1. 引言
随着病毒的传播与繁殖,新冠病毒发生变异,并且产生了十几种变异毒株,比如阿尔法、贝塔、德尔塔等,现如今,奥密克戎变异毒株已经在世界范围内占据主导地位。针对疫情多点式、频发式爆发,建立数学模型在疫情预测与防控发挥关键性作用。1926年Kermark [1] 等提出了SIR仓室模型,在流行病研究分析方面得到了广泛使用,也运用于对COVID-19进行预测分析 [2] [3] [4] 。本文运用其变体形式SEIAHRD模型探讨2022年上海疫情发展情况。
原始SIR模型中假设参数在整个流行期间是保持不变的 [5] 。然而在现实世界中,估计的模型参数在整个观测周期内不是一成不变的,更为重要的是,在流行病期间人们会自觉地戴口罩、减少外出等行为,即便在没有疫苗和政府干预等情况下,也会显著地改变参数值,进而改变COVID-19的传播动态。
一般情况下,传染病模型中的参数的值可以从其他文献得出的实验结果或者经验进行估计,Wang [6] 等根据之前研究者得出的实验结果设置了SEIR模型的参数;Fang [7] 等在SEIR模型的基础上,使用数据驱动分析的方法,并根据拟合的结果对参数进行调整,通过这些方法得出的结果无法摆脱人为主观因素的影响。现如今,智能优化算法采用自动搜索的方式寻求最优参数已经成为医学领域中常用的优化方法,比如粒子群算法,Kennedy和Eberhart [8] 通过模拟鸟类觅食行为提出了一种基于群体智能的全局随机搜索算法,也就是粒子群算法。Navaneeth和Suchetha [9] 提出了一种组合架构,并引入粒子群算法进行参数优化。Zeng [10] 等开发了具有切换延迟的粒子群算法(PSO),并将其应用于支持向量机(SVM)模型的参数优化。罗丹 [11] 等提出了自适应粒子群算法与SEIR模型结合,对模型中的关键参数进行反演计算。
基于以上讨论,我们主要研究目标是根据新冠肺炎变异毒株奥密克戎的特征和传播机制进行模型修正。同时,我们尝试使用自适应粒子群算法作为一种可用的随机方法优化参数进行求解。优化求解的目标是通过求解改进的SEIR模型的参数,使实际数据与预测数据之间的误差最小化;最后,使用这些与环境相关且随时间变化的参数去评估政策干预措施在每个阶段对COVID-19的相对有效性。
2. 基于自适应混沌搜索搜索算法的SEIR模型
2.1. 自适应混沌搜索算法(ACPSO)
在粒子群算法(PSO)中,通过对粒子随机初始化位置和速度到达搜索空间,通过适应度值来评价个体的优劣程度。假设由N个粒子在维搜索空间中通过次迭代实现对优化目标的求解,其中第i个粒子表示一个M维的向量,记为:
(1)
第i个粒子的移动速度记为:
(2)
PSO算法中,个体极值指在整个迭代过程中,第i个粒子搜寻得到的最优位置,记为:
(3)
在整个迭代过程中,N个粒子搜寻到的个体极值中的最优位置为全局极值,记为:
(4)
在搜寻到个体极值和全局极值后,根据下式更新粒子的速度和位置:
(5)
(6)
式中,
为惯性权重,用来表示当前代粒子速度对之前代粒子速度的继承程度,c1、c2为学习因子,分别是社会因子和认知因子,决定粒子个体经验和群体经验对粒子运行轨迹的影响。
PSO算法能够有效地解决非线性优化问题,和其它的随机算法比较,PSO算法可以高效得到高质量的解,收敛性较稳定,在很多领域得到广泛地应用,但是在迭代后期,存在收敛速度慢,并且应用于较复杂情况时可能出现结果精度不高,搜寻不到最优解的问题。基于此本文考虑以下两方面:
1) 自适应惯性权重;
惯性权重
是粒子群算法中非常重要的控制参数,可以用来控制算法的局部与全局搜索能力:
较大时,全局收敛能力较强,局部收敛能力较弱;
较小时,局部收敛能力较强,全局收敛能力较弱。因此,在搜索过程中,对
进行动态调整,本文自适应惯性权重
更新公式如下:
(7)
式中,
为当前粒子的适应度值,
、
分别为当前N个粒子适应度值的平均值和最小值。该更新方法将
的变化与粒子位置结合起来,线性地使
逐渐增大,增加了算法的全局多样性,减少了陷入局部最优解的概率,提高粒子群算法的性能。
2) 提取全局最优解进行混沌搜索。
混沌是非确定性动力学系统出现不可预测的随机运动形式,具有随机性,遍历性,并且对初始值敏感的特点。利用混沌搜索的遍历性对全局最优值进行混沌搜索,即在解空间中搜索当前全局最优解的附近区域,可以快速跳出局部最优。
(8)
式中,将随机生成的混沌变量
映射到优化变量
区间,得到位置
。
(9)
式中,对
进行混沌搜索得到新值
。
(10)
式中,对混沌变量
进行更新。
ACPSO运算以目标函数最小化为目标,参数优化流程见图1。
2.2. SEIAHRD模型的建立
经典的SEIR模型 [12] 模拟人在传染病过程中四种不同状态之间动态转化的过程见图2(a),其中常数
表示当地人口,S表示易感者,E表示暴露者,I表示感染者,R表示移除者,该模型为传染病的研究提供了基础模型。
本文将疫情期间上海的总人口划分为七个仓室:易感者(S)、隔离者(E)、有症状感染者(I)、无症状感染者(A)、住院者(H)、治愈者(R)和死亡者(D),其中常数
。构建的模型各仓室之间的动态转化过程见图2(b)。为了便于分析,在本文中不考虑人口迁移、自然出生率和死亡率。模型改进考虑的点如下:
1) 上海政府采取包括集中隔离和自我隔离在内的严格隔离措施,防止病毒在人与人之间传播。因此,在改进模型中考虑隔离状态E,且未受感染的人在规定的隔离期后重新转化为易感类别的情况。根据官方规定,λ设置为14;
2) 感染奥密克戎的患者症状较轻甚至无症状,无症状感染者同时具有感染性且不易发觉,因此,在改进的模型中将无症状感染者考虑在内,且无症状感染者在一定时间会以一定的概率转化为有症状感染者类别的情况;
3) 感染奥密克戎的患者症状较轻甚至无症状,无症状感染者同时具有感染性且不易发觉,因此,在改进的模型中将无症状感染者考虑在内,且无症状感染者在一定时间会以一定的概率转化为有症状感染者类别的情况;
4) 根据Batistela [13] 可知,新冠肺炎感染者在治愈后不具有终身免疫,经过一定时间治愈者重新转化为易感类,在本文中,假设只具有180天的暂时免疫,则免疫丧失率
。
COVID-19的动态传播过程可由常微分方程组(12)描述:
(11)
构建的SEIAHRD模型的参数主要见表1。

Table 1. Meaning of parameters in SEIAHRD model
表1. SEIAHRD模型中参数的含义
2.3. 评价方法
均方误差(MSE)常用于预测问题的评价。本文将目标函数即适应度值设为E,I,H,A,R,D的实际数据与预测数据的MSE之和。MSE的计算公式如下,其中
和
分别表示某一阶段某一类第i天的实际数据和预测数据,T表示某一阶段的总天数。
(12)
采用决定系数R2判断预测值与实际值的拟合程度,以此检验所建立的模型的效用性,计算公式如下,其中
为某一类实际数据的均值:
(13)
基本再生数R0指一个感染者在患病期内平均可传染的人数,是衡量疫情是否得到控制的关键指标,其计算公式如下:
(14)
3. 数值模拟与分析
3.1. 数据来源
数据来源于上海卫生健康委员会,收集了上海2022年3月至6月的数据,包括隔离病例、确诊病例、确诊无症状病例、治愈、死亡以及解除无症状观察病例。
图3呈现了上海新冠肺炎疫情防控各阶段发生的重大事件,根据疫情防控措施的不同,将疫情过程分为四个阶段。根据奥密克戎病毒的特性并结合已有数据,可观察到在爆发早期和快速传播期时,感染症状较轻且无人员死亡,因此在这两个阶段不讨论死亡仓室。
3.2. 模型仿真及有效性验证
设置每个类别的初始值以执行改进后的SEIR模型。N设为24,804,300,这是上海市的本地人口,根据实际收集到的数据设置初始值,各阶段的初始值见表2。Hualei Xin [14] 等人认为奥密克戎病毒的平均潜伏期为3.8天,因此在本文中设
。

Figure 3. Prevention and control measures during the epidemic in Shanghai
图3. 上海疫情期间防控措施
Table 2. The initial value of each cell in each stage of the model
表2. 模型各仓室在各阶段的初始值
粒子群算法的初始设置为:种群大小
,维数
,学习因子
,最大速度
,最大迭代
,搜索空间
。
分别使用PSO和ACPSO算法寻找改进的SEIR模型中的参数,各阶段的适应度值见图4。
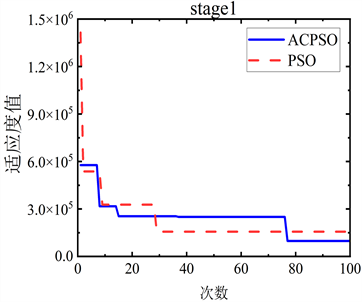

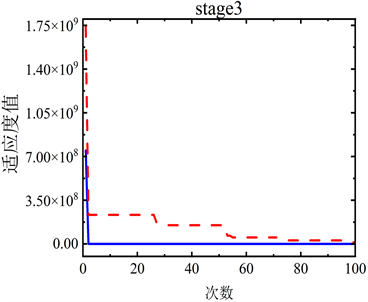
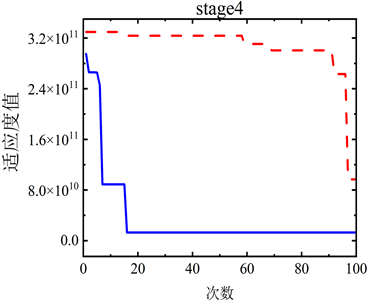
Figure 4. Comparison of fitness values at each stage
图4. 各阶段适应度值对比
图4中可以看出,相较于基本粒子群算法,自适应混沌搜索粒子群算法收敛速度更快,并且收敛后的适应度值更接近于最优点,而基本粒子群算法会陷入局部最优。分别采用PSO算法与ACPSO算法在各阶段确诊、治愈和死亡状态的实际病例值与模拟值的决定系数见表3。
Table 3. Determinants of simulated and actual confirmed, cured and dead cases at each stage
表3. 各阶段确诊、治愈和死亡病例模拟值和实际值的决定系数
由表3可知,ACPSO算法所得结果中所有病例的决定系数均在0.94左右,PSO算法所得结果总体在0.7左右,比较可得,自适应混沌粒子群算法优化参数拟合效果更好。表明本文运用的自适应混沌优化SEIR传染病模型是有效的。因此在本文中,采用ACPSO算法计算构建的SEIAHRD模型参数,所得各阶段参数结果见表4。
表4中可以观察到,
和
(社会接触传播率)大幅度降低,
(治愈率)增大,这可以从每个阶段提出的防控措施中得到解释。在第一阶段,上海政府发布“切块式、网格化”筛查方式,有助于减少健康人员与感染者接触的可能性,第二阶段,建立方舱医院和其他地区的医疗支持下,感染者的诊断和住院时间明显缩短。在疫情时期,人们有义务提高自我保护能力,如尽量减少外出,出行时戴口罩,保持双手清洁等,这将大大有助于遏制病毒的人际传播。第三阶段是最关键的阶段,专家预测疫情即将达到顶峰。此后,疫情防控战略实施逐步常态化,有序复工复产。
Table 4. Parameter values of each stage of the model
表4. 模型各阶段参数值
基于实际数据,再根据所得参数进行仿真,求解各阶段确诊有症状病例、无症状病例、治愈病例和死亡病例人数,结果分别见图5~8。

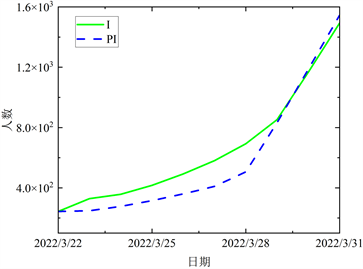
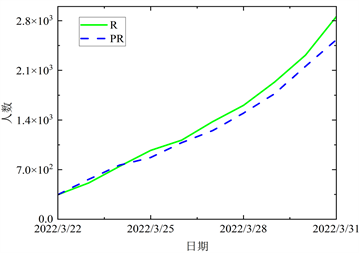
Figure 5. The comparison between the fitted data and the actual data in the first stage
图5. 第一阶段拟合数据与实际数据的对比
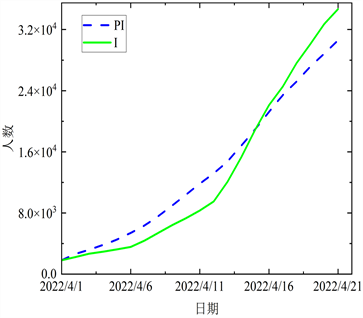
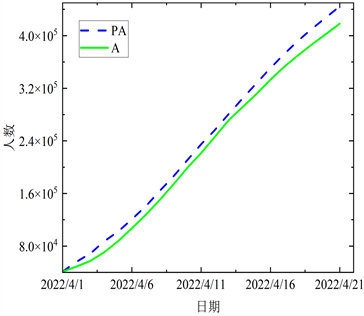
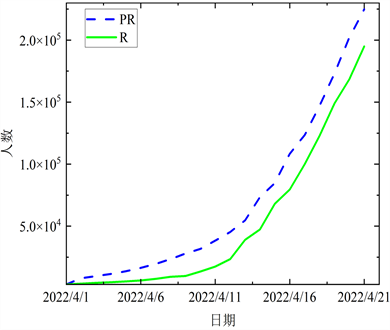
Figure 6. The comparison between the fitted data and the actual data in the second stage
图6. 第二阶段拟合数据与实际数据的对比

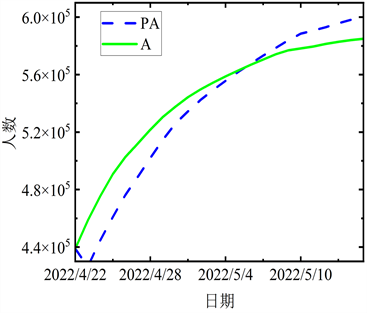
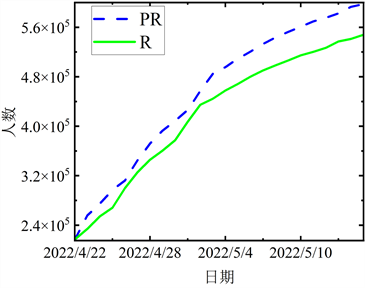
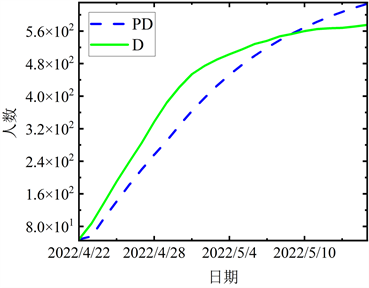
Figure 7. The comparison between the fitting data and the actual data in the third stage
图7. 第三阶段拟合数据与实际数据的对比
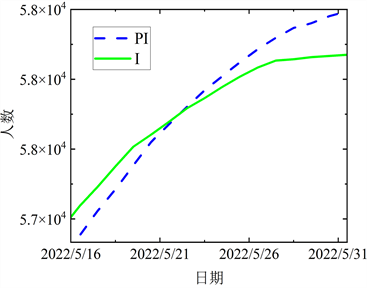

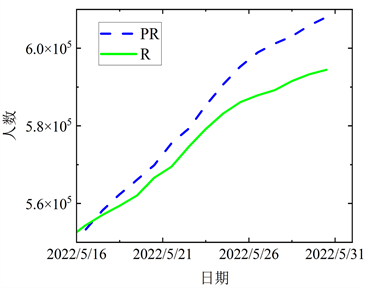

Figure 8. The comparison between the fitting data and the actual data in the forth stage
图8. 第四阶段拟合数据与实际数据的对比
结合图5~8各阶段模拟值与实际值对比图,曲线的变化态势基本一致,且近乎在一条线上,表明上海在四个阶段的预测结果与实际数据有较强的相关性。进一步验证本文所提出的ACPSO-SEIR模型是有效的。
3.2. 参数敏感性分析
根据基本再生数公式(15),影响感染人数的指标基本再生数R0主要受患者送医时间
、社会接触传播率
、
的影响。假设其他参数维持在第一阶段保持不变时,对
、
和
分析,所得结果见图9。
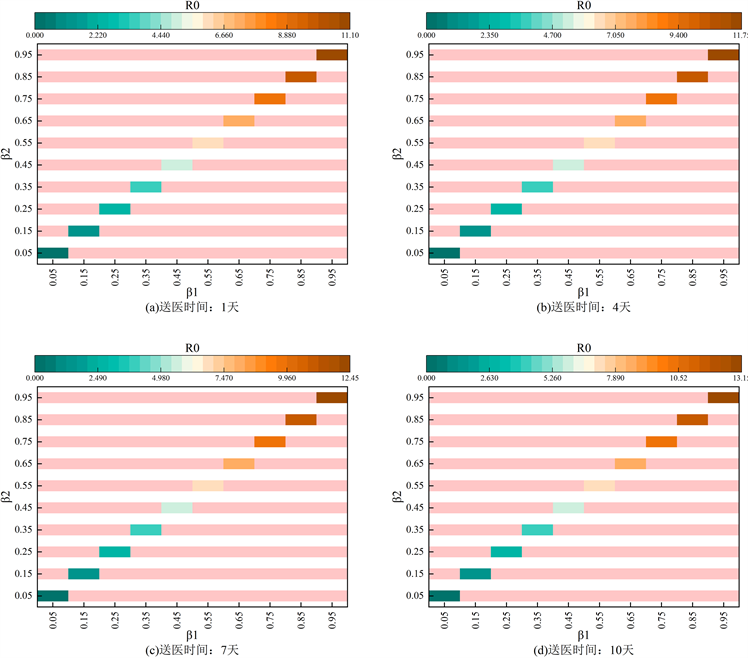
Figure 9. Parameter sensitivity analysis
图9. 参数敏感性分析
由图可知,社会传播接触率
、
为影响患者的首要因素,患者就医时间次之,并且社会传播接触率越小,随着社会传播接触率下降,R0值下降得越明显。结合图9(a)~(d),当
和
保持在0.2时,随着就医时间越长,R0值变大。从图9(a)可以看出,当
和
从0.2变化至0.8,R0值从2.45大幅度上升至10左右,表明随着
和
的值不断变大时,R0值大幅度上升,传染病在人群中的传播强度更强。
由于奥密克戎变异毒株具有症状较轻甚至无症状,并且传染性更强的特性,医护人员以及医院运行超出负荷,该情况在网格化筛查以及建立方舱医院等措施下得到缓解。为了研究各重要事件对疫情控制的影响,假设SEIR模型中的各参数分别维持在第一阶段,第二阶段,第三阶段,通过仿真,再与实际数据进行对比,反映在不同阶段防控措施对疫情控制的效用性。各阶段防疫措施对上海确诊患者、治愈病例数以及死亡病例的影响见图10,其中情形一、二、三分别表示各参数维持在第一阶段、第二阶段和第三阶段。
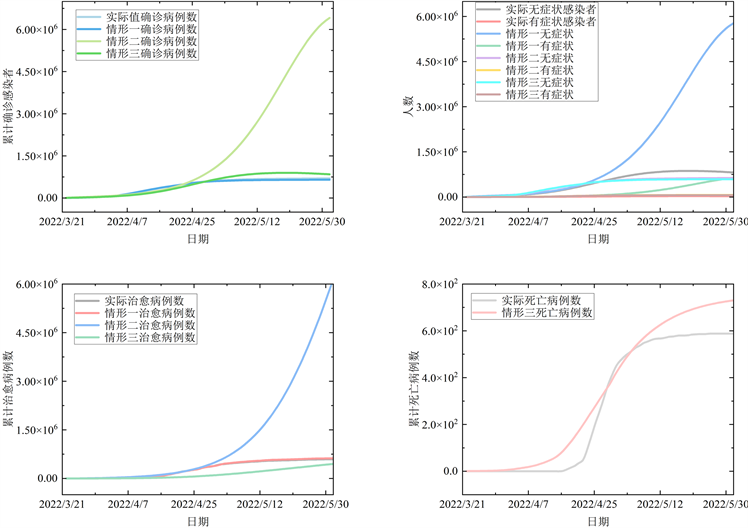
Figure 10. Impact of various stages of epidemic prevention measures on the number of confirmed patients, cured cases and deaths in Shanghai
图10. 各阶段防疫措施对上海确诊患者、治愈病例数以及死亡病例的影响
结合图10可以发现,情形一下,上海市在探索采用“重点区域 + 非重点区域”,“切块式、网格化”推进方式,及时将风险源管理起来,感染总人数得到了稳定控制,并且在初期感染者数量是较小的,医院也有足够的空间收治患者,由此确诊患者数平缓上升。情形二中,在前期感染者人数与实际情况是接近的,之后持续攀升远胜于实际的确诊人数,建立方舱医院以及各地医护工作人员的支援下,加大了核酸筛查力度,扩大了医院的收治能力,确诊了大量无症状患者,治愈病例数直线攀升。情形三下,开展有序复工复市措施,人口出现一定范围的流动,初期感染患者的人数是略超过实际值的。
4. 结论
基于奥密克戎病毒的传播特征,建立SEIR传染病模型,为了对模型的关键参数进行优化,引入粒子群优化算法,针对PSO算法易早熟收敛至最优,后期迭代收敛速度慢的问题,本文提出ACPSO-SEIR模型,以我国上海2022年3月至6月的疫情数据进行模拟,得到如下结果:
1) 通过决定系数评价模型,从结果表明,利用ACPSO算法优化参数,能有效地提高建模精度,尤其是对疫情各阶段不同状态下的预测精确度;
2) 社会传播接触率为影响患者的首要因素,患者就医时间次之,当社会接触率保持在0.8时,随着就医时间时间变长,基本再生数上升,当就医时间为1天时,社会接触率从0.2上升到0.8时,基本再生数从2.45上升到9.83,传播规模扩大。
3) 建立方舱医院,采用“重点区域 + 非重点区域”、“切块式、网格化”推进筛查方式对疫情变化产生重大影响,其中建立方舱医院将患者的治愈数提升了近1倍。
基金项目
国家自然科学基金项目(61672298);中国博士后科学基金面上项目(2019M651917)。
参考文献
NOTES
*通讯作者。