评价指标;该模型由于数据、条件的限制,所以还存在很多不足之处,如果能够尝试更多条件,相信会对学业预警机制提供指导意义。
基金项目
2017年黑龙江省高等教育教学改革一般项目(编号:SJGY20170441);2018年黑龙江省高等教育科学规划重点课题(GBB1318087);2017年大庆市哲学社会科学规划研究项目(编号:DSGB2018110);2017年黑龙江省大学生创新创业重点项目(编号:2017LXY04)。