1. 引言
贵州省脱贫攻坚消除贫困、改善民生、逐步实现共同富裕,是社会主义的本质要求,也是中国共产党的重要使命。本文依据幸福指标评价构建的三大原则,包括区域性、代表性及可操作性 [1],针对贵州省的实际情况,脱贫攻坚战略实施以来所取得的成就 [2],从城镇就业增长人数角度分析近几年来贵州省发展情况。刘攀结合贵州林业推进扶贫攻坚优势和采取的举措,提出做好林业扶贫攻坚工作的对策建议 [3]。于冰认为每个阶段的不同情况,导致脱贫攻坚存在的问题也在不断变化,要精准识别发展转向和矛盾所在 [4]。
贵州省在保障城镇居民就业方面的工作稳步开展,绝大多数的城镇居民基本生活得到保障。冉茂文研究发现,城镇发展能够辐射周围经济欠发达的地方,贵州省脱贫重心应从农村转向城市 [5]。李如是基于灰色关联度分析指出城镇新增就业人口变化具有一定周期性 [6]。吴江认为城镇新增就业人数受到当地经济发展,产业结构,教育水平等多方面的影响 [7]。新增就业人数能够较为直观地反映贵州省脱贫攻坚的进展,因此对新增就业人数未来走势的预测,能为未来脱贫工作的研究提供参考。预测是决策的基础和依据,对新增就业人数进行预测,能够为相关政策措施的实施提供一定的帮助,所以对贵州省新增就业人数的预测是有意义且有必要的。
2. 理论基础
2.1. 季节乘积ARIMA模型
ARIMA模型(Autoregressive Integrated Moving Average model),差分整合移动平均自回归模型,又称整合移动平均自回归模型,是时间序列预测分析方法之一 [8]。ARIMA(p,d,q)中,AR是“自回归”,p为自回归项数;MA为“滑动平均”,q为滑动平均项数,d为使之成为平稳序列所做的差分次数。而季节乘积ARIMA模型就是ARIMA模型和季节模型的综合。如果时间序列Yt除了趋势变动外,还有较明显的季节性变动,就先要对序列进行逐期差分,消除趋势性,再进行季节差分消除序列的季节性,差分步长应与季节周期一致,然后建立包含季节差分的有关参数的ARIMA模型,即季节乘积ARIMA模型。ARIMA(p,d,q) × (P,D,Q)S模型的一般表达式为:
其中,
是非季节自回归多项式,p是自回归阶数;
是非季节移动平均多项式,q是移动平均阶数;
是季节自回归多项式,其中P是季节自回归阶数;
是季节移动平均多项式,其中Q是季节移动平均阶数;
为差分算子,d为差分阶数;
为季节差分算子,D为季节差分阶数,s为季节周期。
2.2. 确定性因素分解方法
确定性因素分解方法的基本思想是:尽管不同的序列波动特征千差万别,但是序列的各种变化都可以归纳成四大类因素的综合影响 [8]:
1) 长期趋势(trend):该因素的影响会导致序列呈现出明显的长期趋势(递增、递减等);
2) 循环波动(circle):该因素会导致序列呈现出从低到高再由高至低的反复循环波动,如果观察时期不够长则改为交易日(day)因素;
3) 季节性变化(season):该因素会导致序列呈现出和季节变化相关的稳定的周期波动;
4) 随机波动(immediate):除了长期趋势、循环波动(交易日)、季节性变化之外,序列还会受到各种其他因素的综合影响,而这些影响导致序列呈现出一定的随机波动。
3. 分析与预测
3.1. 新增就业人口走势分析
贵州省2002年1月至2019年12月城镇新增就业人数的历史数据序列记作Y,从时序图(图1)可以大致看出其历史走势与波动状况,图中横坐标为年份,纵坐标表示新增就业人数。
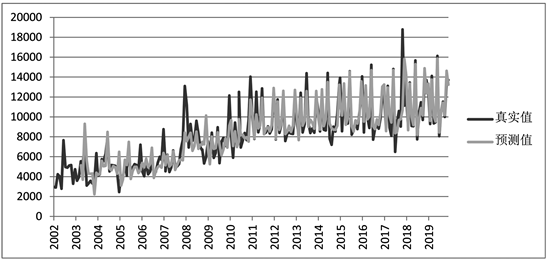
Figure 1. Time series of newly-increased urban employment population from 2002 to 2019
图1. 2002年至2019年城镇新增就业人口时序图
城镇新增就业人数呈现明显的增长趋势,且在一定程度上受到季节效应因素的影响。这里是广义的“季节”,即凡是呈现出固定的周期性变化的事件都可以称它具有“季节”效应。从图2可以看到新增就业人口数量存在明显的季节效应,3月和6月新增人数明显高于其他月份。
总体来看,新增就业人口呈现出逐渐上升的趋势性以及明显的季节性特征,季节性波动的趋势性以及明显的季节性特征,季节性波动,速度逐渐放缓。
由于贵州省2016年1月至2019年10月城镇新增就业人数序列显示出一定的规律性,如该序列有显著的增长趋势、有固定的变化周期等,因此考虑采用确定性分析方法,这里采用常用的确定性因素分解方法。

Figure 2. Seasonal fluctuations in new employment
图2. 新增就业人口的季节性波动
由于指标的量级不同,当各指标间的水平相差很大时,若直接利用原始指标值进行分析,就会突出数值水平较高的指标在综合分析中的作用,降低数值水平较低指标的作用。为了保证结果的可靠性,在数据整理完成后,再进一步通过SPSS软件对数据进行标准化处理,处理步骤:SMS数据窗口依次点击:分析–描述统计–描述,将各变量选入备选框,选择将标准化得分另存为变量,点击确定,在数据窗口得到各变量的标准化得分 [9]。
3.2. 建立ARIMA模型
由于从预测角度看,近期的数值要比远期的数值对未来有更大作用,为了利用更多历史数据的同时使得模型预测的精确度更高,本文选取2002年1月至2019年12月共18年间新增就业人数的月度数据。其中2002年至2018年的所有数据用作建立ARIMA模型的样本,2019年数据用于样本内预测以检验模型的拟合效果。
本文采用R 3.6.3软件和Eviews10.0软件建立模型并进行预测。ARIMA模型的建立流程如图3所示。
建立ARIMA模型通常有时间序列的预处理、模型识别、模型定阶、参数估计、模型有效性验证几个步骤。
1) 时间序列数据的预处理
时间序列必须同时满足平稳性与非白噪声两个条件才能适用ARIMA模型进行分析预测。如果数据是非平稳的,可使用指数化或差分的方式将其变为平稳数据,若序列是白噪声的,说明各数值之间没有明显的相关关系,即过去的情况对未来的趋势发展没有影响,所以没有价值,因此对数据的预处理包括平稳性检验与白噪声检验两部分。首先可以从该序列的时序图来观察其平稳性,从图1可以看出新增就业人数有增长趋势,并且有明显的季节性波动,数据是非平稳的。用单位根检验看其平稳性(结果见表1),可以看到ADF检验统计量值为−2.5690,大于检验水平为1%、5%、10%的临界值,所以存在单位根,该序列是非平稳的。

Table 1. Unit root test for sequence Y
表1. 序列Y的单位根检验
为使序列变平稳,将原序列Y进行一阶差分处理,得到序列DY。
从图4可以看出差分后的序列DY始终在一个常数值上下波动,趋势性消除,对其进一步进行单位根检验(结果见表2),可知此时拒绝存在单位根的原假设,序列DY是平稳的。
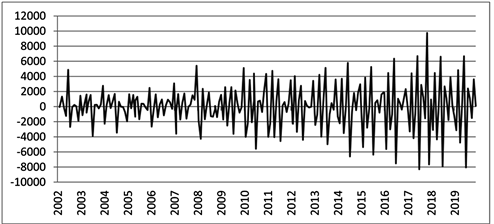
Figure 4. Timing diagram of sequence DY after differing
图4. 差分后的序列DY的时序图
Table 2. Unit root test for sequence Y
表2. 序列Y的单位根检验
平稳性检验通过后,还要对序列DY进行白噪声检验,因此做出其自相关与偏自相关图进行进一步考察,从图5可看到,在6阶、12阶、18阶、24阶,Q统计量的P值均小于0.05,因此该序列为非白噪声序列。通过上述检验,可知DY为平稳非白噪声序列,可以建立ARIMA模型。
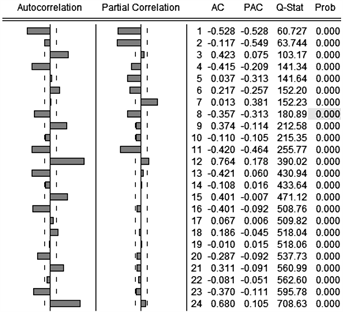
Figure 5. Autocorrelation graph and partial autocorrelation graph of sequence DY
图5. 序列DY的自相关图与偏自相关图
2) 模型识别
序列DY没有明显的拖尾和截尾特征,难以按照传统方式定阶。可以注意到自相关图中。延迟12阶和24阶时,自相关系数达到最大且显著大于两倍标准差,可以推测序列DY具有以12为周期的季节性波动特征,因此可以将序列DY进行季节调整。将序列DY进行十二步差分,得到一阶十二步差分序列DY12,时序图、自相关及偏自相关图分别见图6和图7。
从季节调整后的时序图(图6)可以看到受季节因素影响的波动减小,但是自相关图和偏自相关图(图7)截尾和拖尾趋势仍不明显,尝试拟合ARIMA模型但是效果较差。观察到在延迟12阶时AIC和PAIC仍较大,在图中仍明显突出,可以认为季节调整后的序列中仍存在季节效应,因此该序列的短期相关性与季节效应有复杂的关联性,不能简单提取,可以尝试拟合乘积季节ARIMA(p,d,q) × (P,D,Q)S模型。
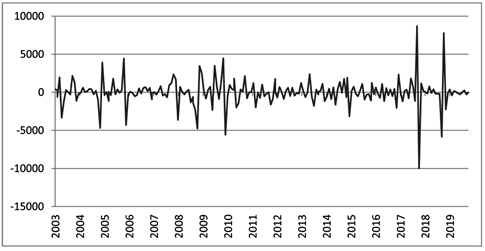
Figure 6. Timing diagram of seasonally adjusted sequence DY12
图6. 季节调整后序列DY12的时序图
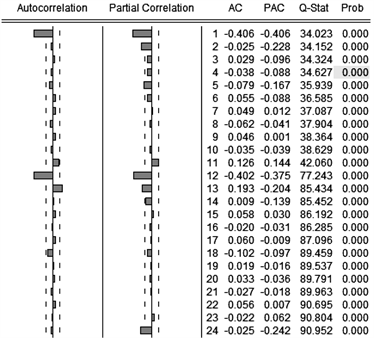
Figure 7. Autocorrelation and partial autocorrelation plots of sequence DY12
图7. 序列DY12的自相关及偏自相关图
由于序列进行了一阶十二步差分,因此d、D均为1,s为12。通过图7可以初步判定p为2,q为1。这里为了找到最优拟合模型,对p和q都分别选取0, 1, 2进行试验,同样,对于P和Q也分别选取0, 1, 2进行试验。对于模型的筛选,首先看参数显著性,如果参数不显著,则应该剔除不显著参数的自变量重新拟合模型,从低阶到高阶依次建模,最后得到ARIMA(1,1,1) × (0,1,1)12和ARIMA(2,1,1) × (0,1,1)12两个模型。进一步比较两个模型的AIC准则、SC准则、HQC准则以及拟合优度,如表3。
Table 3. Comparison of related statistics between the two models
表3. 两模型相关统计量的比较
从表3中的数据可以看到,相较来说MOD2的AIC准则、SC准则及HQC准则都更小,同时拟合优度R2更大,因此认为MOD2更好,即选择ARIMA(2,1,1) × (0,1,1)12为最优拟合模型。
3) 模型有效性验证
要对得到的ARIMA模型进行有效性检验,即检查检验残差是否满足方差齐性假定,残差序列检验结果如图8。延迟6阶、12阶、18阶、24阶时,Q统计量的p值都远远大于0.05,因此残差序列是白噪声的,即相关信息已被模型充分提取,所建模型是有效的。
4) 模型拟合效果检验
建立了ARIMA(2,1,1) × (0,1,1)12模型后,用2019年的数据对其进行样本内预测,检验其拟合效果。
图9加入了2019年各月新增就业人口的真实值进行对比,可以看到实际值与预测值均落在95%的预测区间内,并且两者较为贴合。模型的预测值与预测区间如表4。
可以看出尽管实际值与预测值有出入,但是相对误差较小,平均误差为3.5%,预测精度较好。稳妥起见,用ARIMA模型对2002至2019各年度新增就业人数的月度数据进行预测,看其整体拟合效果。由于数据进行了差分,预测样本范围缩小为2003年4月至2019年12月。

Figure 8. Autocorrelation and partial autocorrelation plots of residual series
图8. 残差序列的自相关及偏自相关图

Figure 9. The deviation between the real value and the predicted value in 2019
图9. 2019年新增就业人口数据真实值与预测值的偏差
Table 4. System resulting data of standard experiment
表4. 模型预测结果与真实值对比
经过以上步骤建立了ARIMA(2,1,1) × (0,1,1)12模型,最终计算得出的模型口径如下。
3.3. 预测与讨论
ARIMA模型适用于短期的预测,因此本文对2020年我国的外商直接投资额进行预测。表5和图10是2020年贵州省城镇新增就业人数预测结果。
Table 5. Comparison of model prediction results with real values
表5. 模型预测结果与真实值对比

Figure 10. Curve: system result of standard experiment
图10. 2020年城镇新增就业人口预测结果
若不受突发事件的影响,点预测值即为新增就业人数序列的理论值。由于2020年初爆发了新冠肺炎,因此分析这一重要事件对就业造成的影响,能够使预测结果更贴近现实。用已知的2020年1月至4月贵州省实际新增就业人数,与ARIMA模型的预测值进行对比(见表6和图11),以此来观察并分析新冠疫情的影响程度及疫情下新增就业人口的走势。
Table 6. Comparison of model prediction results with real values
表6. 模型预测结果与真实值对比
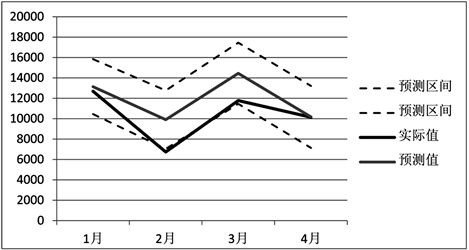
Figure 11. Comparison of the predicted and actual valuesin 2020
图11. 2020年新增就业人数预测值与实际值对比
1月份,新冠肺炎尚未大范围传播,城镇就业新增人口依然维持着平稳增长的趋势,实际与预测值的相差较小,在接受范围内。2月份,新冠疫情到了爆发期,新增就业人口开始受到极大影响;在图11中也可以看到2月的实际值超出了95%水平下的预测区间下限。3月份,随着中国疫情基本得到控制,与预测值相比,相对误差较上月明显减少,实际值贴近预测区间下限,回到区间范围内,可见就业状况出现一定稳定迹象。4月份新增就业人数与预测值仅相差0.3%,说明新冠疫情带来的影响逐渐消退,我国居民就业开始回到正轨。因此,新冠疫情这一重大随机性事件带来的影响是阶段性的、暂时的,并不会改变总体稳定的大趋势。这也说明前文ARIMA模型的预测结果仍是有效的。
4. 结论与展望
本文对我国2002年至2019年实际新增就业人口数据进行分析,建立ARIMA(2,1,1) × (0,1,1)12模型,样本内预测结果显示模型拟合效果较好;运用该模型对2020年各月份我国的外商投资额进行了预测,结果显示未来贵州省新增就业人数将保持较为稳定的季节性波动和长期增长趋势,最后进行了稳健性检验,并且对重大随机性事件造成的影响进行了分析,来进一步检验预测结果的可靠性。根据以上预测结果以及分析,建议如下:从短期看,面对疫情这类重大随机性事件,缓解“就业难”的问题是当务之急,并落实福利保障等政策以应对疫情的冲击;同时,“脱贫攻坚”工作以来,每一年度贵州省城镇居民就业人数都呈持续增长趋势,在很大程度上解决了城镇居民的基本生活问题,在一定程度上缓解了贫富差距的进一步扩大,这是贵州省“脱贫攻坚”工作的重要成果体现。
致谢
论文最后感谢山东省自然科学基金的资助,感谢胡锋老师的指导和审稿人提出的建议。
基金项目
山东省自然科学基金(批准号:ZR2017MA012)。