1. 引言
近年来,机器视觉技术的快速发展,使得基于三维激光扫描技术的三维重建技术在场景重构、逆向工程、地形勘探等领域都具有重要应用 [1] [2] [3] 。三维激光扫描仪在进行扫描时,往往因为角度、遮挡等一系列问题,获取的点云数据容易产生局部缺失。在实际应用中,为了获取完整的点云,通常需要对目标进行多视角扫描。由于扫描仪在扫描时所采用的是以自身为基准的独立坐标系,因此需要将不同空间基准下的点云统一到一个基准坐标系下,进而产生了配准的概念 [4] [5] 。
配准的过程分为粗配准和精配准 [6] [7] 。粗配准的目的是通过刚体变换,使得源点云与目标点云在空间上大致重合,从而为精配准提供良好的起始位置。基于不同理论思想,粗配准可分为随机采样一致性(Random Sample Consensus, RANSAC)和特征点匹配两种方式。RANSAC最早是由Fischler和Bolles在SRI上,为解决LDP (Location Determination Problem)问题所提出的一种的算法 [8] 。王鹏等人针对稀疏建图中关键帧间的点云配准问题,提出一种基于改进RANSAC的场景分类点云粗配准算法 [9] 。Aiger等人提出了一种基于4点共面仿射不变原理的4PCS算法,该算法基于RANSAC的思想,能有效地对全局点云进行匹配 [10] 。基于RANSAC思想配准的原理是通过不断从源点云和目标点云中进行等量采样,并计算刚体变换矩阵,直至模型满足精度要求。但这种基于重复采样的方法,在面对大体量点云时,具有较高的时间成本。而特征点匹配法无需重复采样,只需在源点云中进行单次采样,并基于特定单点特征,在目标点云中寻找对应点。刘雷等提出了基于三维尺度不变特征变换(3DSIFT)关键点检测方法,结合二进制方向直方图描述子(BSHOT)构建点云匹配对的粗配准方法 [11] 。Rusu等人采用均匀采样与快速点特征直方图(Fast Point Feature Histogram, FPFH)检测和描述三维点云中的关键点,高效地建立了源点云和目标点云间匹配关系 [12] 。
精配准的目标是基于粗配准的基础,进一步降低匹配点的空间差异。精配准算法以Besl等人在1992年提出的最近点迭代(Iterative Closest Point, ICP)最为著名,但其最大的问题就是在待配准双方具有较大的空间异质性时,算法容易陷入局部最优 [13] 。近十几年众多学者为了改善ICP算法的效率和精度,进行了大量的工作。李庆玲等人提出一种基于NDT-ICP的配准算法,能有效降低配准的绝对位姿误差,但时间复杂度较高 [14] 。Wu等人提出一种基于FPFH-ICP的三维场景重建方法,在实际应用中具有快速、精准等优点,但仍存在高度依赖于基于经验的人工调参的问题 [3] 。
为了解决FPFH-ICP算法中经验参数较多,获取最佳配准参数较难的问题,本文提出一种基于粒子群优化(Particle Swarm Optimization, PSO)改进的FPFH-ICP算法:PSO-FPFH-ICP。以最小化配准后的均方根误差(Root Mean Square Error, RMSE)为目标,为每个参数设立限制区间,通过粒子群优化不断对配准参数进行调节择优,最终获取区间内最佳的参数,从而提升算法的自动化程度和精确度。
2. FPFH-ICP点云配准
2.1. FPFH粗配准
快速点特征直方图(Fast Point Feature Histogram, FPFH)是点特征直方图(Point Feature Histogram, PFH)的一种快速简化算法 [15] 。
由于PFH采用特征较多,当点云点量达到n时,算法复杂度可达O(nk2)。针对这一问题,FPFH简化了特征提取,将其分成了两步:首先放弃了欧式距离d,提取单点Pq和其k近邻对应的特征三元组<α、θ、Φ>,并进行统计得到简化点特征直方图(Simplified Point Feature Histogram, SPFH)。接下来,分别计算各近邻点的k邻域,如图1(2)所示。采用相邻点的加权SPFH与Pq的SPFH进行融合处理,如式(1),得到FPFH。FPFH相较于PFH,其所具有的超半径球形捕获域,可以更全面地融合局部特征信息;同时简化后的特征提取方式,也降低了算法的复杂程度,利于实时应用。
(1)

Figure 1. (1) The neighborhood structure of PFH; (2) Neighborhood structure of FPFH
图1. (1) PFH的邻域结构;(2) FPFH的邻域结构
在点云配准中,首先分别计算两组点云的单点FPFH。由于FPFH与点云的局域法线特征联系紧密,因此在法线变化较大的点云中,不同区域的FPFH有显著差异,如图2(1);而法线变化较小的点云中,不同区域的FPFH非常相像,如图2(2)。接下来,在源点云中选取n个采样点,为保证FPFH的特征差异性,n个采样点间的欧式距离需要大于某一阈值
。基于FPFH的相似度,在目标点云中寻找对应点,构造源采样点集
和目标采样点集
,计算二者之间的刚体变换矩阵R和T,其中R是旋转矩阵,T是平移矩阵。最后,基于R和T将源点云变化到目标点云上,从而完成源点云和目标点云的全局粗配准。
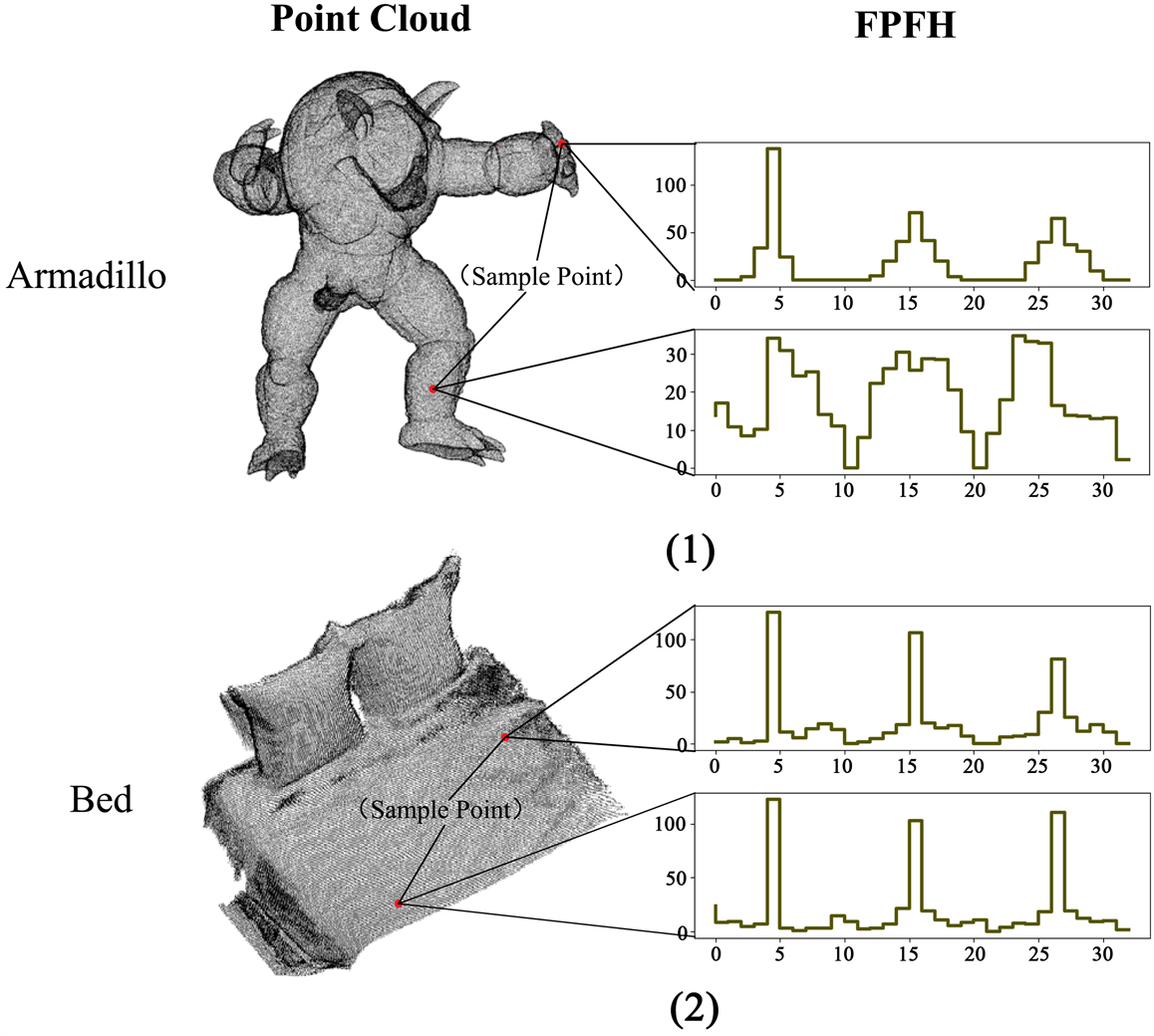
Figure 2. (1) The FPFH of Armadillo point cloud with large normal change is quite different in different local areas; (2) The difference of FPFH in different local areas of Bed point cloud with small normal change is small
图2. (1) 法线变化大的Armadillo点云不同局域FPFH差异较大;(2) 法线变化小的Bed点云不同局域FPFH差异较小
2.2. ICP精配准
当完成粗配准后,源点云和目标点云已大致契合,但局部仍存在角度和位置的误差,需要进行精配准来提高精度。迭代最近点(Iterative Closest Point, ICP)是一种常用的精配准算法,ICP通过对源采样点集source和目标采样点集target不断进行刚体变换,使source和target中对应点的欧式距离平均值最小化,从而完成源点云和目标点云的精配准。其本质上是基于最小二乘准则的配准算法。
ICP算法的具体流程如下所示:
1) 粗配准后,通过KD-Tree对source建立空间索引,基于距离阈值
确定target中最近对应点。
2) 分别计算source和target的质心
和
,并对source和target进行去质心,如式(2)~(3):
(2)
(3)
3) 令
,对H进行SVD分解得
,则此次迭代的最优旋转矩阵
,最优平移矩阵
。
4) 以式(4)为损失函数,不断进行source到target的变换,直到式(4)小于设定阈值或迭代次数达到设定值,完成点云的精配准。
(4)
3. 粒子群优化配准
上述方法在点云配准中虽可取得较好结果,但所需人工设置参数较多,例如降采样的体素大小Svoxel、法线估计的邻域半径Rnormals、FPFH邻域半径RFPFH、特征点采样的间隔阈值
以及ICP距离阈值
。并且参数的细微变动都会对配准精度产生影响。通过不断更改某一项参数进行配准,其余参数保持固定,得到动态参数变化下配准的RMSE的变化如图3所示。
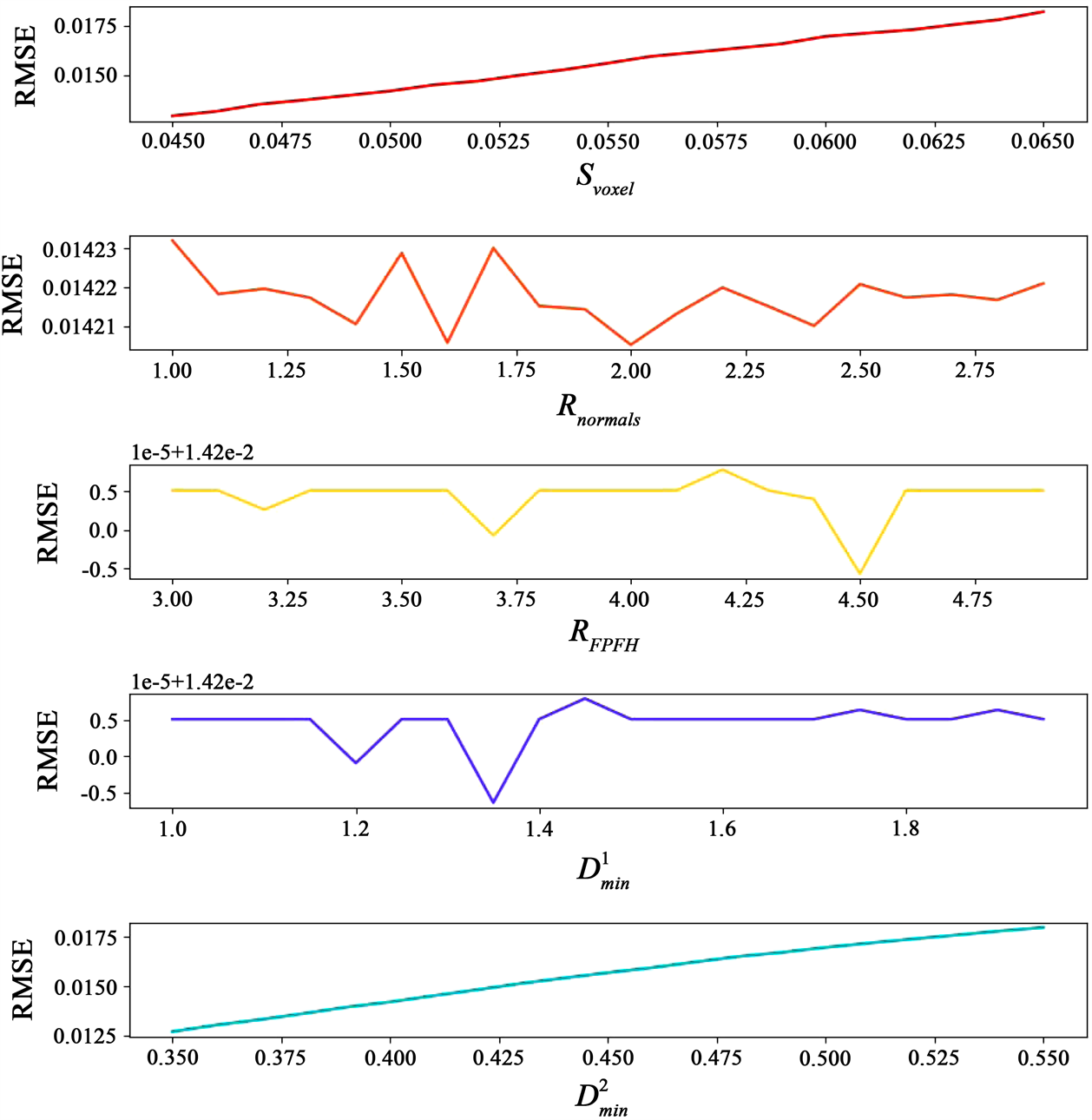
Figure 3. Root mean square error (RMSE) curve after registration under five parameters
图3. 五项参数下配准后的均方根误差(Root mean square error, RMSE)变化曲线
可以看出,除Svoxel和
对RMSE值域空间的影响保持线性递增,其余三个参数在阈值空间的影响都呈现波动性,并存在可检测的局部极值。因此,本文提出采用粒子群优化算法来进行自动化参数选优,最大化配准的精度。
3.1. 粒子群优化算法
粒子群优化算法是一种并行性进化算法,该算法思想源于飞鸟集群活动的规律性,属于利用群体智能建立的简化模型 [16] 。粒子群优化算法基于群体中信息共享机制,模拟群体的运动,使问题在求解空间中产生从无序到有序的演化,从而获得最优解。
算法采用一种无质量的粒子群来模拟飞鸟群,单粒子在N维空间中仅有两个矢量属性:分别是速度
和空间位置
。在算法的每次迭代中,粒子综合自身飞行经验数据pbest,即自知最佳位置,以及群体飞行经验数据gbest,即群知最佳位置,来决定具体偏移矢量。其中,第j个粒子在i维上的速度以及位置随迭代时刻t的变化如式(5)~(6)所示:
(5)
(6)
其中,c1和c2是个体和群体加速因子,c1越大,则粒子越倾向于其自身的最优位置;c2越大,则粒子越倾向于群体的最优位置。由于鸟群在飞行过程中具有空间位置随机性,随机数
对这一随机过程进行了模拟。w是惯性权重,用来决定粒子在飞行过程中的坚定程度。w越大,粒子对原路线的坚定程度就越高,越倾向于探索未知区域。
算法流程如图4所示。其中个体适应度就是目标函数在当前个体条件下的输出值。为了减少无用计算量,提升算法效率,需要通过限定边界的方式控制粒子群的活动范围,所以当粒子越界时需要进行越界处理。当算法满足收敛条件时,即输出最优值。

Figure 4. Particle swarm optimization algorithm process
图4. 粒子群算法流程
3.2. 优化配准
上述点云配准算法中,存在需要人工设定的参数项较多,且难以确定合适的参数使得算法配准结果最佳的较大问题。通过粒子群优化算法进行智能调优,在五维空间中展开粒子群移模拟,求取五个参数最佳值。结合粒子群优化后的配准算法具体流程如图5所示。
首先以Svoxel、Rnormals、RFPFH、
及
五个参数构造五维粒子群,并对粒子群进行初始化。接下来,以配准后源点云和目标点云间RMSE为适应度函数,对每个粒子进行适应度计算。结合粒子适应度,确定pbest和gbest,并更新粒子速度和位置,同时保证粒子速度
,位置
。当算法迭代次数达到上限,或是配准后RMSE小于某一设定值时,即视为算法收敛,停止迭代,输出最佳参数。
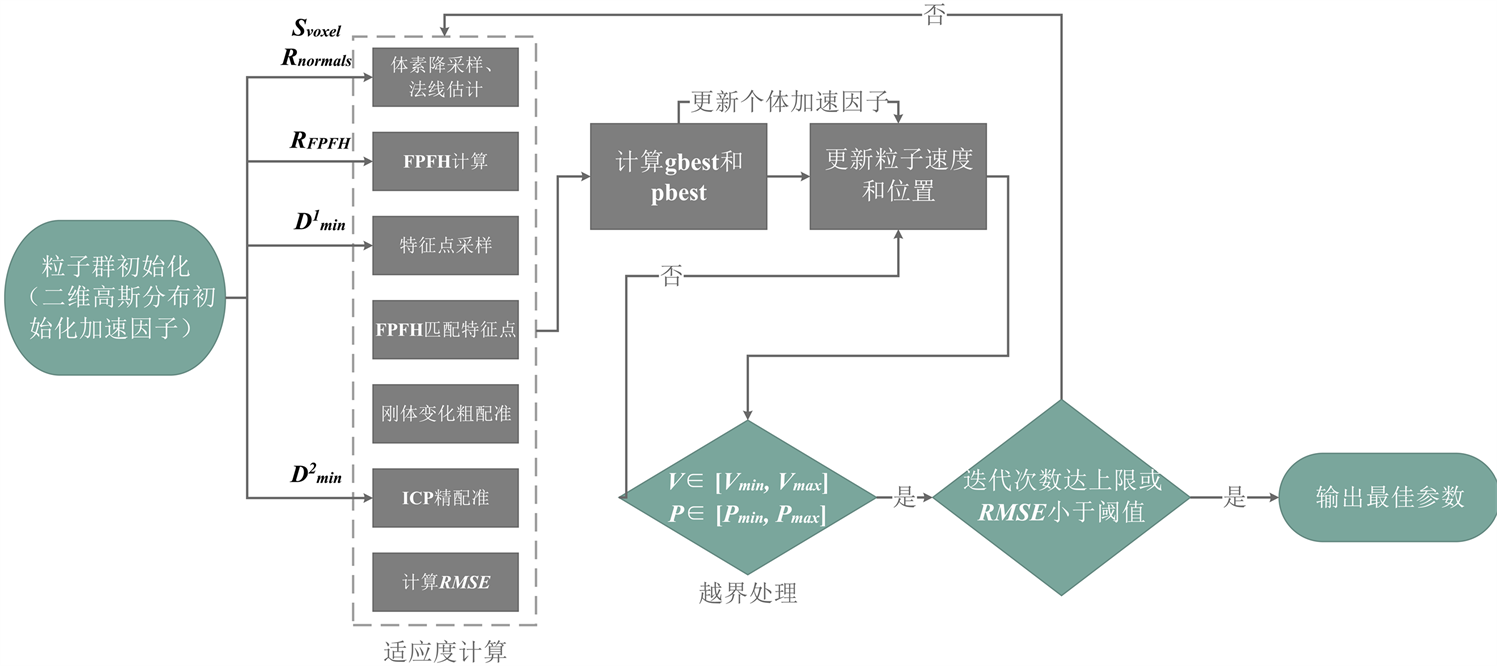
Figure 5. Particle swarm optimization point cloud registration process
图5. 粒子群优化点云配准流程
由于粒子群算法是基于飞鸟群的集群关系所设计,而固定的加速因子不能体现出不同个体间对个体或集体的亲密度差异,就像鸟群在飞行过程中总有顾及全局的领头鸟,也有偏离群体较远的个体。考虑到求解空间的维度较高,空间结构复杂,而基于固定加速因子ci进行粒子群移的搜索方式缺乏灵活应变能力,收敛速度较慢。为有效地利用个体经验信息,增强细节捕捉能力,本文设计了一种针对个体加速因子c1的动态调节算法:
① 基于二维高斯分布进行随机数生成,以此初始化每一个粒子加速因子(c1, c2)。高斯分布为不同粒子赋予不同的加速因子,能更好地模拟个体间的差异,同时兼顾群体和个体的经验信息,更好地展开搜索。
② 计算每个粒子的pbesti到gbest的欧式距离
,以此衡量不同个体与群体间的亲密程度。
③ 基于距离对第i个粒子的个体加速因子c1,i进行调节,如式(7)所示。亲密度越低的个体,其个体加速因子权重越低,逐渐向群体靠拢。
(7)
这种动态个体加速因子,相较于固定加速因子,能更好地模拟鸟群中群体亲密度不同个体的群移过程。粒子凭借与群体的远近程度调节个体加速因子,在远离群体时更加注重个体经验信息,而靠近群体时减少对个体信息的依赖,使整体更好地利用个体经验信息。
4. 实验结果与分析
本文采用的实验数据来自于普林斯顿大学的3DMatch数据集中的子数据集SUN3D,共四对不同的场景点云。每个点云都是表面3D点云,使用TSDF体积融合从50个深度帧集成,具有明显的空间角度和位置的差异。四组点云的点云数量和场景重叠度如表1所示。

Table 1. Experimental data information
表1. 实验数据信息
首先对实验点云进行了ICP配准,实验结果如图6所示。可以看出,由于源点云Source和目标点云Target在空间角度和位置的差异较大,导致ICP算法都陷入了局部最优。因此,对于本文实验数据,单纯的ICP配准不能满足要求,应该先进行粗配准后再采用ICP进行局部优化。

Figure 6. Experimental point cloud and ICP registration results
图6. 实验点云以及ICP配准结果
接下来,采用本文算法对实验点云进行处理,将迭代次数与配准后的RMSE绘制折线图,如图7所示。
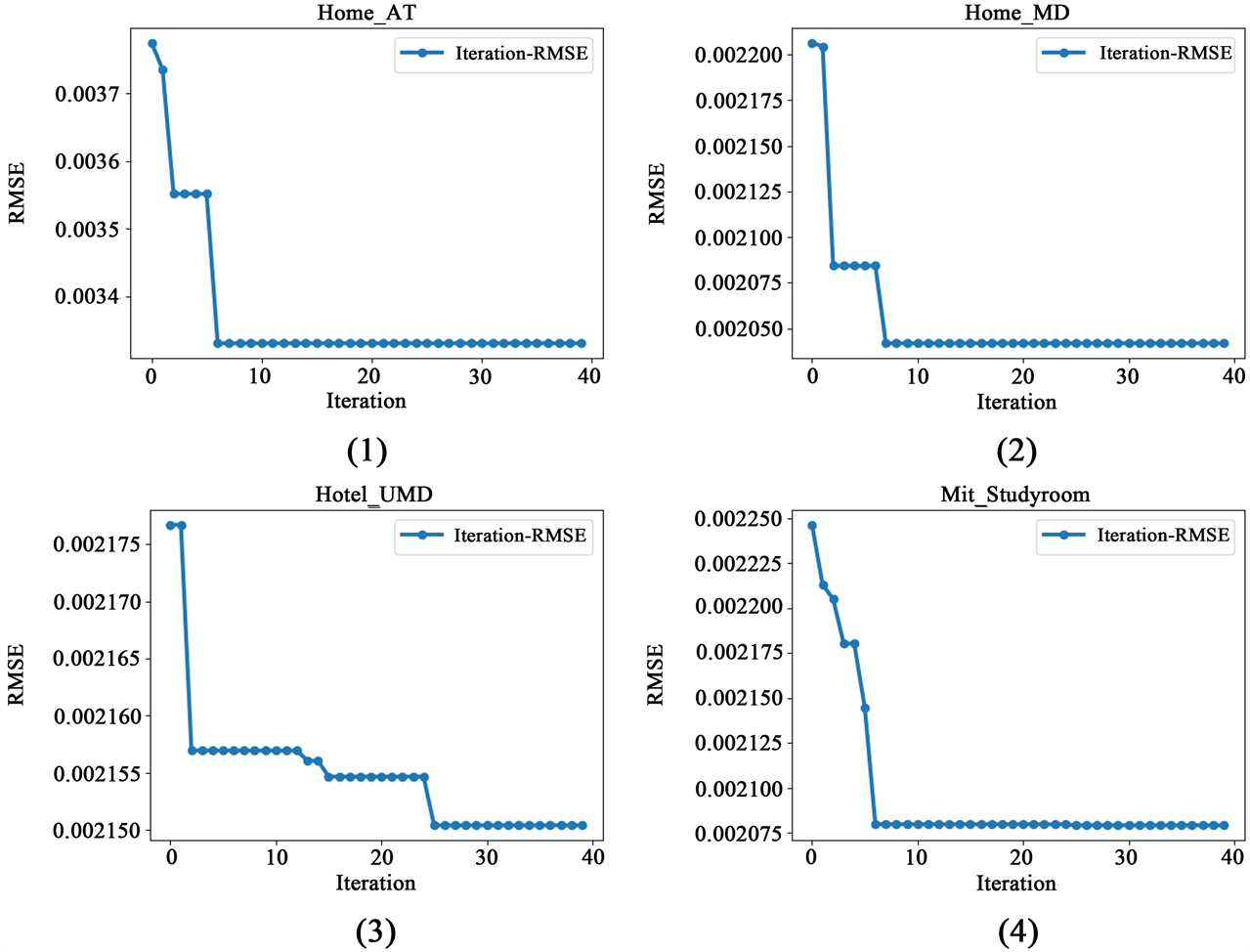
Figure 7. The relationship between the number of iterations and RMSE in the algorithm experiment of this paper
图7. 本文算法实验中迭代次数与RMSE的变化关系
从图中可以看出,粒子群算法在Home_AT、Home_MD以及Mit_Studyroom三个场景的配准中都具有极快的收敛速度,但在Hotel_UMD中,达到最优结果所用的迭代次数较多,RMSE的下降呈现阶梯状。分析产生如Hotel_UMD中收敛困难现象的原因,应该是Source难以在Target中正确匹配到特征点。从图6中可以看出,Hotel_UMD中Source和Target的重叠部分,基本上来自于一张床。Source中最具几何特征的床头柜,在Target中基本上不存在。而床和枕头的点云,多以平面为主,各点的法线特征高度相似。因此,基于FPFH在Target中为Source匹配的特征点,应该具有较大的误差,从而导致了粒子群优化中较慢的收敛速度。
本文实验还同时采用了FPFH-ICP、RANSAC-ICP和4PCS-ICP三种常用的点云配准算法对实验数据进行处理,配准的结果如图8所示,其中PSO-FPFH-ICP为本文算法。可以看出,四种方法在配准结果上,并不存在较显著的视觉差异。为了更好地进行四种算法在配准精度上的比较,我们进行了六次重复实验。通过随机数生成器,在与粒子群相同边界的参数空间中,随机进行了六次参数的选取,用来模拟人工调参的过程,并与本文算法进行比较。为便于进行直观比较,将各算法六次重复实验的结果绘制成如图9所示的折线图,并将所得均值展现在表2中。
从表2得出,本文算法在四个场景中,相较于FPFH-ICP平均RMSE降低了9.010 mm,相较于RANSAC-ICP降低了8.606 mm,相较于4PCS-ICP降低了7.322 mm,效果非常显著。而从图9可以看出,三种对照算法在每个场景,基于随机数模拟人工调参的配准过程中,精度变化较为剧烈,而本文算法则表现得非常稳健。同时还能看出,三种对照算法的精度与本文算法在多数情况下较大,但也有少数几次比较接近甚至达到本文算法精度。如Home_AT中的第六次重复实验,4PCS-ICP配准后的精度基本与本文算法相等。由此可以得出结论,基于人工调参的方法不定性太强,在参数较多时,很难通过人工调参的方法达到配准最优精度。而本文所提出的,基于粒子群算法搜索参数空间,以此获取最优参数的方法,不仅可以轻易突破人工调参在精度上的瓶颈,还具有较强的稳健性。

Figure 8. Results of four registration methods
图8. 四种配准方法结果
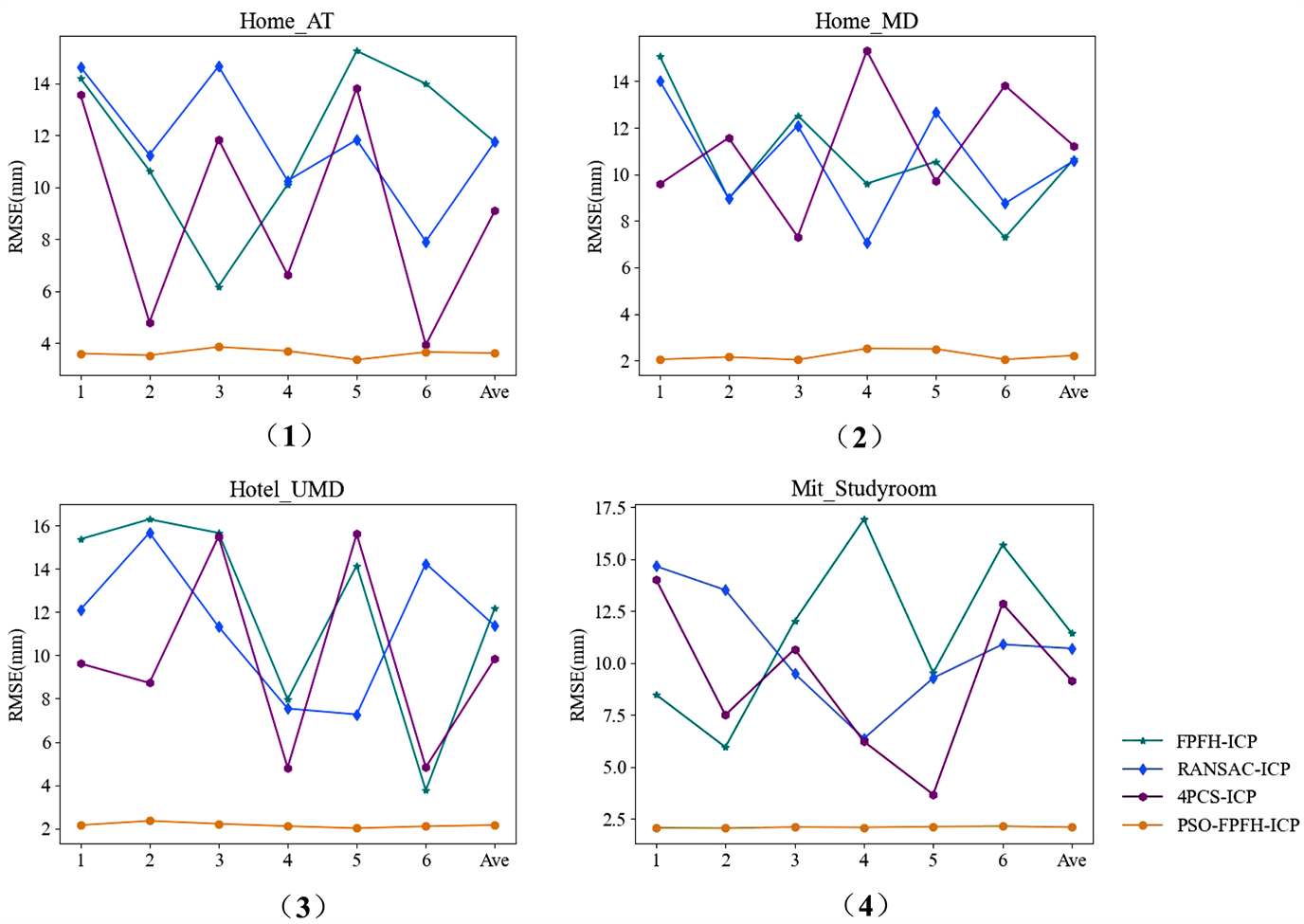
Figure 9. Results of six repeated experiments
图9. 六次重复实验结果
Table 2. The average value of six repeated experiments of each algorithm
表2. 各算法六次重复实验均值
5. 总结
本文在FPFH-ICP配准算法的基础上,针对算法参数难以调优的问题,添加了粒子群优化进行自动化参数调节,并以SUN3D数据集的四个不同场景的点云进行实验。本文算法与FPFH-ICP、RANSAC-ICP和4PCS-ICP三种常用的配准算法,在六次重复实验中都取得了优秀的配准精度。相较于FPFH-ICP平均RMSE降低了9.010 mm,相较于RANSAC-ICP降低了8.606 mm,相较于4PCS-ICP降低了7.322 mm。在提升了精度的同时,也避免了复杂的参数调节,具有较高的稳健性和自动化程度。由此可证明本文算法的便利性和有效性。随着激光扫描技术的进步,单次扫描获取的点云体量将进一步提升,同时由于环境的复杂性,点云体量增加的同时噪声也会不可避免地增加。同时伴随着扫描设备的多元化,多源配准也是一项研究热点。未来点云配准技术的发展要求必定更加趋向于强鲁棒性、实时性、低重叠率以及多源性等。本文基于粒子群优化有效解决了配准自动化参数调节的问题,后续将进一步研究如何利用当下较热门的深度学习技术进行更加深层次的点特征提取,以鲁棒性增强和低重叠率配准问题为主要研究方向继续努力。