1. 引言
臭氧本身具有独特的鱼腥味 [1],这也是最初被人们发现的主要原因。当少量臭氧存在于人类生活的对流层时,对人类生活和健康状况不会产生威胁 [2]。高浓度的臭氧环境会损害人类的心肺功能,诱发呼吸道等各类疾病。在对珠江三角洲地区的研究表明,臭氧浓度与每日的死亡率呈现正相关性,对急性死亡具有明显的影响 [3]。城市中的臭氧主要由氮氧化物(NOx)、挥发性有机物(VOCs)在适宜条件下作用产生 [4],随着现代工业的发展,煤矿、石油的燃烧以及汽车尾气的大量排放,空气中的臭氧浓度严重超标,2015年中国环保部发布的京津冀长三角、珠三角区域以及74个城市空气质量状况的报告显示,臭氧已经成为影响空气质量的首要污染物 [5]。严峻的臭氧环境污染使得对臭氧浓度预测的研究不容忽视,尤其是大数据时代的到来,更多的数据分析被运用到臭氧浓度预测上,Alqamah Sayeed用深层卷积神经网络开发一个提前24小时预测臭氧浓度的模型,证实了模型的可接受准确性,但同时也提出,该模型的预测结果仍低估了每日的臭氧含量,准确率不够,为以后的研究和改进提供方向 [6]。王振友提出运用矩阵改进GM模型对大气中的臭氧含量进行分析,使得预测结果相对误差在6%以内,与实际数据吻合度良好 [7];朱佳运用小波分解分离复杂的信号频率,结合最小二乘支持向量机建立臭氧预测模型,并通过对比实验,证明了模型优于SVM模型和ANN模型 [8];张春露在针对SVM模型、ARIMA模型以及LSTM模型在AQI指数上预测的有效性问题进行了对比实验,得出LSTM模型预测精度最高的实验结果 [9]。为了更好的对臭氧浓度进行预测,本文运用时间序列延迟相关算法对LSTM模型进行改进,提出了基于时间序列延迟相关算法改进的LSTM模型(TD-LSTM),能够有效的提升臭氧浓度的预测精度,在相同的条件下,运用杭州市多个站点监测的臭氧浓度数据进行对比实验,证实了提出的预测模型的有效性。
2. 相关技术介绍
2.1. 时间序列延迟相关算法
时间序列延迟相关算法是时间序列数据挖掘的重要研究内容,目前已经在股票市场、气候分析、天气预报等领域得到应用 [10]。具体来说,对于两个时间序列
和
进行计算分析,找到两个序列延迟相关性最大时的延迟时间 [11],延迟相关是指两个时间序列的最大相似度不是发生在
的时刻,而是
的时刻,此时s就是延迟的大小,计算公式如式(1)、(2)所示:
(1)
(2)
s的变化区间为
,当延迟的位置s较大时,实验的误差也会变大。当s的值从0变化到n/2时,会产生多个
的值,
最大的值就是两个序列相关性最大的时候,称为“最大延迟相关点”,此时的延迟s就是需要的最优值。
2.2. LSTM神经网络
长短期记忆模型(Long Short-Term Memory neural network, LSTM)是一种特殊的递归神经网络 [12],和传统的递归神经网络(Recurrent Neural Networks, RNN) [13] 有所不同,将隐藏层更换成LSTM模型的细胞单元,使其可以长期记忆,便于处理长时间延迟的时间序列。它是一种基于时间序列的模型,它的选择性记忆门能够更好地建立先前的信息和当前环境的时间相关性,是对RNN模型的一种改进。LSTM神经网络有三个门控,输入门、输出门、遗忘门,其模块示意图如图1所示,矩形表示神经网络层,圆形表示逐点操作。控制门主要是由一个sigmoid函数 [14] 与点乘操作组成,可以决定多少信息可以传送出去,记忆门中增加存储单元来存储历史信息,可以有效解决神经网络中的梯度消失问题,可以更加深入挖掘时间序列中存在的规律。
假设
分别表示在t时刻,遗忘门、输入门和输出门的数值,则:
(3)
(4)
(5)
3. 模型介绍
3.1. 基于空间分布的LSTM预测模型(SpaceLSTM)
基于空间的LSTM模型(SpaceLSTM),将污染物空间传播的特性考虑在内,在原始LSTM模型的基础上,利用不同空间分布上多个监测站点的臭氧浓度的历史数据,对当前时刻的臭氧浓度进行预测。该模型输入多个不同地理位置站点的臭氧浓度数据,经过数据预处理之后经由LSTM模型,得出臭氧浓度的预测结果。实验结果运用均方根误差(RMSE)作为评价指标,具体公式如(6)所示:
(6)
其中,
表示臭氧浓度的预测值,
表示臭氧浓度的真实值,n表示训练数据集的样本数量。均方根误差值越小,表明模型预测的准确度越高。
3.2. 基于时间序列延迟相关算法改进的LSTM模型(TD-LSTM)
针对基于空间分布的LSTM模型(SpaceLSTM)忽略了空间分布上不同站点之间臭氧污染因子影响不同的问题,提出基于时间序列延迟相关算法改进的LSTM模型(TD-LSTM),运用时间序列延迟相关算法,考虑不同站点数据之间的延迟相关性,使得预测模型更加准确。
TD-LSTM模型的流程图如图2所示,具体执行步骤分为以下四步:
1) 数据预处理。由于数据样本是由多个不同站点数据组成,不同站点之间使用不同的量纲和量级,并且数据因子范围较大,为了实验的准确性和高效性,需要对实验数据进行归一化的处理,本文采用min-max标准化法,计算公式如(7)所示:
(7)
其中,
、
分别表示空气质量检测数据中的最大值和最小值,
表示归一化之后对应的监测数值,
为实际监测值。
2) 运用时间序列延迟相关算法,计算数据输入矩阵。
将臭氧浓度小时监测数据按监测时间的先后转换成时间序列,每个站点数据对应一条时间序列,用
表示需要预测的目标站点S在t时刻的监测数据,
表示站点S的编号为j的周边站点在t时刻的监测数据,其中,m表示周边监测站点的个数,则原始输入样本数据矩阵为
,如公式(8)所示:
(8)
其中
,
。
假设周边站点
与目标站点S达到最大延迟相关时,它与目标站点S的最大延迟相关点为
,由于延迟的概念是相对的,若时间序列A延迟于时间序列B的时间为
,我们也可以认为时间序列B超前时间序列A的时间为
则输入样本数据矩阵变为
,如公式(9)所示:
(9)
其中,当周边站点
延迟于目标站点S时,
,当周边站点
超前于目标站点S时,
令所有的延迟的最大值为
,所有的超前最大值为
,则得出经由时间序列延迟相关算法筛选得到的输入样本数据矩阵
,如公式(10)所示。
(10)
3) 将数据划分成训练集与测试集,用训练集数据进行模型训练,将训练集数据处理后的输入样本数据矩阵
输入LSTM模型,并对实验结果进行记录与分析。
4) 用测试数据集对模型训练成果进行验证。
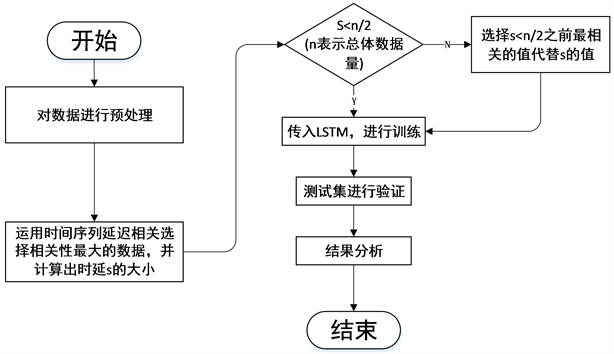
Figure 2. TD-LSTM model flow chart
图2. TD-LSTM模型流程图
3.3. 实验数据选取
本文采用杭州市不同站点的空气质量监测数据作为研究对象,实验采取2019年5月的杭州市各个地区多个站点的臭氧浓度小时监测数据作为实验对象,部分数据样本如表1与表2所示:

Table 1. Hourly data information table of ozone concentration monitored by the station
表1. 站点监测的臭氧浓度小时数据信息表
Table 2. Part of 1229A site monitoring data
表2. 部分1229A站点的监测数据
3.4. 实验结果分析
为了验证本文提出的预测模型的有效性,选取了传统的LSTM模型、SpaceLSTM模型等进行对比实验,三个预测模型都在相同的实验平台和环境下进行实验。本次对每个模型都进行了50次的实验,实验迭代50次,每次迭代结束之后计算均方误差,选取实验结果的平均值作为本文的公布数据,并且画出实验结果图。
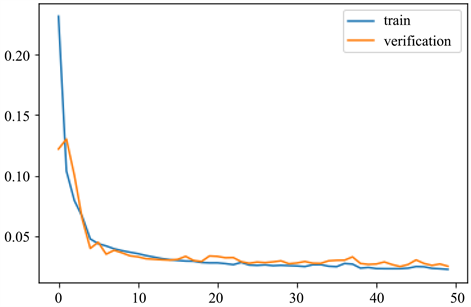
Figure 3. LSTM loss curve after improved delay
图3. 时延改进后的LSTM损失曲线图
图3是本文提出的TD-LSTM模型在训练过程中,训练集和测试集每一步训练结束时训练数据的损失,横坐标表示迭代次数,纵坐标表示损失值,表示对单个样本而言模型的准确程度,损失值越低,表明准确程度越高,可以看出,迭代超过10次以后,模型的损失值可以迅速降低,预测的后期,模型的图像出现上下波动,说明训练已经达到饱和状态,模型基本稳定。
图4是采用TD-LSTM模型的实验过程中,对臭氧浓度的预测值和真实值的对比曲线图,通过曲线的吻合度可以看出,该模型的预测效果比较好,能够很好的跟踪臭氧浓度的变化趋势。根据模型多次实验的结果,可以得出均方根误差的平均值为12.205,相比未改进前的模型,有较好的提升。
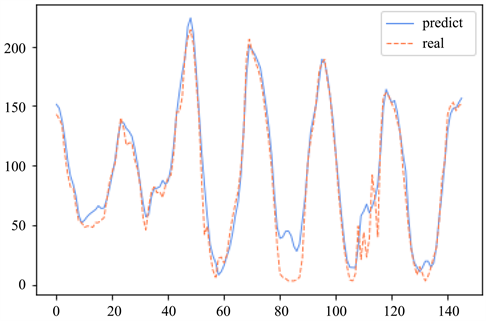
Figure 4. Comparison between predicted and true values
图4. 预测值和真实值的对比图
如图5所示,分别为原始LSTM模型(LSTM)、空间数据LSTM模型(SpaceLSTM)以及TD-LSTM模型的实验对比图,从实验对比图可以看出,时间序列延迟相关改进后的模型与真实值吻合度最高,跟踪臭氧浓度的变化效果也最好。

Figure 5. Comparison of various model experiments
图5. 多种模型实验对比图
从表3的数据可以看出,运用时间序列延迟相关算法改进后的LSTM模型均方误差值最小,表明TD-LSTM模型具有较好的预测精度。
Table 3. Mean mean square error value of ozone (O3) concentration prediction
表3. 臭氧(O3)浓度预测平均均方误差值
4. 结论
本文使用杭州市多个站点臭氧小时监测数据进行臭氧浓度预测。为减少由于量纲造成的误差,首先对臭氧小时监测数据进行max-min归一化处理;然后将各站点臭氧浓度小时监测数据按监测时间的先后转换成时间序列,每个站点数据对应一条时间序列;再运用时间序列延迟相关算法对数据进行处理,得到最大延迟相关的时间序列数据,并将其输入LSTM模型对目标站点的臭氧浓度进行预测。实验结果表明:本文所提模型的预测结果曲线更为平滑且与真实值更加接近,均方根误差和绝对平均误差均为最小,预测效果相较传统的LSTM模型和SpaceLSTM模型更好,可以为臭氧的预警预报提供一定的参考。