1. 引言
二十世纪八十年代以来,徐淮、兖州等地不同矿区的井壁破裂、水喷砂、安全问题多种多样,给提升运输带来困难,导致矿山停产。据统计,仅在兖州和徐淮矿区发生的煤矿竖井断破裂造成的损失就不计其数。因此,准确预测和判别井筒破裂的地质灾害的发生,对矿井的安全运营和经济效益具有重要意义 [1] 。目前,大多数学者认为井筒周围的低部含水层会因失水而下沉,并产生对井筒的负阻力(附加力),从而导致井筒断裂。通过进一步的煤矿竖井破裂室内模拟试验的分析和推测,井筒破裂主要由井筒周围深厚土体、水体和井筒的相互作用导致的 [2] [3] [4] 。
判别和预测井筒破裂的方法主要有两种 [5] :一是通过观测地表沉降、井筒变形、应力和地下水来研究煤矿竖井变形规律,对煤矿竖井破裂预测判别;其次,通过开发新的智能分析方法、智能技术、煤矿开采观测方法的多信息综合分析来对煤矿竖井安全状态进行预测,这些方法能更好地预测一些不确定性问题,特别是在工程地质灾害预测领域,如应用神经网络、灰色理论或深度学习分析方法来预测工程的可靠性。但这些方法大多没有考虑到井筒不稳定性指标数据重叠造成误判率高的问题,最终导致决策失误,造成安全隐患和经济损失。黎锦贤等 [6] 采用主成分分析法,建立了煤矿安全评价的综合数学函数评价模型,实现了煤矿安全程度定量化目标评价。金洪伟等 [7] 为解决煤矿瓦斯涌出量指标繁杂致使预测精度低的问题,运用主成分分析法对瓦斯涌出量进行降维预测,取得了较好的预测效果。丁坤等 [8] 采用主成分分析对原始多维变量进行预处理,并利用距离来表征光伏系统的健康状态,研究结果表明该方法能够更加灵敏、准确地反映光伏系统的性能状态。
综上,本文借鉴主成分分析理论解析煤矿多特征因素,把煤矿安全状态评价过程中多个彼此相关、数据重叠的指标变量进行重组,组合成互不相关的综合指标代替初始指标,从中优选较少的综合指标来反映初始指标的信息,克服煤矿安全状态评价中信息重叠和指标繁杂导致预测不准的问题,有效的描述不同煤矿竖井现有特征 [9] 。主成分分析本质是通过数学降维来简化多元数据结构,然后结合距离判别方法将处理过的样本数据作为判别因子,得到相应的判别函数进行预测,以此建立一套基于主成分分析和距离判别法的井筒安全状态判别模型,对煤矿竖井安全状态进行判别。
2. 主成分分析法与距离判别法的概念
2.1. 主成分分析法概念与基本原理
在多元指标处理过程中经常遇到高维知识集,由于信息具有较高的空间性和大量的变量,这些变量之间通常存在一些相关性,因此这些样本知识很难复制整体的大部分信息,太多的变量会对计算量产生影响,增加分析的复杂性。主成分分析法作为一种空间约简和提取技术,将知识引入低维区域,尽可能减少信息损失,初始指标的线性组合被用来表示主成分分,减少了信息的维度,简化了信息结构,指标的重要性完全取决于线性组合中原指数系数绝对值的大小 [10] 。
假设煤矿竖井安全状态涉及P个评价指标,分别用
来表示,这P个指标构成P维随机向量,
,转换矩阵为A,对随机变量X进行线性变换,形成新的综合变量,用Y表示。新的综合变量可以由原始变量线性表示
,即 [11] :
(1)
式中,满足
;Yi与Yj之间互不相关(
;
);Y1是
的一切线性组合中方差最大的;
的方差之和等于
方差之和。主成分的求解过程也就是求转换矩阵A的过程。求解主成分的一般步骤如下:
(1) 由于选取的影响竖井井筒破裂的特征因素具有不同的量纲,为了消除多元信息的量纲差异,需要对样本数据进行归一化处理,归一化后,数据被转化为无量纲的纯量,便于不同单位和不同量级的指标解析和比较。考虑到样本数据的离散性和数据处理的方便性,本文采用离差标准化方法对数据进行归一化处理。离差标准化方法的表达式为:
(2)
式中,k为样本数据的序号数,vk是样本数据的归一函数值。
(2) 计算P个变量之间的协方差矩阵Σ,得到特征向量
,单位向量为
。其中,令转换矩阵
,即A的第i行就是Σ的第i个特征根对应的单位特征向量Ti,且第i个主成分Yi的方差就等于Σ的第i个特征根λi [11] 。
(3) 第k个主成分Yk的方差贡献率为
。若取m (m < p)个主成分,主成分
的累积贡献率为
[12] 。
(4) 主成分个数取决于累积方差贡献率,通常取m个主成分使得其方差的累积贡献率达到80%以上,则对应的前m个主成分的样本信息量包含p个原始变量所能提供的绝大部分信息 [13] 。
2.2. 距离判别法概念与基本原理
距离判别法是先计算样本数据到各个分类的距离,根据距离的大小建立相应的判别规则,得出判别函数,进而对未知样本进行分类 [14] 。
设有k个m维总体:
,从中任意取2个总体Gp,Gq相同,新样本X到总体Gp和Gq的马氏距离平方差为 [14] :
(3)
式中:
(4)
由此有:
(5)
一般情况下,总体的均值向量
和公共协方差矩阵Σ是未知的,可以用各总体的学习样本作估计。
假设
,为来自总体Gq的学习样本,其中nq为总体
Gq的学习样本个数,则uq的无偏估计为 [14] :
(6)
则学习样本的协方差矩阵Σq的无偏估计为组内协方差矩阵Sq:
(7)
当各总体的协方差矩阵相等时,总体协方差矩阵Σ的无偏估计为Wq(X)。
(8)
以
和S分别代替uq和Σ,得到
的估计为:
(9)
因此,多总体情况下的距离判别准则为,若总体Gq满足式(10):
(10)
则判别
。
3. 煤矿竖井井筒安全状态判别模型及应用
根据兖州矿区立井井筒破裂的实际资料 [15] ,提取表土层厚度、底含厚度、底含水位速降、井筒外径、井壁厚度和井筒投入使用时间6个特征因素,如下表1所示。采用其中16组数据作为主成分分析和距离判别法的样本集,剩余4组作为井筒安全状态判别模型精度可靠性的检验样本。

Table 1. System resulting data of standard experiment [15]
表1. 各矿井特征因素集 [15]
3.1. 主成分分析
为了后续模型建立方便性,将影响井筒破裂的表土层厚度、底含厚度、底含水位速降、井筒外径、井壁厚度和井筒投入使用时间6个特征因素分别用V1、V2、V3、V4、V5、V6表示。对选取的6个评价指标进行归一化处理(式2),得到对应的归一化后的变量v1、v2、v3、v4、v5、v6,其数值为表2所示。
Table 2. Normalized shaft sample data
表2. 归一化处理后的井筒样本数据
Table 3. Correlation coefficient matrix of each feature factor
表3. 各特征因素相关系数矩阵
Table 4. Characteristic values, variance contribution and cumulative contribution
表4. 各成分特征值、方差贡献率及累积贡献率
Table 5. Principal component coefficient matrix
表5. 主成分系数矩阵
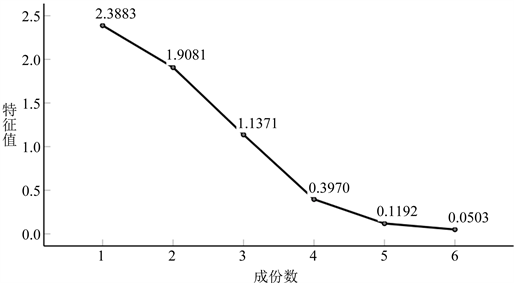
Figure 1. Principal component analysis gravel map
图1. 主成分分析碎石图
由表3各特征因素之间的相关系数矩阵可以看出,输入的几个特征因素彼此之间具有明确的相关性,如:v3和v6相关系数达0.908、v4和v5相关系数达0.774、v4和v1相关系数达0.767等,这必然会对井筒安全状态判别的精度造成影响,容易导致井筒安全状态的误判。因此,有必要对样本数据进行主成分分析。通过编写R语言程序,对表2中归一化处理的样本数据进行主成分分析,得到各成分特征值、方差贡献率及累积贡献率如表4所示,把输出结果的每个元素除以特征值的平方根
,得到主成分分析的系数矩阵如表5所示。
主成分的提取顺序是根据特征值大小从大往小依次选取的,特征向量也根据相应的特征值大小顺序依次选取,特征值越大,相对应的主成分因素越重要。主成分数据的选取一般要求大于80%,即累积贡献率不小于80%的原则。由表4可知,前3个主成分特征值
、
和
的累积贡献率为90.558%,即包含了原始数据的90.558%的信息,可以概括原始变量的主要信息,同时与图1中的主成分分析碎石图相吻合。由表5可知,Y1包含原始变量v1、v4、v5的信息较多,它反映了原始变量39.805%的信息;Y2主要是对原始变量v3、v6表征,它反映了原始变量31.801%的信息;Y3主要包含原始变量v2的信息,它反应了原始变量18.952%的信息,这与图1中主成分分析碎石图相吻合。依据表5中各主成分系数矩阵,可得到Y1、Y2、Y3与原始变量v1、v2、v3、v4、v5、v6之间的函数表达式为:
(11)
(12)
(13)
因此,根据式11、式12和式13计算得到处理后新的样本数据,如下表6所示。
Table 6. Data obtained after the principal component analysis
表6. 主成分分析后的数据
3.2. 距离判别模型的构建与检验
对表1中前16组样本数据进行训练,后4组样本作为验证。以破裂和完整作为2个不同的总体,并假设2个总体的协方差矩阵相等。将上述通过主成分分析方法得到的三个主成分指标Y1、Y2、Y3作为距离判别模型的判别因子,按照上文提出的距离判别分析计算理论进行计算、建模,程序中将井筒破裂和完整状态分别用数字“1”和数字“0”表征。然后,对训练样本进行计算、学习后可求得相应的判别系数,如表7所示,进而得到煤矿竖井井筒的安全状态判别函数:
(14)
Table 7. Distance discriminant function coefficient
表7. 距离判别函数系数
经过学习后的模型,利用留一交叉验证法对学习样本进行判别,判别结果全部正确,并对100.0%个进行了交叉验证的已分组数据进行了分类,正确率达到了100%,如下表8所示。
Table 8. Training results of the distance discrimination method
表8. 距离判别法训练结果
采用上面已经完成学习的距离判别分析模型,对剩余4个验证样本进行判别,判别结果与实际情况全部相符,判别正确率达100%,如下表9所示。
Table 9. Verify the sample discrimination results
表9. 验证样本判别结果
综上,基于主成分分析及距离判别法的煤矿安全状态判别模型的交叉验证结果和测试样本的判别结果均与实际情况完全相符。由此认为,本文提出的判别模型对于煤矿竖井井筒的安全状态预测预报是完全可行且有效的。
4. 结论
(1) 本文从煤矿竖井井筒非采动破裂特点以及灾害的成因出发,提取了影响煤矿竖井井筒非采动破裂的几种特征因素,采用主成分分析方法解析煤矿竖井破裂的多特征因素,通过降维处理克服预测指标繁杂和信息重叠的影响,遴选出反映煤矿竖井破裂的主要判别因子,提高预测的精度。
(2) 依据距离判别分析基本原理,对上述通过主成分分析方法得到的判别因子进行计建模、计算,建立了反映煤矿竖井井筒的安全状态判别函数。
利用留一交叉验证法对建立的安全状态判别函数进行训练验证,前16组训练样本数据判别结果全部正确,并对剩余的4组检验样本进行判别验证,判别结果与各煤矿竖井实际安全状态吻合,说明本文建立的煤矿竖井安全状态判别模型预测效果较佳。