1. 引言
命名实体识别(Named Entity Recognition, NER)是自然语言处理(Natural Language Processing, NLP)中的一项基础任务,主要目的是从非结构化文本中识别出固有实体。NER是文本分类、情感分析、自动摘要和机器翻译等功能实现的基础,随着计算机技术的发展和大数据时代的来临,越来越多的研究者投入到从海量的文本信息中提取有用的实体知识,并挖掘出实体之间存在的潜在价值的问题中来。
针对命名实体识别中由于中英文数字混合导致的文本特征学习不彻底、实体识别边界模糊、对不断涌现新的实体识别不准确等问题,本文提出了一种预处理方法,该方法将中、英文和数字混合通过一种“字典”进行编码,将待识别的文本通过该字典转换为全中文文本。这种预处理方法增加了字典的冗余性。
本文提出方法在人民日报语料、MSRA语料和计算机领域语料上进行实验,实验结果充分验证了本文模型实体识别的有效性。
2. 相关工作
第六届MUC会议(The Sixth Message Understanding Conferences, MUC-6)首次提出命名实体概念,但并未对命名实体进行明确的定义,只是简要说明需要标注的实体是“实体唯一标识符(Unique Identifiers of Entities)” [1] [2]。CoNLL-2002、CoNLL-2003会议将对命名实体识别重新定义为句子中所包含的短语,主要包括人名、地名、机构名和时间等特定领域专有名词,大体沿用了MUC会议的定义和分类规则 [3]。
随着命名实体识别的不断发展,实体的类型和数量也在不断地进行扩充。Alfonseca等 [4] 从本体构建组成角度出发,将无监督方法应用于不同语言的命名实体,用来自动扩充具有特定领域知识的实体。并且提出命名实体定义:对于与问题相关的实体对象都可以被称为命名实体。Sekine等 [5] 研究发现对于信息提取、问答系统、摘要和信息检索等方面的应用,MUC会议提出的7种命名实体类别不能满足实际需要。某些特定领域需要细分,故提出了一种命名实体层次结构,该结构包含大约150种实体类型,并在后续又对实体类别又进行扩充 [6]。Marrero等 [7] 从理论和实践的角度仔细分析了命名实体领域的演变和发展历程,发现采取适当的措施和标准方法仔细划分命名实体,有助于提升NER解决问题的能力。关于命名实体,目前也没有一个较为官方的、得到普遍认可的定义。但NLP问题的研究特点以实用性为首位,纵观整个NER研究历史,所谓命名实体识别实质上就是识别无序文本中的人名、地名、机构名和特定领域的专有名词。
早期识别方法主要是基于规则的方法。此类方法应用时间集中在MUC-6会议前后,主要识别三个实体:人名、地名和机构名。基于规则方法运用的原理主要是基于字符规则 [8] 和短语规则 [9]。具体说来,为根据字符前后信息、实体前后提示词以及前后文语境得到匹配规则,再根据规则进行实体识别。MUC-6结果显示,对于人名实体的识别效果明显高于其他实体,分类准确率均高于91%,且F1值更是高达96.42% [10]。基于规则的方法主要通过制定有限的规则和字典,然后从文本找寻含有这些规则的字符或字典中存在的字符串,将其识别出来并标注为各类别实体。但就解决NER问题而言,由于无法制定出所有规则或穷举出包含全部实体的字典,故对于大型语料库的NER而言该方法存在较大的局限性。
基于统计机器学习的方法。MUC-7会议中研究者将最大熵(ME) [11] [12] 和隐马尔可夫(HMM) [13] 等机器学习方法应用于实体识别问题中去。实验结果表明,实体的识别不再严重依赖于字典的规模,通过合理的应用文本信息,使用较小的字典也能得到很好的精度和召回率 [14]。基于机器学习方法的NER实质上是将其转化为分类问题,主要包括:确定实体边界;对命名实体进行分类。其中,最著名的方法为序列标注方法,此类方法主要是将NER问题当作序列标注问题处理,利用大规模语料来学习标注序列。标注方法可分为基于短语模型和基于字符模型两种方法,基于对短语模型存在短语边界模糊导致分词准确度不稳定,并且出现过多未登录词时,模型不能很好地对未登陆词标签进行权重赋值 [15]。在实际应用中,基于字符的序列标注方法应用更广泛,这种方法可有效减少基于词模型标注所带来的问题,但是该模型也存在一定的局限性,由于只利用到单个字符,所以不能对标注的实体进行级别衡量。字符标注规则是对文本中的每个字符分别赋予一个标签,不同标签对应不同类别的命名实体位置。此时,NER任务就简化为首先对每个字符进行序列化自动标注,然后对标注结果进行统计分类,最终就可以确定实体类别。这种序列化标注方法的提出对于解决NER问题具有里程碑式的意义,随后AdaBoost [16]、支持向量机 [17] 和随机条件场(Conditional Random Field, CRF) [18] 等方法都依次被成功应用到序列化标注中,极大提升了NER的效果。目前,序列化标注方法仍是解决NER问题的最有效方法。机器学习方法的出现使得基于规则提出的方法不具有的广泛性得到改善和解决。但这种方法在特征提取方面严重依赖于大规模人工标注语料,识别效果并不是十分理想。
随着神经网络的不断发展,深度学习方法也被应用于解决NER问题中来。尤其是利用词向量来表示文本的方法,不仅解决了高维度大型稀疏矩阵带来的高难度计算问题,还解决了人工筛选特征对应信息不完整等问题。该方法利用统一的向量维度进行特征表示,结合序列标注方法为NER问题带来了极大的希望,其中最广泛的方法为使用词向量作为特征 [19]。CoNLL-2002和CoNLL-2003两次会议研究者多采用深度学习方法解决NER问题 [20],一些感知机模型 [21] 和双向长短时记忆网络(Bidirectional Long Short-Term Memory, BiLSTM) [22] 也得到了尝试。研究者主要将现有的深度学习模型和方法进行改进,将其应用于NER问题上,如长短时记忆网络(Long Short-Term Memory, LSTM)和CRF相结合的模型,该模型使得F1值提高了5% [23]。Lample等提出了两种新的神经网络结构,一种是基于BiLSTM和CRF结合,另一种是基于转换方法构造标记片段。模型同时从标注语料和未标注语料训练得到特征,并在四种不同的语料上获得了前所未有的实体识别效果 [24]。相较于传统机器学习方法,深度学习方法通过自主学习从非结构化数据中获得更深层次和更抽象的文本特征,较好地解决了机器学习方法特征选取不准确和对非结构化数据噪声造成的干扰等问题。除了LSTM,其他深度学习方法也被成功应用于解决此类NER问题,如卷机神经网络CNN [25]、混合神经网络HNN [26] 和循环神经网络RNN [27] 等。
近期监督学习被引进应用解决NER的数据预处理环节当中,以用来提升模型的特征学习能力 [28]。Bidirectional Encoder Representation from Transformers (BERT)是由谷歌2018年提出的一种基于深度学习的语言表示模型。BERT在11种不同的自然语言处理测试任务中取得最佳效果,是NLP领域近期重要的研究成果 [29]。BERT内部机制采用Transformer的编码器和解码器结构,其中,BERT-base和BERT-large分别采用12层和24层Transformer编码器作其基本网络结构,相比于传统的深度学习网络,Transformer具有更强大的文本编码能力,能够完成大型数据语料的训练 [30]。当前,BERT模型已经成为一个基础性工具,经过预训练–微调手段可广泛应用于各种NLP领域 [31]。
3. BERT-BiLSTM-CRF模型
BERT-BiLSTM-CRF模型结构如图1所示,该模型共分为三个部分,首先利用BERT进行数据预处理学习文本特征,再将学习到的特征作为BiLSTM的输入进行训练对文本进行双向编码,最后利用CRF解码输出概率最大的标签序列。

Figure 1. BERT-BilSTM-CRF model
图1. BERT-BilSTM-CRF模型
3.1. BERT预训练
最早的神经语言模型Bengio提出的,是一种关于计算概率的方法,具体说来为从左到右计算下一个词出现的概率 [32]。主要是由词
构成的句子组成的训练集,再由神经网络训练得到出现概率的语言模型。
(1)
传统的语言模型是静态的,无法上下文表征字的多义性和语法特征等。故根据此类问题,本文采用BERT预训练模型,结构如图2所示,其中
为输入向量,
为该模型的输出向量,Trm表示Transformer结构。
BERT内部机制主要是基于Transformer的Encoder结构,其模型结构比Transformer更深,这种机制可以更好地获取上下文信息,极大地提升了模型抽取特征的能力。BERT的训练主要分为两个阶段:预训练阶段和微调阶段。BERT的预训练有两个无监督学习任务,分别是Masked Language Model (MLM)和Nest Sentence Prediction (NSP)。微调阶段是后续用于一些下游任务的时候进行的微调,根据要实现的功能进行调整。
BERT的第一个预训练任务MLM,在句子中随机选择10%的单词进行Mask,在选择为Mask的单词中,有80%真的使用[Mask]进行替换,10%不进行替换,剩下10%使用一个随机单词替换,具体举例见表1。然后利用上下文的信息预测被遮盖的单词,这样可以更好地根据全文理解单词的意思。由于本文训练集均为中文数据集,MLM采用符合中文语法规则的全词Mask,具体NSP预测任务举例如表2所示。

Table 2. Examples of NSP prediction task
表2. NSP预测任务举例
BERT的特征提取主要基于Transformer的特征提取器,Transformer是NLP研究者热衷的模型结构,自注意力机制(Self-Attantion)和前馈神经网络模型(Feed Forward Network)组成的基础,自注意力机制能帮助当前节点不仅仅只关注当前的词,从而能更好地获取到上下文语义信息 [30]。Transformer具体结构如图3所示。
Transformer的关键部分为自注意力机制,模型采用了Encoder-Decoder架构,但其结构相比于Attention更加复杂。首先,自注意力机制会计算出三个新的向量,分别为Query(
)、Key(
)、Value(
),向量维度相同。自注意力机制主要通过句子中词和词之间的关联程度调整权重系数矩阵,以此来获取词的表征。
(2)
其中,
为字符的输入向量矩阵,
为Embedding维度。具体自注意力机制模型如图4所示,其中MatMul表示矩阵相乘运算。
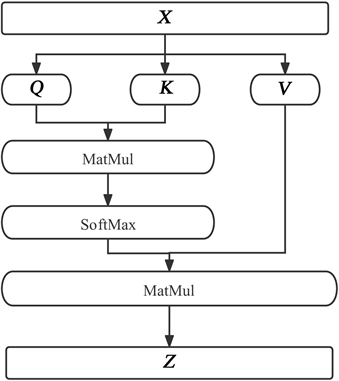
Figure 4. Self-attention mechanism model
图4. 自注意力机制模型
BERT预训练模型使用由多个自注意力机制构成的多头注意力机制(Multihead-Attention),该机制主要是通过线性变换对
投影,最后将不同的Attention结构加和起来,从而获取句子的语义信息。
其中,
,在本文BERT中使用
个平行自注意力机制,对每一个自注意力机制使用
,由于每个自注意力机制头部数量的减少,多头注意力机制与全维度的单头注意力机制计算成本相似。
多头注意力机制的好处是允许模型在不同的表示子空间里学习到相关的信息,使得模型特征学习更加准确。
3.2. BiLSTM
LSTM是循环神经网络的变体,主要是为了解决长序列训练过程中出现的梯度消失或梯度爆炸的问题。LSTM可以非常有效地利用文本上下文信息,并深度挖掘文本潜在的语义信息,减少工作量的同时,确定约束输出模型,从而达到提高实体识别精度,该方法广泛应用于文本上下文语义信息提取的问题中。
LSTM的结构可由如下公式表示:
(3)
(4)
(5)
(6)
(7)
(8)
其中,
表示遗忘门;
表示输入门;
表示输出门;
表示上一时刻隐藏层状态;
表示当前时刻隐藏层状态;
表示当前输入;
表示每一步的输出;
为偏执项。
LSTM内部主要分为三个阶段:
第一阶段为忘记阶段。这个阶段主要是对上一个节点传进来的输入进行选择性忘记,即通过
,来控制忘记门对上一状态的
哪些需要遗忘,其中,f表示forget。该门会读取
和
,输出一个在0到1之间的数值给每个在细胞状态
中的数字。1表示完全保留,0表示完全舍弃。
第二阶段选择记忆阶段。该阶段主要为对输入进行有选择性地进行记忆,当前的输入内容为
表示,选择的输入门控制信号为
。将上面两步得到的结果相加即可得到传输给下一状态的
。我们把旧状态
与
相乘,丢弃掉我们确定需要丢弃的信息。接着加上
得到新的候选值,再根据预期更新状态的程度进行变化。
第三阶段为输出阶段。该阶段决定哪些结果将会被当成当前状态的输出,输出门控制信号为
。并且还可以对上一阶段得到的
通过一个tanh激活函数进行处理。
以上就是LSTM的内部结构。单向的LSTM无法同时处理上下文信息,故双向的BiLSTM更多地应用于文本处理当中。
BiLSTM模型通过门控状态来控制传输状态,记住需要记忆的并忘记不重要的信息。由于不同于普通的RNN那样只能单一的记忆叠加方式,该网络结构能动态地捕获数据信息,对信息具有更强记忆能力。由于BiLSTM利用记忆单元和控制门限制,实现了对长距离信息的有效利用,解决了梯度消失问题,故该方法对信息检索、自动问答和知识图谱构建等领域有着重要的应用价值。
3.3. CRF
CRF模型是给定一组输入随机变量条件下,求另一组输出随机变量的条件概率分布模型,该模型特点是假设输出随机变量构成马尔可夫随机场。CRF常用于命名实体识别的序列标注问题。
设
,
均为线性链表示的随机变量序列,若在给定随机变量序列X的条件下,随机变量序列Y的条件概率分布
构成条件随机场,即:
(9)
其中,
(在
或n时只考虑单边),称
为线性链条件场,在标注问题中,X表示输入的观测序列,Y表示的对应的输出标记序列或状态序列。CRF与马尔可夫随机场相比,不仅考虑了当前时刻观测状态的信息,也考虑了上一时刻的隐藏状态信息。因此,在带有时序关系的场合,CRF的效果要更好一些。线性链条件场如图5所示。
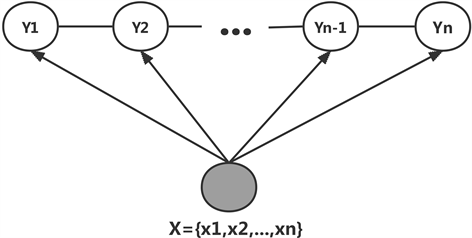
Figure 5. Conditional field of linear chain
图5. 线性链条件场
本文将采用CRF进行状态序列预测,CRF能够有效考虑字符与标签之间关系,主要利用单个字符标签的分数与字符标签之间的迁移矩阵计算不同种类标签的概率,从而得到最大概率序列即为所要寻找的状态序列。
对于输入数列
,经CRF层被训练来输出预测最大概率标签序列为
,则定义分数为:
(10)
其中,A矩阵是标签转移矩阵,
表示标签
转移到
的转移概率;P矩阵是BiLSTM输出矩阵,
代表字符
映射到标签
的非归一化概率。
模型训练的时候,对于每个序列Y优化对数损失函数,调整矩阵A的值,利用Softmax函数,为每一个正确的标签序列定义一个转移概率值:
(11)
其中,
代表所有的标签序列,
表示真实标注序列。故训练过程中,我们只需要最大化似然概率
即可,这里我们利用对数似然函数:
(12)
然后,我们将损失函数定义为
,就可以利用梯度下降法进行网络学习。
(13)
当模型完成训练,进行预测时按如下策略寻找最优路径:
(14)
其中,
表示集合中使得
函数最大的序列。
3.4. 中文转换
为了减少数字、英文字母、符号和中文混合的数据对中文实体识别的影响,我们首先将数据集中的数字、英文字符和符号转化为中文,得到更规范的数据集。人民日报为主要摘自报纸数据集,MSRA数据集是收录中文普通话的数据集,这两个数据集中夹杂的数字、英文字母和符号等较少,对识别结果影响较小,故不对这两个数据集进行规范化处理。
由于计算机领域数据集中的实体信息如计算机中央处理器、型号等多为英文和数字的组合,这种情况给中文实体识别带来了极大挑战,故本文拟对该中英文混合数据集进行数据预处理,具体中文转换规则对照如表3和表4所示。
Table 3. Roman numbers Chinese comparison table
表3. 罗马数字中文对照表
Table 4. English letters and symbols Chinese comparison table
表4. 英文字母及符号中文对照表
具体数据转化为全中文举例如表5所示。
Table 5. Example of converting data into Chinese
表5. 数据转化为全中文举例
4. 实验过程与结果
4.1. 数据集
本文有三个实验数据集分别是1998年人民日报语料、MSRA语料和自行标注的计算机信息数据集。数据采用BIO标注策略,具体为:B表示Beginning,为标注实体的开始;I表示Inside,表示实体除开始剩余的部分;O代表Other,表示无用信息。
人民日报和MSRA数据集主要标记三个实体:人名(PER)、地名(LOC)和组织机构名(ORG),数据集标签包含7个,分别是“O”、“B-PER”、“I-PER”、“B-LOC”、“I-LOC”、“B-ORG”、“I-ORG”。自行标注计算机数据集主要识别八个实体:品牌(BRD)、中央处理器(CPU)、硬盘(DSK)、图形处理器(GPU)、缓存(MEM)、尺寸(SCR)、操作系统(SYS)、型号(TYP),该数据集共包含17个标签“O”、“B-BRD”、“I-BRD”、“B-CPU”、“I-CPU”、“B-DSK”、“I-DSK”、“B-GPU”、“I-GPU”、“B-MEM”、“I-MEM”、“B-SCR”、“I-SCR”、“B-SYS”、“I-SYS”、“B-TYP”、“I-TYP”。语料规模具体情况如表6所示。
Table 6. Corpus dataset (type: character)
表6. 语料数据集(类型:字符)
4.2. 评价指标
在NLP领域评价指标主要为以下四个:准确度(Accuracy)、精度(Precision)、召回率(Recall)、F1值(F1-score)。在具体介绍指标之前,需要明确混淆矩阵的概念,我们定义TP、FN、FN和FP如下。
4.3. 实验参数
本文模型采用Tensorflow环境进行搭建,Python版本3.6,具体训练主要超参数如表7所示。
Table 7. Corpus dataset (type: character)
表7. 语料数据集(类型:字符)
4.4. 实验结果
为了验证模型的优劣,本文在三个数据集上进行对比实验,分别采用BiLSTM-CRF [33]、BERT-CRF [34] 和BERT-BiLSTM-CRF模型进行实验。具体实验结果如表8~10所示。
Table 8. Comparison of experimental results of human name daily corpus (unit: %)
表8. 人名日报语料实验结果对比(单位:%)
Table 9. Comparison of experimental results of MSRA corpus (unit: %)
表9. MSRA语料实验结果对比(单位:%)
Table 10. Comparison of experimental results of computer field corpus (unit: %)
表10. 计算机领域语料实验结果对比(单位:%)
Table 11. Comparison of BERT-BiLSTM-CRF entity recognition results of types in computer field (unit: %)
表11. 计算机领域各类别BERT-BiLSTM-CRF实体识别结果对比(单位:%)
比较BiLSTM-CRF和BERT-CRF两个模型在三个数据集上的结果,BERT-CRF较BiLSTM-CRF的F1值分别提升了6.02%、7.51%和1.88%。从实验结果可知,BERT模型具有更强的特征提取能力,充分证明BERT中多头注意力机制使得评价指标大幅度提升。BERT-CRF和BERT-BiLSTM-CRF两个模型在人民日报语料上的实验结果得到的F1值,后者较前者提升了0.72%,这种小幅度的提升主要由于BiLSTM学习中的上下文信息提取的能力,它能充分提取字符序列特征,这使得模型学习效果更好。
综合上述实验结果我们可以看到,使用BERT预训练的模型命名实体识别评价指标结果明显大幅度提升。BERT-BILSTM-CRF模型在不同实验语料中评价指标中均表现最为优秀,F1值分别取得了95.1%、95.09%和99.45%的斐然成绩。对于大型MSRA语料而言,BERT-BiLSTM-CRF较BiLSTM-CRF模型的F1值更是有12.41%的惊人提升。对于计算机领域语料而言,即使识别实体种类达到8个,各个实体F1值均大于99%,其中,品牌实体识别准确率更是高达100%。在计算机领域数据集BERT-BiLSTM-CRF模型各类别实体识别结果如表11所示。
通过以上实验结果充分表明,具有双向Transformer结构的BERT预训练模型具有更强的语义表征能力。对于计算机领域语料BERT-BiLSTM-CRF模型,除型号实体类别外,其他实体类别F1值均接近100%。由于计算机型号实体构成复杂,且不同品牌的命名型号规则区别很大的原因,导致模型识别效果不理想。该模型还存在一定的进步空间,需要对复杂实体的命名实体识别进一步进行探究。
5. 结束语
针对于中文命名实体识别问题,本文构造了一种不依赖于人工特征的神经网络BERT-BiLSTM-CRF模型。该模型通过基于双层Transformer的BERT模型进行预训练,得到具有更强表征能力的词向量,并以此作为BiLSTM神经网络的输入,充分利用文本的上下文信息对其进行进一步处理,最后,利用CRF模块解码,计算相邻标签的关联性,进而获得全局最优标签序列。与传统模型相比,该模型具有较大的优势,且在多个语料上的实验结果均有较好的表现效果。但对于构成复杂实体识别效果表现稍有欠缺,容易出现识别不全现象。如何对上述问题进行优化是进一步需要解决的问题。