1. 引言
软件测试对软件产品质量和生产率的提高有着举足轻重的作用。变异测试是一种行之有效的软件测试方法,可用于测试充分性的评价和测试用例的增强。变异测试基于熟练程序员假设和耦合效应 [1] ,通过使用变异算子系统地模拟程序中可能存在的各种缺陷产生变异体,然后求解能够杀死这些变异体的测试集 [2] 。变异测试主要应用于单元测试,也有学者将其应用于集成测试、面向对象测试、面向方面测试等方面 [3] [4] [5] [6] [7] 。一般情况下,根据变异评分衡量测试集发现程序变异体中错误的能力。一个能将变异体M与源程序P区分出来的测试用例必须满足三个条件 [8] :可达性(必须存在一条从M的开始语句到变异语句的执行路径);状态感染性(通过执行变异语句,M和P的状态彼此不同);状态传播性(通过执行变异语句,M和P的状态差异一直传播到变异体执行结束)。
如何生成测试用例在变异测试中至关重要,现有的变异测试用例生成方法主要有CBT (Constraint-Based Test data generation,基于约束的生成方法) [9] 、DDR (Dynamic Domain Reduction test data generation,动态域削减方法) [10] 、DRD (Domain Reduction approach with Data dependence,考虑数据依赖的域削减方法) [7] 和GA (Generation Algorithm,遗传算法生成变异测试用例的方法) [11] 。CBT采用控制流分析变异体的可行性条件建立约束关系,是一种高效的测试用例生成方法,但CBT难以处理对输入变量有依赖的判断条件和表达式;DDR根据控制流动态地求解路径约束,改进了对输入变量有依赖的判断条件和表达式的处理,弥补了CBT存在的缺点,但未考虑数据依赖;DRD将数据依赖考虑到约束系统中并使用DDR进行求解,但未权衡加入的数据依赖结点的重要性;GA基于控制流测试充分性准则构建适应度函数模型,考察多种程序结构进行测试,但这种测试不考虑数据流约束,往往是不充分的,且生成测试用例的效率低。
为了更高效地生成变异测试用例,本文提出了一种结合数据流约束的变异测试用例生成方法。此方法充分考虑数据流约束并且权衡所加入数据依赖结点的重要性,首先,结合控制流约束和数据流约束建立合适的适应度函数模型;然后,将测试用例求解问题转换为适应度函数优化问题,基于遗传算法所具备的全局优化功能进行求解,使用个体适应度指导测试用例的进化和选择;最终得到目标测试用例。
2. 结合数据流约束的变异测试用例生成方法
本文的方法关注变异语句中变量的定义和使用,考虑变异语句所依赖的数据流约束,使用了一种新的适应度函数模型,逐步引导测试用例过程。首先,将控制流约束和数据流约束结合起来,提供了充分的代码覆盖,共同构建适应度函数模型;然后,使用遗传算法,根据遗传算法“优胜劣汰”的进化特点,依据测试用例的适应度自适应调整搜索方向;最终高效地生成变异测试用例。图1为结和数据流约束的变异测试用例生成方法。如图1所示,本方法由适应度函数建模和测试用例生成两大部分组成。
适应度函数建模部分开始于被测试程序,分别根据程序控制流图CFG (Control Flow Graph)和程序数据流图DFG (Data Flow Graph)计算得到控制流约束函数
和数据流约束函数
,然
后组合二者构造出适应度函数
;测试用例生成部分将用例生成问题转化成了适应度函数
的优化问题,使用遗传算法优化适应度函数,通过计算每一个测试用例的适应度值,评估用例的优劣,指导对用例的搜索朝着最大化目标分支覆盖的方向,逐渐将测试集收敛至搜索空间的最优点,直至得到最终测试用例。
2.1. 适应度函数建模
适应度函数是基于搜索的方法的核心,它引导测试用例生成过程朝着搜索空间中适应度最好的领域进行,直接决定着搜索结果的好坏。本文的方法改变以往采用控制流约束建立适应度函数模型的思想,将控制流约束和数据流约束结合起来,采用分支函数叠加法建立适应度函数模型,根据个体适应度值指导评价测试用例并指导其选择和进化。适应度函数建模部分如图2所示,分3个主要步骤完成:1) 构建控制流约束函数
;2) 构建数据流约束函数
;3) 建立适应度函数模型。
1) 构建控制流约束函数
控制流约束用于满足可达性条件,其计算依赖于被测程序的CFG和内部结构。首先分析CFG上变异语句的逼近水平,然后根据变异语句所在分支的谓词表达式计算分支距离,最后将逼近水平和分支距离线性叠加构造出控制流约束函数。
逼近水平用来度量测试用例如何覆盖目标变异语句,表示测试用例X的执行路径与目标变异语句的偏离程度,记作
,它是根据未被执行的目标变异语句的控制依赖结点的数量计算的。举例说明,程序1是示例程序,图3是程序1的控制流图。假定语句4是程序1的目标测试语句,给出三组不同的输入数据:
、
、
,相应的穿越路径为
、
和
。在这三组不同的测试数据中,
和
都要执行条件语句3,而
则在执行完条件语句2之后偏离目标语句4所在的分支,所以测试数据
和
比测试数据
的适应度要好。因此,分别定义
、
和
的逼近水平为:
、
和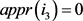 。
。
分支距离用来评估目标分支被选择的远近程度,表示使目标分支条件为真或假的满足程度,记作
,它是根据目标变异语句所在分支的条件语句计算的,具体计算表达式如表1所示 [12] 。
越小,测试用例的执行路径对目标变异语句的覆盖程度越好。
控制流约束函数记为
,定义
为
和
的和,如式(1)所示:
(1)
其中:
为标准化分支距离,如式(2)所示:
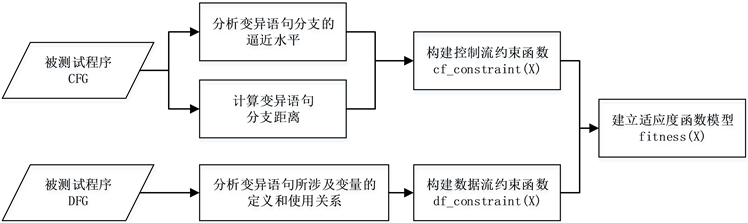
Figure 2. Mapping of fitness function modeling
图2. 适应度函数建模示意图

Figure 3. The control flow graph of program 1
图3. 程序1的控制流图

Program 1. Sample program
程序1. 示例程序

Table 1. Branch distance calculation table
表1. 分支距离计算表
(2)
控制流约束函数
的值越小,说明测试用例越满足必要性条件;反之,若控制流约束函数
的值越大,则说明测试用例越偏离必要性条件。
2) 构建数据流约束函数
数据流约束用于表示测试用例的执行路径对目标变量定义——使用路径的覆盖程度,由变异语句中变量的定义——使用路径覆盖定义。注意,构造DFG时,CFG中的结点、边和所有路径都在DFG中保留,CFG中的结点对应于DFG中的基本块。计算数据流约束时,首先由DFG计算得到变异语句变量的定义表和使用表,然后将定义表和使用表信息合并得到定义——使用表,最后根据定义——使用表计算数据流约束。
数据流约束函数记为
,定义其计算如式(3)所示:
(3)
其中:
为测试用例的执行路径覆盖目标变量的定义——使用对数量;M为测试用例集的规模。若数据流约束函数
的值越小,即
的值越大,则测试用例的执行路径提供的代码覆盖越充分;反之,若数据流约束函数
的值越大,即
的值越小,测试用例的执行路径提供的代码覆盖越不充分。
3) 建立适应度函数模型
建立合适的适应度函数模型是本文方法的关键,适应度作为测试用例优劣的衡量标准,指导测试集的进化和测试用例的选择。适应度函数记为
,将其定义为控制流约束函数和数据流约束函数的线性叠加,如式(4)所示:
(4)
其中:a、b为控制流约束函数和数据流约束函数的权重系数,其定义域均为
且
。
X包含全部测试用例是个体适应度函数
的充要条件。由于控制流约束函数
越小,测试用例越满足可达性条件,数据流约束函数
越小,测试用例的执行路径提供的代码覆盖越充分。所以,个体适应度函数
越小,则测试用例的执行路径与目标变异语句间的距离越小,且对变异语句中变量的定义——使用路径覆盖越充分。因此,可将测试用例生成问题可转换为适应度函数
的最小化问题。
2.2. 测试用例生成
为了提高生成测试用例的效率,本文方法将测试用例生成问题转换成了适应度函数
的最小化问题,并使用遗传算法解决。根据适应度值动态调整测试用例的生成过程,提高其质量并且减少测试冗余。
测试用例生成过程开始于随机法生成的初始用例集,然后按照适应度函数
计算初始用例集中各用例的适应度,评估用例的优劣;种群进化时,选择出优良个体来参与交叉、变异操作得到新一代用例集,最后判断终止条件是否满足,若满足,则选择出目标用例,若不满足,则依据个体适应度逐渐将用例集收敛至搜索空间的最优点,不断进化,直至生成最优测试用例。具体流程如图4所示。
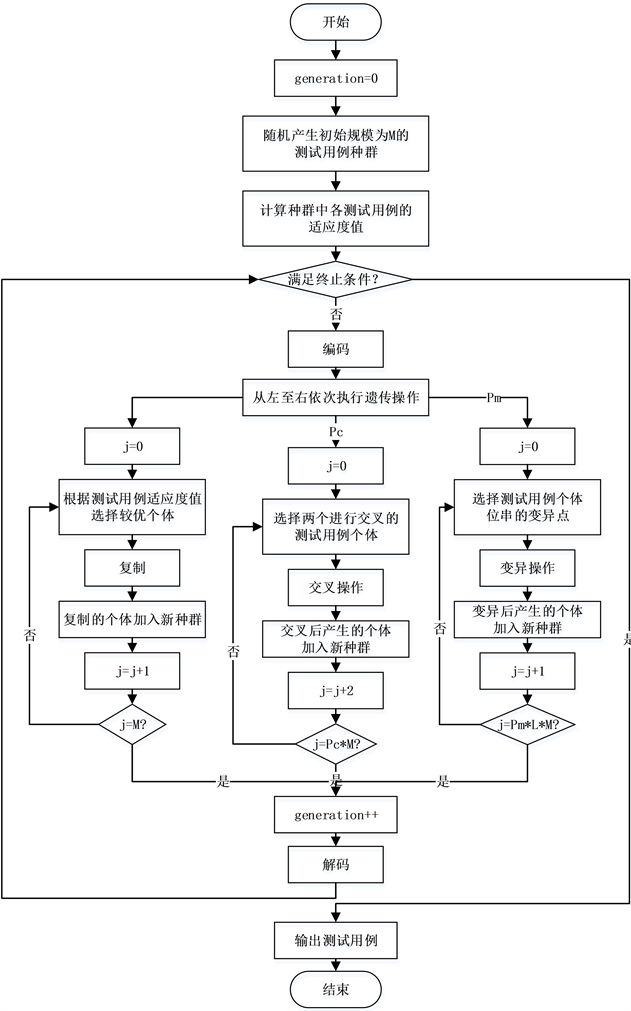
Figure 4. The test case generation flow chart
图4. 测试用例生成流程图
本方法生成测试用例的过程,其实是适应度函数的优化过程。下面简单介绍使用遗传算法实现该方法的几个重要操作的具体操作:
1) 初始化测试用例集:为保证测试用例集的多样性,采用随机方法生成规模为M的初始测试用例集;
2) 编码形式:由于二进制编码易于表达、操作简单的优点,本方法采用二进制编码形式对原始个体进行编码;
3) 计算测试用例适应度:根据
计算测试用例的适应度以指导测试集的进化;
4) 实施选择操作:有多种不同的选择策略,本方法采用轮盘选择法,将一个圆分为种群规模大小个扇形区间,区间大小为测试用例的相对适应度值。轮盘选择法保证了各用例被选中的概率与适应度值成正比,与本文适应度函数优化的思想相一致,根据测试用例的相对适应度,将父代的优良测试用例复制到子代;
5) 实施交叉操作:此操作的主要目的就是在解空间中搜索不同的可行解。本方法以固定的交叉概率
为参照,在测试用例集中随机选择两个用例,对其实施动态概率的随机点交叉操作;
6) 实施变异操作:变异操作用于补偿基因丢失情况,保持个体多样性。本方法以固定的变异概率
为参照,对用例实施动态概率的变异操作;
7) 终止条件:当迭代次数达到预定终止代数或用例适应度达到预定值时算法终止。
3. 实验分析
为了实际证明本文方法的可行性,分别从测试用例的生成效率和检错能力两个方面进行了实验。
1) 测试用例生成效率实验结果
以三角形形状判定程序为例,对变异生成的4个一阶变异体进行了实验,该程序以输入的三个整数为三角形的三条边,输出三角形的形状。根据经验值和实验比较,遗传算法交叉概率
选用0.7,变异概率
选用0.05,最大迭代次数选用100,种群规模M选择20,对每个变异体进行10次实验。实验结果如表2所示。
从表2可以看出,对于使用ROR变异算子生成的2个变异体,当生成数量优于HGA方法的用例时,本文的方法在平均迭代次数上减少了56.1%;对于使用AORB变异算子生成的2个变异体,当生成与HGA方法数量相等的测试用例时,本文的方法使用的平均迭代次数是HGA方法的35%,减少了65%。图5为表2中两种方法生成测试用例的平均迭代次数对比图,明显显示处了本方法在迭代次数上的优势,所以本的方法表现出了较高的测试用例生成效率。
2) 测试用例检错能力实验结果
选取参数个数和语句复杂度不同的程序,分别使用随机方法、依据路径覆盖的混合遗传算法HGA方法和本文方法生成一定数量的测试用例进行实验。程序Mid是一个求3个整数中间值的程序,该程序结构简单,主要用来测试本文方法在简单结构程序中的应用;程序TriTyp是三角形形状判定程序,其特点是条件语句复杂,主要用来评估本文方法在复杂语句程序测试中的应用;程序Quad求解一元二次方程的
Table 2. Experimental results of test case generation efficiency
表2. 测试用例生成效率实验结果
根,程序Sample判断两数组内数据与目标数据的相同程度,NextDate求解输入日期的下一天,用来测试本文方法在复杂路径程序测试中的应用。实验结果如表3所示。
如表3,计算和比较变异评分可知,对程序Mid使用HGA和本方法生成变异测试用例得到的变异评分相同,相比于随机方法高出了9.5%;对程序TriTyp使用本方法得到的变异评分比HGA方法高3.5%,比随机方法高33.3%;对于程序Quad、Sample和NextDate,使用本文方法得到的变异评分比HGA方法分别高出了5.1%、4.3%和8.5%,相比于随机方法有较为明显的提高,分别高出了41%、26.1%和29.6%。
三种方法所生成用例分别杀死的变异体数量对比如图6所示。从图中可以看出,使用本方法生成的
Table 3. Experimental results of test case error detection ability
表3. 测试用例检错能力实验结果
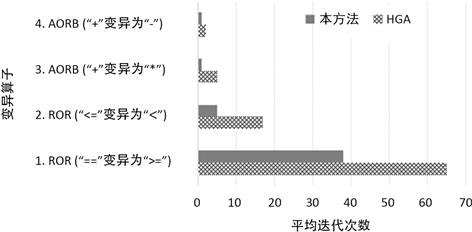
Figure 5. Average iteration number contrast
图5. 平均迭代次数对比
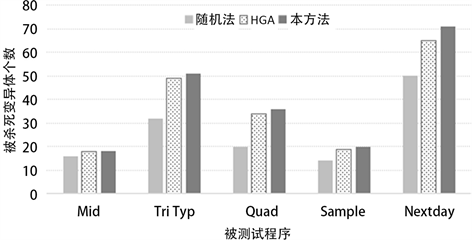
Figure 6. Comparison of the number of killed mutants
图6. 被杀死变异体数量对比
测试用例杀死的变异体数量最多,比随机方法和HGA的变异体杀死数量都有一定程度的提高,表现出了更强的错误检测能力。
4. 结束语
本文提出了一种结合数据流约束的变异测试用例生成方法,充分考虑变异语句中变量数据依赖的影响。首先对被测试程序的预处理分析程序结构和语句关系,通过变异语句分支路径执行条件的组合和非冲突等价类划分量化控制流约束;然后,使用不同测试用例执行路径中变异语句所涉及变量的定义——使用路径覆盖构造数据流约束关系,结合控制流约束和数据流约束共同建立合适的适应度函数模型;最后,基于遗传算法种群进化特征和优越的全局搜索能力,依据测试用例个体适应度自适应调整测试种群的搜索方向,生成测试用例。本文通过实验证明了本方法生成测试用例的效性,以及与其他方法之间的对比实验更进一步验证了本方法的变异体检测能力。
本文的方法主要应用于软件单元测试中一阶变异测试用例的生成,将本文方法应用于自动生成杀死高阶变异体的测试用例还有待进一步的研究。满足多变异语句的分支覆盖条件,且在对变异语句中变量的定义——使用路径覆盖尽可能多的条件下,充分考虑变异语句之间的依赖关系将可能生成同时杀死多个变异体的测试用例。
基金项目
国家自然科学基金资助项目(11575138);陕西省工业公关项目资助项目(2013K06-20);中央高校基本科研业务费专项基金资助项目(XJJ2015122);轨道交通工程信息化国家重点实验室开放课题项目(SKLK16-08)。