1. 引言
大脑主要由脑白质、脑灰质和脑脊液组成,其中脑白质是由许多神经纤维束组成的区域。神经纤维束一旦受损,将会导致各种神经系统疾病,因此,神经纤维束的走向和分布一直是脑科学关注的核心问题。扩散张量成像(Diffusion Tensor Imaging, DTI)是用于脑神经纤维追踪的扩散核磁共振成像(Diffusion Magnetic Resonance Imaging, dMRI)技术,能够无创、立体、直观地显示活体神经纤维束,近年来已广泛应用于疾病研究、临床治疗 [1] [2] [3]。
现有脑神经纤维追踪算法主要分为确定性纤维追踪算法和概率性纤维追踪算法。Mori等人 [4] 首先采用张量的主特征向量方向作为体素内纤维方向,进行确定性纤维追踪 (Fiber Assignment by Continuous Tracking, FACT),计算量小,实现简单,但是将纤维定义为一些折线相连,与实际上不符,追踪得到的纤维准确率低。对此,Basser等人 [5] 提出了流线型追踪(Streamline tracking, STT)算法,通过Runge-Kutta积分得到完整光滑的纤维。这两种算法都是直接将体素的主特征向量方向视为纤维方向,在各向异性值大的地方表现较好,在各向异性值小的地方会产生较大的偏差。
概率性纤维追踪算法对体素邻域内的图像信息进行建模,得到纤维方向的概率密度函数,给出所有可能纤维束路径的概率。He [6] 和Lu等人 [7] 采用贝叶斯方法实现张量信息的估计,但需要大量随机采样,耗时长;对此,Kong等人 [8] 通过粒子滤波(Particle Filtering Tractography, PFT)估计扩散张量主特征向量信息;Chinthala [9] 和Chen等人 [10] 利用无损卡尔曼滤波器(Unscented Kalman Filter, UKF)实现纤维追踪;Teillac等人 [11] 通过最小化能量函数估计张量信息。概率性纤维追踪可以减少噪声以及部分容积效应的影响,但是计算量大,效率低,会产生较多的伪纤维,无法为临床医生提供直观的结果。
综上所述,现有确定性纤维追踪算法仅考虑体素自身信息,概率性纤维追踪方法仅考虑邻域体素的影响,导致最终追踪结果会产生较大的误差。因此,本文提出一种既考虑体素局部结构又结合邻域体素信息的确定性纤维追踪方法。先对体素进行聚类,接着,对于非细长状模型体素的张量信息,用移动最小二乘法进行拟合更新,得到新估计的张量信息。最后,在新的张量信息场中进行纤维追踪,得到更加完整准确的脑神经纤维束。实验结果表明此方法可追踪到更加精确完整的纤维束,能够为临床诊断提供辅助分析。
2. 基本原理
2.1. 扩散张量模型
在大脑中,水分子沿着神经纤维的扩散强度远大于垂直于神经纤维的扩散强度,表现为各向异性扩散。为了充分描述每个方向的分子扩散强度以及这些方向之间的相关性,需要由张量参数表示扩散强度,数学上等同于一个3 ´ 3的正定对称矩阵
(1)
设有一个未添加方向梯度脉冲的图像信号S0和N个添加方向梯度脉冲的图像信号
。扩散张量D可通过求解下列方程得到。
(2)
其中gi表示第i个扩散脉冲梯度归一化的方向,b表示扩散敏感因子。
设λ1、λ2、λ3为D的特征值, e1、e2、e3为相应的正交单位特征向量,则
(3)
Westin 等人 [12] 用椭球对扩散张量进行建模,他们提出了三类体素张量模型:细长状、扁平状和圆球形状。当
时,张量模型为细长状见图1(a)。当
时,张量模型为扁平状,见图1(b)。当
时,张量模型为圆球状,见图1(c)。
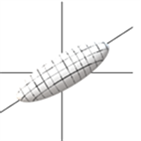 (a) 细长状
(a) 细长状 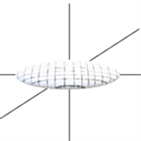 (b) 扁平状
(b) 扁平状  (c) 圆球状
(c) 圆球状
Figure 1. Three models of diffusion tensors
图1. 扩散张量的三种椭球模型
用CL表示线性扩散的强度,CP表示扁平扩散的强度,CS表示球形扩散的强度,定义为
(4)
显然,
且
。
2.2. K-Means聚类
K-means聚类算法思想简单,效果较好,应用广泛,已用于图像分割、特征学习等方面 [13] [14] [15]。K-means聚类算法通过以下几个步骤实现快速聚类:指定K个聚类中心;计算数据和聚类中心的相似性;通过最小化误差的平方和,迭代更新聚类中心;当误差的平方和不再改变时,聚类结束。
2.3. 移动最小二乘法
2.3.1. 移动最小二乘法原理
移动最小二乘法(Moving Least Squares, MLS) [16] 与最小二乘法最大的不同主要表现在:移动最小二乘法认为体素S处的值f(S)只受S的某个邻域ΩS内体素的影响,邻域ΩS外的体素对f(S)没有影响,这个邻域ΩS称为体素S的影响域。在影响域ΩS上定义一个权函数w设置影响域内体素Si对体素S的影响程度。
取基函数
,定义体素S的张量拟合函数
其中
为待求系数。
设
,D(Si)是体素Si处的张量,则体素S处的误差:
(6)
为确定a(S),令E(S)取最小值,则上式对a求导
(7)
令其为零,得
(8)
其中
(9)
(10)
(11)
2.3.2. 权重函数
合适的权重函数可以实现更好的拟合效果。由于纤维追踪是一个连续的过程,邻域体素信息对体素的纤维方向有较大影响,距离越远,影响越小,距离越近,影响越大。因此,采用高斯函数作为权重函数。
各向同性高斯函数形如:
(12)
3. 纤维追踪方法
当体素的张量模型为细长状时,将体素的主特征方向作为纤维方向是可靠的,但是当体素的张量模型为扁平状或者圆球形时,这种方法会产生较大的误差。因此,需要根据张量模型的不同对体素进行聚类,再考虑邻域信息的影响对体素张量信息进行更新。
3.1. 基于扩散特性的K-means聚类
本文基于体素扩散强度参数(CL 、CP、CS)相似性,采用K-means聚类算法将体素聚为3类。具体步骤如下:
步骤1对体素Si设置其标志位Fi = 0,扩散强度系数(
、
、
),
;设类Qj = Æ,j = 1,2,3;从J中随机选择三个体素作为初始的3个聚类中心{m1、m2、m3};
步骤2对体素Si,计算扩散强度(
、
、
)和聚类中心mj的扩散强度(
、
、
)的相似性:
(13)
若di1 < di2, di3,则令Fi = 1,将Si加入到类Q1中。若di2 < di1, di3,则令Fi = 2,将Si加入到类Q2中。若di3 < di2, di1,则令Fi = 3,将Si加入到类Q3中;di1 = di2 = di3,随机加入一个类中。
步骤3更新聚类中心。重复步骤2~步骤3,直至聚类中心不再变化,此时Fi就是体素Si对应的类别。
3.2. 结合张量模型的自适应各向异性高斯函数
各向同性高斯函数在x、y、z方向设定相同的尺度参数s,且仅考虑邻域体素与体素之间的距离,没有考虑体素的局部结构,如图2(a)所示。然而,在实际纤维追踪过程中,沿着体素主特征向量方向应该分配更高的权重,见图2(b)。因此,宜采用各向异性高斯函数分配权重 [17] [18] [19],在x、y、z方向设定不同的尺度参数sx、sy、sz,即令:
(14)
各向异性高斯函数作为权重函数时,仅能使得x、y、z方向的权重不同,但是实际体素张量的特征向量方向可能是任意的,因此,本文提出一种结合张量模型的自适应各向异性高斯函数,其方向和沿着各个方向的尺度可以随着张量椭球模型变化而变化。
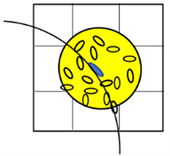 (a) 各向同性高斯模型
(a) 各向同性高斯模型 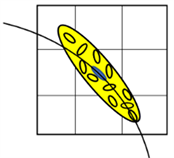 (b) 各向异性高斯模型
(b) 各向异性高斯模型
Figure 2. Gaussian function model
图2. 高斯函数模型
为此,对张量D,应根据特征向量e1、e2、e3调整坐标系,根据特征值λ1、λ2、λ3调整尺度,从而为沿着主特征向量方向的体素施加更大的权重因子。设
表示当前体素与邻域体素的偏差向量。定义
(15)
令
,则上式可表示为:
(16)
即将体素及邻域体素旋转到张量特征向量构成的方向坐标下,并按照特征向量对应的特征值对体素之间距离进行缩放。则上式可表示为:
(17)
因此可构建结合体素张量模型的自适应各向异性高斯函数
(18)
由上述过程可知,上式定义的各向异性高斯函数的方向可随着体素张量模型而调整,并根据特征方向对应的特征值缩放体素与邻域体素的距离,从而为影响域内体素施加合适的权重。
4. 实验
4.1. 算法流程
本文提出的结合K-means和MLS的脑纤维追踪算法KM-STT,具体如图3所示。
步骤1输入DW图像,计算得到DT图像张量数据,并计算DT图像中的FA、CL、CP、CS等值,初始化x,y,z = 0。
步骤2采用基于扩散特性的K-means聚类将体素聚为3类。
步骤3根据聚类结果的不同,选择性的更新张量信息。(a) 选择体素Si (x, y, z);(b) 根据聚类结果判断该体素的扩散张量模型,对于呈扁平状的体素和呈圆球状的体素,选择自适应各向异性高斯函数作为权重函数的MLS对张量进行拟合,更新体素张量;重复(a)~(b)步骤,直至遍历DT图像中的所有体素。
步骤4 在更新后的张量场中,采用STT算法追踪,并可视化纤维追踪结果。
4.2. 实验结果
可以通过对临床数据集进行实验定性的评估纤维追踪结果,但是由于缺少Ground Truth,不能对追踪结果进行定量的比较。使用模拟人脑数据集可以定量的评价追踪结果,但是其无法代替真正的临床数据集。因此本文采用一份临床数据集及一份模拟数据集对追踪结果进行定性定量的评价。
本文采用的临床数据集为头部128 ´ 128 ´ 60的体数据,包括63个施加梯度脉冲信号的DW图像和一个不施加梯度脉冲信号的DW图像,空间分辨率为2 mm ´ 2 mm ´ 1.99 mm,b = 1000 s/mm2。为了更好的比较KM-STT与STT追踪结果,选取感兴趣区域{0 ≤ x < 128, 0 ≤ y < 128, z = 30}进行观察比较。图4所示为STT算法与KM-STT算法追踪效果比较图,其中(a1)~(a2)为STT算法效果图,(b1)~(b2)为KM-STT算法效果图。从局部图可以看出,KM-STT算法的追踪结果相较于STT算法的追踪结果更完整。
本文采用ISMRM2015挑战赛发布的模拟人脑数据进行定量对比实验,该数据集包括33份头部体数据,每份体数据大小为90 ´ 108 ´ 90,空间分辨率为2 mm ´ 2 mm ´ 2 mm,b = 1000 s/mm2。Tractometer [20] [21] 是ISMRM2015挑战赛的独立评估工具,已广泛的应用于该数据集的纤维追踪效果评估 [22] [23]。Tractometer提供的量化指标有:不正确的纤维束数量(Invalid Bundles, IB),正确的纤维束数量(Valid Bundles, VB)表示,错误连接的区域的百分比(Invalid Connection, IC),正确连接的区域的百分比(Valid Connection, VC)。
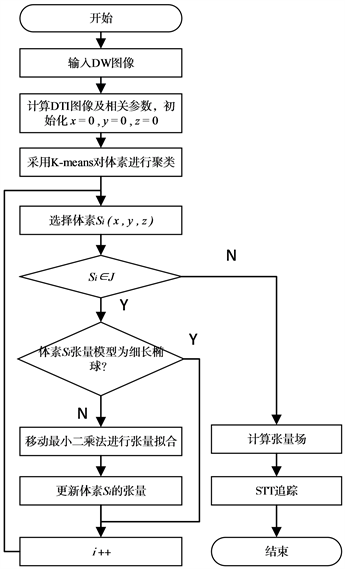
Figure 3. Tensor information update flowchart
图3. 张量信息更新流程图
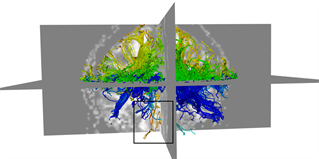 (a1)
(a1) 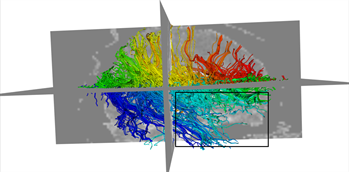 (b1)
(b1) 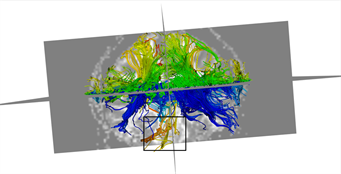 (a2)
(a2) 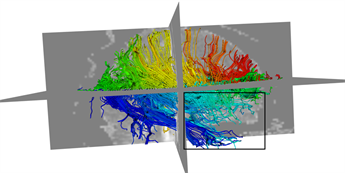 (b2)
(b2)
Figure 4. Comparison of tracking effect between STT and KM-STT
图4. STT与KM-STT算法追踪效果比较图

Table 1. Comparison of Tractometer between others and KM-STT
表1. 其他算法与KM-STT算法Tractometer对比表
注:Ground Truth中的VB为25束。
从表1中数据可知,本文算法KM-STT的追踪结果精确度优于STT算法和FACT算法追踪结果。具体表现在:KM-STT相较于其他四种算法可以追踪到更多可用的纤维束(VB);在错误连接比例(IC)方面,PFT + STT追踪结果取得了最小的错误连接比,但是在正确连接(VC)方面,PFT + STT追踪结果的正确连接比最小,KM-STT追踪结果的正确连接比最大,而且在不可用的纤维束中(IB),KM-STT和STT远低于其他三种算法。现有STT、FACT等确定性纤维追踪算法仅考虑体素自身信息,PFT + STT、UKF + STT等概率性纤维追踪方法仅考虑邻域体素的影响,导致最终追踪结果会产生较大的误差。KM-STT作为一种既考虑体素局部结构又结合邻域体素信息的确定性纤维追踪方法,能取得较好的追踪结果。综上所述,通过主观的纤维追踪结果的观察以及客观的追踪数据分析,本文算法KM-STT能提供更加完整,更加精确的纤维追踪结果。
5. 结语
在张量模型为细长状时,采用主特征向量方向作为纤维的行进方向的方法较为可靠,但是当张量模型为圆球形或者扁平状时,这种方法会产生较大的误差。针对此问题,本文提出了一种根据用结合张量值和邻域体素张量特性的纤维追踪方法。由实验效果可以看出,本文提出的算法KM-STT可以追踪出更加完整精确的脑纤维,为临床研究提供视觉效果更加良好的脑纤维追踪结果。在下一步的研究中,可以结合DTI去噪算法减少临床数据中噪声的影响,从而进一步提高在临床数据集中追踪结果的准确率。
基金项目
广东省自然科学基金(No. 2017B010110007)。
参考文献