1. 引言
随着互联网技术的广泛应用,我国很多城市正在利用互联网将横向的“人才群”与纵向的“产业链”联结为一体,通过“人才资源平台”融合人才、企业、产业项目,促进各种资源要素在线上、线下实时匹配对接,使人才与产业深度融合、精准匹配,以达到集聚和利用人才资源的目的 [1] [2]。
2017年,泰州市出台文件《关于打造最优人才发展生态环境的政策措施》,从人才引进、培养、使用、服务等方面提出36条举措,着力优化人才发展生态,为不断厚植跨越赶超新优势打造人才强力引擎,文件提出实施“凤还巢”计划,全面梳理泰州人才信息,加快建设泰州人才资源库,组织开展“千人计划”专家泰州行、在外能人家乡行等活动,更大范围地汇聚在泰州出生或曾在泰州学习、工作、生活过的各领域的高层次人才 [3] [4] [5]。
本文充分利用JavaEE平台的可移植性和可扩展性,以及Oracle大型数据库的海量存储和数据处理优势,构建基于阿里云平台的泰州市人才管理系统。该系统通过网站、手机Web、微信公众号等多种途径采集、汇聚各类人才资源。同时利用python爬虫技术从51Job、中国医药城人才网、泰州人才网等专业人才招聘网站爬取有效数据,通过清洗、集成、变换、规约等步骤,逐步完善泰州市人才库、产业数据库、企业数据库。系统对提升人才工作管理效能和服务水平,充分发挥人才在经济社会发展中的作用具有十分重要的意义。
2. 系统需求
系统分为人才用户、企业用户、管理员三个角色:
人才用户:包括个人注册登录、登记个人信息、更新个人信息、上传个人成果资料、查询企业项目需求信息、查询企业人才需求信息、查看系统自动推荐的企业、查询同行人才信息、推荐同行人才等功能。
企业用户:包括发布项目需求信息、发布人才需求信息、按照行业/专业/学历等筛选人才信息、查看系统自动推荐的人才、查看意向人才的详细信息、与意向人才沟通等。
管理员用户:包括核实人才/企业登记信息、核实人才推荐信息、查询各类人才/企业信息、管理系统自动采集的人才/企业信息、管理系统自动推荐的人才/企业信息、屏蔽敏感信息、数据分析统计、报表管理、角色权限管理、用户管理、数据库备份、数据导入导出等。
3. 系统设计
3.1. 系统架构设计
包括表示层、控制层、业务逻辑层、数据访问层,其中:
表示层:作为用户交互的接口层,负责系统页面显示,利用JSP页面、JavaScript、CSS、JQuery、BootStrap等技术实现。
控制层:负责处理URL请求,通过Spring MVC框架的@Controller注解将类标记为Controller,使用@RequestMapping定义URL请求和Controller方法之间的映射。
业务逻辑层:负责业务逻辑的封装,通过JavaBean组件技术封装系统相关的特定业务逻辑以及一些通用的业务逻辑,包括系统权限控制、转JSON格式数据等。
数据层访问层:负责访问数据库,通过在Hibernate框架中建立POJO对象与数据库表的映射关系(O/R Mapping),对JDBC API进行轻量级封装,实现数据库的增删改查操作。
采用分层设计的体系架构,能够降低层与层之间的依赖,有利于标准化和各层逻辑的复用,系统架构如图1所示:
3.2. 系统功能模块设计
系统分为人才管理、企业管理、项目管理、系统管理等主要功能模块,如图2所示。
3.3. 数据库设计
3.3.1. 概念结构设计
概念结构设计是在系统需求分析的基础上,把它们抽象为一个不依赖于任何具体数据库的数据模型。系统概念模型用E-R图如图3所示。
3.3.2. 逻辑结构设计
逻辑结构关系模式描述如下,其中主关键字用下划线,外键用波浪线标识。
1) 行业(行业编码、行业名称……)
2) 人才(人才编码、性别、出生年月、民族、出生地、学历、研究方向、职称、工作单位、职务、联系电话、居住城市……行业编码)
3) 人才成果(成果编码、成果名称、成果描述、成果类型……人才编码)
4) 企业(企业编码、企业名称、企业性质、地址……行业编码)
5) 岗位需求(岗位编码、岗位名称、专业、学历、人数……企业编码)
6) 项目需求(项目编码、项目名称、人才需求……企业编码)
7) 人才推荐(人才编码、企业编码、岗位编码、匹配度……)
8) 项目推荐(人才编码、企业编码、项目编码、匹配度……)
3.3.3. 物理结构设计
系统基于Oracle数据库实现,表空间talent对应的物理数据文件为./talent.dbf,size 500 M。系统设计2个日志组,每个日志组包含2个互为镜像的日志成员,大小100 M。
Group1 group member1./log1/redo1_1.log
group member2./log1/redo1_2.log
Group2 group member1./log2/redo2_1.log
group member2./log2/redo2_2.log
4. 关键模块的实现
4.1. 数据库连接池
为了高效地利用数据库连接资源,系统在spring容器中配置C3P0 JDBC连接池,每次数据库访问由Hibernate sessionFacotry从连接池中获取连接好的session对象。
4.2. 人才数据采集
人才数据的采集,除了个人登记、同行推荐等方式外,系统利用python爬虫技术从各个专业人才网站爬取相关的数据,进行清洗加工后更新到人才库。如:从中国医药城人才网(http://www.cmcrcw.com/index.php)爬取医药行业的高层次人才。通过Beatiful Soup、pymysql解析HTML文档,根据“学历”“工作年限”“行业”等关键词抓取特定标记的数据,代码如下:
# 解析HTML,抓取数据
def fillList(list,html):
soup=BeautifulSoup(htmlhtml.parser)
mydb = pymysql.connect(
host=localhost,
user=****,
passwd=****,
database=talent )
mycursor = mydb.cursor()#游标
for div in soup.findAll('div',class_='infolist-row'):
name=div.find('div',class_='list-item item1 f-left').span .a.string#姓名
sex=div.find('div',class_='list-item item2 f-left').string #性别
age=div.find('div',class_='list-item item3 f-left').string #年龄
education=div.find('div',class_='list-item item4 f-left').string #学历
work_year=div.find('div',class_='list-item item5 f-left').string #工作年限
major=div.find('div',class_='info-text f-left').p.string #专业
industry=div.find('div',class_='info-text f-left').div.string #行业
sql = INSERT INTO talent VALUES (%s,%s,%s,%s,%s,%s)
val = (name,sex,education,work_year,major,industry)
mycursor.execute(sql, val) #执行sql
mydb.commit() #提交事务
4.3. MVC模式的实现
系统中每个模块都基于MVC模式实现,以人才信息列表模块为例,各层实现的关键代码如下:
1) 数据访问层:负责访问数据库并返回Java类型对象或列表。
public List
getAll() {
String hql=from Talent //hql语句
Session session = sessionFactory.openSession(); //获取session对象
Query query = session.createQuery(hql); //query查询对象
List
list = query.list(); // OR Mapping
session.close();//关闭session
return list; // 返回对象列表
}
2) 控制层:负责获取HTTP请求信息,并调用数据访问层封装的相应方法,把调用结果传递给视图显示。
@RequestMapping(/talentList.do)
public String list(Model model) throws IOException{
List
list=talentDAO.getAll(); //数据访问层调用
model.addAttribute(list,list); //传递数据
return talent_list.jsp //返回给JSP页面显示
}
3) 表示层:在JSP页面中,通过EL表达式迭代显示控制层传递过来的Java对象或列表,人才信息列表如图4所示。
${status.index+1}
${talent.talName}
${talent.sex}
${talent.age}
${talent.workYear}
${talent.major}
${talent.industry}
更多
4.4. 数据可视化
系统利用ECharts Javascript图表库将数据统计分析的结果以折线图、柱状图、散点图、饼图等直观的方式呈现给用户,提高了数据分析结果的直观性。系统首先通过数据访问层返回List
$.ajax({
url : http://localhost:8080/talent/groupBySex,
dataType : json,
success : function(data) {
//处理返回JSON数据
varxAxisData=[];//x轴数据
varyAxisData=[];//y轴数据
for(var i=0;i
xAxisData.push(data[i].sex);
yAxisData.push(data[i].count);
}
myChart.setOption({
series : [
{ name: '访问来源',
type: 'pie', // 饼图
radius: '55%',// 饼图的半径
data:data
}
]
})
myChart.setOption(option);
}
});
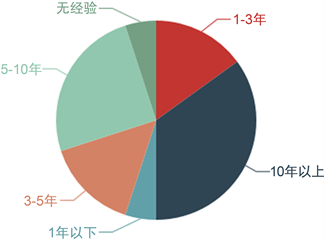
Figure 5. Distribution of working years
图5. 工作年限分布图
5. 结语
本文基于B/S架构、MVC模式实现一个人才管理系统,系统Web前端采用BootStrap框架,Web后端采用Hibernate、Spring框架,Web服务器采用Tomcat,后台数据库采用Oralce,中间件采用Redis缓存数据。系统除了提供人才、企业、项目信息的增删改查功能之外,还利用python爬虫技术实现人才数据的自动爬取,汇聚多个人才网站的资源;利用数据可视化技术,直观呈现人才与产业数据的统计分析结果。系统破除了人才工作的“信息孤岛”,实现了人才信息的共享,为人才的培养、引进、开发、服务提供数据支持和决策参考,系统的进一步完善和推广应用将为泰州市地方经济发展提供强大的人才支撑和智力支持。
基金项目
本文受到泰州市第五期“311工程”科研项目(编号:RCPY201924)、泰州市科技支撑计划项目(编号:SSF20200279)、江苏省高等学校自然科学研究面上项目(编号:19KJB520038)资助。