1. 引言
对生物多样性进行研究,特别是濒危对野生物种进行研究时,需要花费大量的人力物力寻觅、识别野生动物,获取资料后,数量统计主要是靠人工计数的方法。人工计数的方法有多方面的缺点,如消耗较大的人力物力以及较多的时间,而且由于人为因素影响,统计结果并不精确。相机技术的高速发展与硬件成本的降低,在生物科学研究领域越来越多的使用相机陷阱代替人力获取资料,红外探测器、动作传感器或者是其他光束都可以作为它的触发机关,相机陷阱已经成为了科学家们获取资料的得力助手,但是如何从海量数据中快速高效获取信息成为了研究者进行研究的关键。
基于深度学习的目标检测在野生动物识别方面有巨大优势,得益于图形处理器(GPU)的不断发展,越来越多的深度学习模型不断涌现。2012年,Alex Krizhevsk等 [1] 在ImageNet ILSVRC中获得冠军,识别率远远超过第二名,在之后的几年当中,VGG网络 [2]、GoogLenet [3]、ResNet [4]、Densenet [5] 网络结构不断问世,同时基于单阶段、双阶段的目标检测模型也大放异彩,单阶段的目标检测模型主要包括SSD [6]、RetinaNet [7]、Yolov3 [8]、yolov5、yolox [9] 等;双阶段的目标检测模型主要包括FasterRCNN [10]、MaskRCNN [11] 等。通常来说,基于双阶段的目标检测模型精度高,但是检测速度慢,基于单阶段的目标检测模型精度低,检测速度较快,并且随着YOLO系列的发展,检测精度差距也在逐步缩小。
目前,有非常多的学者提出将深度学习应用到野生动物图像识别当中,刘文定等 [12] 提出一种基于感兴趣区域(ROI)与卷积神经网络(CNN)的野生动物物种自动识别方法,并将其应用于内蒙古赛罕乌拉国家自然保护区内常见的五种生物,何育欣等 [13] 提出将卷积神经网络应用到大熊猫的检测,黄鑫达等 [14] 分别提出了基于Faster R-CNN [10]、YOLOv3 [8] 模型的改进动物目标检测算法,陈刚琦等 [15] 基于卷积神经网络的高原鼠兔图像检测,史春妹等 [16] 出基于目标检测的东北虎个体自动识别,程浙安等 [17] 提出基于深度卷积神经网络的内蒙古地区陆生野生动物自动识别,黄元涛等 [18] 以及翟俊伟等 [19] 也提出将深度学习应用于藏羚羊的检测,此外张艺秋等 [20] 和王飞等 [21] 提出了基于深度学习检测森林火灾的结构。然而,以上尝试都有各种各样限制:检测目标单一;检测场景有限;数据量较少。将之前的检测模型应用到本文的野生动物数据集中,结果不够理想。
自从Transformer [22] 在自然语言处理取得突破性的进展之后,研究者一直尝试着把Transformer用于在计算机领域。之前的各种尝试例如iGPT [23]、ViT [24],由于Transformer对于长序列的处理的局限性,都是将Transformer用于图像分类领域,直至2020年,Facebook研究团队开发出DEtection TRansformer (DETR) [25] 之后,transformer在计算机视觉应用的探索越来越广泛,2021年,MSRA提出了令人振奋的Swin-Transformer [26],在分类、检测、分割任务上都取得了最优的效果。
为此,本文将Swin-Transformer应用于野生动物检测领域。
2. Swin-Transformer
Swin-Tranformer结构如图1所示,一共有4个Stage,当输入图片(假设输入图片尺寸为 224×224 )依次经过时,特征图的尺寸不断降低,通道数增加,特征图中的特征的感受野不断扩大,与卷积神经网络不断提取特征的过程非常相似。该过程主要步骤如下:
将图片输入到网络中,经过区块划分(Patch Partition)模块,将图片按像素划分成不同的小块,将小块在所有通道上的像素拉伸为一维向量,这一维向量也称为token,将所有向量组合成矩阵,矩阵经过四个阶段(Stage)之后进行分类和回归,每个阶段由区块合并(Patch Merging)和Swin-Transformer Block组成,区块合并主要作用是降低特征图分辨率,其中第一阶段除外,小块组合在经过线性编码(Linear Embedding)后输入到Swin-Transformer Block中,线性编码仅仅改变了特征的通道数,并不降低分辨率。
2.1. 区块划分(Patch Partition)
输入图片表示为像素矩阵,需要先对图片进行patch partition处理,将图片的最小单位从像素转变为

Figure 1. The architecture of a Swin-Transformer
图1. Swin-Transformer网络架构
patch。每一个小块由
个像素构成,即用包含
个像素的区块来对像素矩阵进行分割,将每个区块所有通道中的像素值拉伸为一维向量,向量长度为48,将所有向量按照原始区块进行组合,得到像素矩阵。因此,输入的像素矩阵
(维度为
)经过区块划分处理后变为维度为
的三维矩阵,其中
表示区块的数量,48为通道数。表示为式(1)
(1)
2.2. 线性编码(Linear Embedding)
线性嵌入层应用于此原始值特征在通道数量上以将其投影到任意维度,这一过程是通过多层感知机(Muti-Layer Perception, MLP)实现的,输出维度用C表示,默认值是96,所以经过Linear Embedding之后输出
,这一过程可以用式(2)表示
(2)
2.3. Swin-Transformer Block
如图2所示,Swin-Transformer成对出现组成Swin-Transformer Block,Swin-Transformer主要包括两
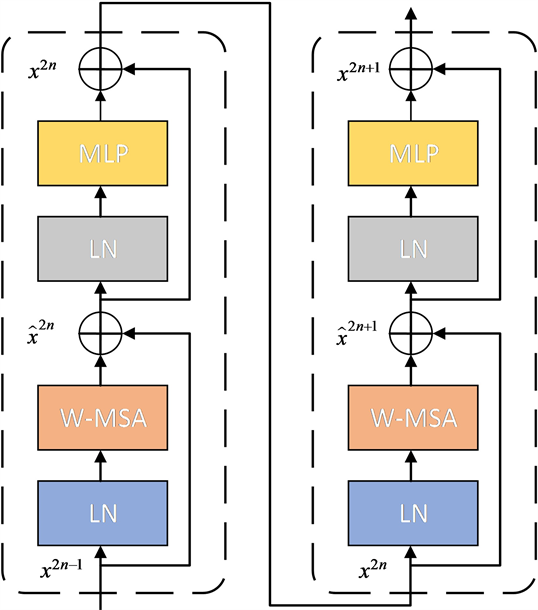
Figure 2. The architecture of Swin-Transformer Blocks (2×)
图2. Swin-Transformer Blocks网络结构(2×)
部分,多头自注意层(multi-head self-attention, MSA)不同和多层感知机(Muti-Layer Perception, MLP),在每个MSA和每个MLP模块之前应用层规范化(Layer Norm, LN)层,并在每个模块之后应用残余连接。两个连续的Swin-Transformer区别是多头自注意层(Multi-head Self-attention, MSA)不同,前者为窗口多头自注意层(window multi-head self-attention, W-MSA),后者为移位窗口多头自注意层(shifted-window multi-head self-attention, SW-MSA)组成。这一过程可以使用式(3)表示。
2.3.1. 窗口多头自注意层
多头自注意力将图片化划分为窗口,如图3所示,其中(a)为原图,(b)是W-MSA操作结果,(c)为SW-MSA结果。W-MSA本质上是将矩阵由
个区块为单位转化成
个窗口,每个窗口包括
个区块。W-MSA将输入图片划分成不重合的窗口,然后在不同的窗口内进行自注意力计算。假设一个图片有
的窗口,每个窗口包含
个区块,W-MAS整体过程如下:
(3)

Figure 3. The result of window division using different multi-head self-attention
图3. 采用不同多头自注意力进行窗口划分的结果
经过线性变换之后得到
的矩阵,然后将矩阵均分为三份,成为Transformer中Q、K、V三个特征,每个特征维度为
,然后经过矩阵转置、复制等操作,得到独立的窗口的3个的权值矩阵,维度为
,其中3表示多头注意力个数;64表示区块个数,由于输入尺寸是
,由于区块大小为7,因此一共剩下
个区块;49表示每个区块所包含的像素数量;32表示隐层节点个数由C/多头个数得到。后续三个特征根据式(4)进行操作
(4)
其中,Q、K、V分表表示Transformer的三个特征;B表示相对位置偏差;
[26] 表示特征K的方差,是一个常数。
Swin-Transformer将计算区域从以区块为单位那改为以窗口为单位,那么根据公式(4),MSA和W-MSA的计算复杂度式(5)、式(6)分别如下:
(5)
(6)
由于窗口的数量远小于区块数量,W-MSA的计算复杂度和图像尺寸呈线性关系。W-MSA虽然降低了计算复杂度,但是不重合的window之间缺乏信息交流,于是进一步引入shifted window partition来解决不同窗口的信息交流问题。
2.3.2. 移位窗口多头自注意层
Swin-Transformer Block第二层中移位窗口多头自注意层的窗口位置进行变动,得到
个不重合的窗口,如图3(c)所示。移动窗口的划分方式使上一层相邻的不重合不同之间引入连接,避免目标由于之前分布在不同窗口而产生遗漏。
但是位移窗口划分方式还引入了另外一个问题,就是会产生更多的窗口,并且窗口大小不一,计算量增加1.25倍。因此提出一种新的方式来解决这个问题,如图4所示,通过窗口滚动的方式,首先,将(a)第一行的三个窗口滚动到最后一列得到(b),然后(b)将第一列的窗口滚动到最后一列得到(c),
的窗口转换成
的窗口。

Figure 4. Illustration of an approach to shift windows for SW-MSA
图4. SW-MSA中窗口变动说明
得到新的窗口之后,SW-MSA仍然需要计算自注意力,但是通过变动之后形成的新的窗口是由不相邻的不规则窗口组成,在计算自注意力时,应该将这种情况剔除,因此通过引入Mask机制,由于矩阵后续输入到softmax函数中,当矩阵与对应的mask相加时,只需要将剔除位置的mask数值设置为−100,其余设置为0即可。具体情况如图5所示。
2.4. 区块合并
该模块的作用是在每个Stage开始前做降采样,用于缩小分辨率,调整通道数进而形成类似于卷积神经网络中的层次化的设计,增加了感受野,同时也能节省一定运算量。
每次降采样是两倍,因此在行方向和列方向上,间隔2选取元素。然后拼接在一起作为一整个张量,最后展开。此时通道维度会变成原先的4倍(因为H,W各缩小2倍),此时再通过一个全连接层再调整通道维度为原来的两倍。
3. 数据集构建
3.1. 数据集筛选
数据集是密云雾灵山地区安装的红外相机拍摄到有关野生动物的图片以及视频,视频是根据观察,
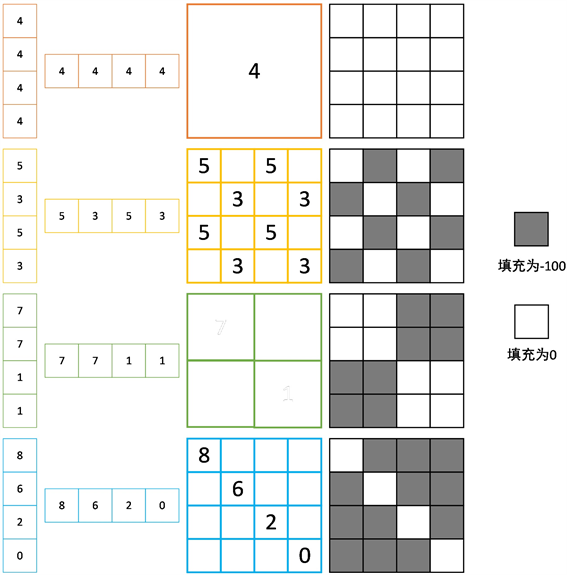
Figure 5. Mask mechanism in SW-MSA
图5. SW-MSA中mask机制
每隔10帧取出一张图片,这样保证了既不丢失目标,又可以减少工作量。最后将所有的图片经过手工筛选以及标注得到的数据集。数据集主要包括六类,每一类都由不同种类、不同场景而组成。
3.2. 数据集分析
数据集由6043张图片,共六类组成,我们将数据集划分成训练集、验证集,比例为1:1。其中训练集为3022张图片,验证集3021张图片。每类图片详见表1,根据表格可知,数据分布极不平衡,不同种类占比从2.23%~47%不等,因此,该数据集对不同网络处理类别不平衡能力要求非常高。

Table 1. The number of different categories in different data sets
表1. 不同数据集中不同类别的数目情况
3.3. 实验数据预处理
数据预处理在构建网络模型时是十分重要的,特别是训练数据比较少的时候。由于原始图片尺寸较大,为4000 × 3000,为了减少计算量,加快训练速度,在加载数据时把图片缩小到统一尺度,然后再对图片进行数据增强,有效的数据增强能够增强模型鲁棒性,防止过拟合,最后将得到的图片输入到网络中进行训练。
4. 实验结果与分析
本文训练与测试才用的数据集全部来自于第三节介绍的野生动物数据集,输入图像缩放至[224, 224],实验中所采用的预训练模型来自在微软公司发布的COCO数据集 [27] 训练的检测模型。训练优化器采用Adam,初始学习率为1e−4,batch-size大小为8。
4.1. 实验环境
本文所用实验环境详细软硬件配置如表2所示。
Table 2. Experimental environment in this paper
表2. 本文实验环境
4.2. 评价标准
本文采用AP (average precision)作为网络性能的综合评价指标,数值越大,表明检测器性能越好。与AP相关的几个概念包括IoU (Intersection over union)、准确率(Precision)以及召回率(Recall)。
IoU即交并比,表示预测框与真实框相交部分与相并部分比值,即图6中绿色部分与黄色部分面积比值,根据阈值不同,AP分为三个不同指标:AP0.5、AP0.75、AP0.5~0.95,以下以AP0.5为例进行说明。
TP (True Positive):IoU > 0.5的检测框数量(同一只计算一次)
FP (False Positive):IoU ≤ 0.5的检测框
FN (False Negative):没有检测到的Ground Truth的数量
根据上述定义,准确率(Precision)以及召回率(Recall)定义分别如式(7)、式(8):
(7)
(8)
根据式(7)、式(8)可得到P-R曲线,即
。AP就是平均精准度,简单来说就是对PR曲线上的Precision值求均值,即式(9)所示。
(9)
4.3. 实验结果与分析
不同模型检测结果如表3所示,其中,AP0.5、AP0.75、AP0.5~0.95分别表示交并比在该尺度下mAP的结果,Params表示模型参数量,FLOPs是floating point operations的缩写,表示浮点运算数,可以用来衡量算法/模型的复杂度。FPS是Frames Per Second的缩写,表示模型每秒钟处理图片张数,ms/p表示模型处理一张图片所需时间,都衡量了模型处理图片速度。Swin-Transformer在三种尺度下的结果都领先于其余模型至少5.2%,极大的提高了数据的利用率,与之相对应的是模型参数量较多,模型复杂度高,处理图片速度较慢。但是相比较于数据收集的长周期,人工处理的低效率,Swin-Transformer能够在在95%的准确率情况下,较快检测图片。
Table 3. The results of different models
表3. 不同模型检测结果
在不同类别的检测中,结果如表4所示。由于数据分布不均匀,对检测器造成了极大的挑战,但是Swin-Transformer在每一类检测中,检测精度都超过91%,尤其在图片数量很少的squirrel类别中,精度超过第二名13%,这说明即使数量稀少的物种,Swin-Transformer也有较高的准确率,对于数量稀少的物种监测十分重要。
Table 4. The results for each category of different models
表4. 不同模型对于每一类别检测结果
5. 结论
本文给出了一个雾灵山野生动物数据集,由于数据来源于野外红外相机拍摄,获取数据花费时间长、硬件成本高,目前算法对数据利用率不高,导致数据浪费,本文创造性的将Swin-Transformer应用到野生动物图像检测中,在IOU大于0.5的情况下,每一类的精度都超过了90%,相比于其他检测网络取得了领先的成绩,极大提高了数据的检测精度。