1. 引言
商家在原来已有订单基础上,买家又追加订单,就是补单。有时补单也特指因品质异常而不能满足客户要求导致的补单。商家的补单主要与现金流的占用和库存问题等原因有关。商家的补单数量的多少将直接影响客户需求。过于乐观的补单将造成大量的库存,库存的积压带来的不仅是仓储成本的增加,更为严重的是要考虑清仓问题,清库存的方式无非是加大营销力度,以更低的成本清理货物,这时候不仅资金的流转变慢,而且低价的清仓也会拉低品牌溢价,而过于悲观的补单则会导致货不够卖而造成资源的浪费和利润的流失,这又是企业不愿意看到的,所以若能够将商家的日均销售量预测出来,科学的根据企业自身情况合理制定补单模型和计划也显得尤为重要,这也将极大地减少商家的流动资金占用、库存压力及仓储成本问题。
2. 数据来源与模型假设
本文选取某厂家2018年7月~2019年3月的销售量数据作为研究对象,数据来源于2019年第12届华中地区数学建模邀请赛。为简化建模过程,本文做出以下假设:
假设题目所给未指定日期的销售量都为零;
假设问题所给数据真实可靠,并且筛选掉的数据不会对本文的研究结论做出影响;
假设未考虑的影响因素不会令模型的预测效果产生大幅度偏差。
3. ARIMA预测模型建立与求解
本文选取基于ARIMA模型的时间序列分析预测 [1] [2] [3] 。ARIMA模型的基本思想 [4] 是首先将非平稳时间序列转化为平稳序列,然后通过对因变量的滞后项和随机误差项进行回归建立预测模型。它的具体形式可以表达成ARIMA (p, d, q),其中:p表示自回归过程的阶数;d表示差分阶数;q表示移动平均过程的阶数。
1) 数据预处理及平稳性检验
我们首先随机选取某一个货号作为研究对象,利用SPSS软件将一该货号的销售量根据日期进行缺失值的填补,然后做出时序图,如图1所示。
根据时序图可知,原始数据并不平稳,因此,对该非平稳时间序列进行数据预处理,采用差分处理方法使序列平稳。首先采用一阶差分,若效果不好,则采用二阶差分,以此类推并观察动态结果,选择出最优差分解,发现当采用一阶差分时序列图再数值0上下波动,符合平稳序列的特点(见图2),因此,我们初步判定差分次数d的值为1。

Figure 1. Sales sequence diagram of a selected article number
图1. 选取某一货号的销售量时序图

Figure 2. First-order difference processing diagram of sales volume data of a certain article number
图2. 某一货号销售量数据的一阶差分处理图
2) 模型识别与定阶
经过处理差分后的数据已具备平稳序列的要求,接着,再根据ARIMA相关性的特征,读取平稳时间序列差分后的自相关图和偏自相关图初步识别p、q值。图3中ACF第一阶后呈截尾状,PACF第四阶后呈拖尾状,因此可初步判断差分后序列适合ARIMA (3, 1, 3)模型。

Figure 3. ACF diagram and APCF diagram after sequence difference
图3. 序列差分后的ACF图和APCF图
重复拟合ARIMA (p, d, q)模型中p和q的各种取值,并计算相应参数对应的显著性Sig.、R的平方来初步判定模型的最佳结束,计算结果见表1。

Table 1. Test results of fitting model for each parameter in ARIMA model
表1. ARIMA模型中各参数的拟合模型检验结果
观察表中的观测值,综合比较表中的各个指标,表中参数(3, 3)对应的相关系数R的平方最大,且显著性水平Sig.大于0.05,对参数(3, 1, 3)作模型拟合效果图(如图4所示),观察实际拟合效果较好,因此,本实验选中ARIMA模型的参数估计为p = 3,d = 1,q = 3。
3) ARIMA模型预测
根据上述得出的ARIMA模型,其R的平方为0.484 (如图5所示),达到的拟合程度较好,AR,MA的系数分别是0.065和0.503。因此,我们认为得到ARIMA模型结果为:
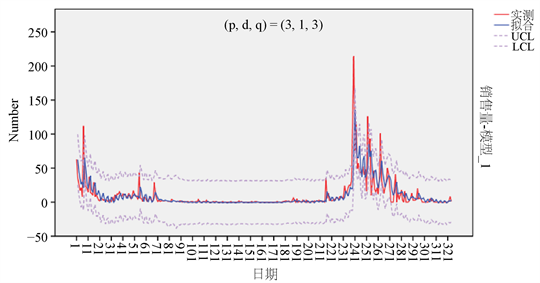
Figure 4. Model fitting diagram corresponding to ARIMA model parameters (3, 1, 3)
图4. ARIMA模型参数(3, 1, 3)对应的模型拟合图

Figure 5. ARIMA (3, 1, 3) model fitting results
图5. ARIMA (3, 1, 3)模型拟合结果
我们选近5天的销售量作为预测目标,首先在SPSS中增加5个自变量,采用预测建模方程,得到分析结果如图6所示,由此,我们可以得出结论:未来5天的货物销量分别为:3,3,2,2,3。
4. 马尔可夫预测模型的建立
马尔可夫模型是一种常见的简单随机过程,该过程是研究一个系统的状况及其转移的理论。它通过对不同状态的初始概率以及状态之间的转移概率来研究,来确定状态的变化趋势,从而达到对未来进行预测的目的 [5] 。
1) 马氏性检验
将某一货号销售量进行等级划分假设。设销售量为t。当
时,认为销量很差;当
时,认为销量较差;当
时,认为销量一般;当
时,认为销量较好;当
时,认为销量很好。由此可以将销售量划分为5个状态等级,如表2所示。

Figure 6. Sales volume forecast by ARIMA model for the next 5 days
图6. ARIMA模型预测未来5天的销售量图
Table 2. Sales grade status division
表2. 销售量等级状态划分
由此计算出初始概率,可得:
系统在时刻t从状态m出发,经过i步后处于状态n的概率为状态转移概率,其中一步转移后形成的矩阵称为一步转移概率矩阵。各步转移概率为:
经Matlab检验,给定显著水平
,
,可认为序列符合马氏
性,因此,可对该序列用马尔科夫模型。接下来可利用马尔科夫模型进行预测工作。(Matlab程序见附录三)
2) 马尔可夫模型预测及分析
首先计算各阶段自相关系数及权重。采用自相关系数作为相依关系强弱的度量,第s步的自相关系数为:
由此求得序列各阶自相关系数
。
将自相关系数规范化可得各步马尔科夫的权重:
计算出的权重为
因此,根据以上数据可预测得到未来5天的销售状态等级:
Table 3. 2018/12/08 sales grade forecast
表3. 2018/12/08销售等级预测
由表3可知,2018/12/08销售量为状态1的概率最大,故符合我们ARIMA模型预测结果。经过同样计算验证,得出2018/12/09至2018/12/12销售状态等级也为1,符合ARIMA模型估计。
5. 模型检验
对ARIMA模型的参数p = 3,d = 1,q = 3进行残差分析检验,图7中可以看出残差图基本上都是平稳的,且预测出的观测值基本都在预测值的预测区间之内(见图8),因此,我们认为ARIMA (3, 1, 3)模型是合理的,且判定其拟合效果较好。

Figure 7. ACF and PACF diagrams of model residuals of ARIMA (3, 1, 3)
图7. ARIMA (3, 1, 3)模型残差的ACF和PACF图

Figure 8. Prediction fitting effect of ARIMA (3, 1, 3) model
图8. ARIMA (3, 1, 3)模型的预测拟合效果图
6. 结论
本文通过运用ARIMA模型对某厂家的销售量进行预测,同时采用马尔科夫模型进行检验,两种模型相结合,结果基本相一致,且所达到的预测结果较好。该文提出的预测结果也将有利于相关厂家指定相关的补单和存货方案来应对不同的订单问题所带来的后果,做到防患于未然。但本文目前所提出的两种销量预测模型仍有一些地方需要进一步改进,以提高预测的准确度与稳定性。
附录
马尔可夫预测matlab程序:
clc
clear
a=xlsread('code.xlsx');
E=a(:,4)';
fori=1:5
forj=1:5
a1=0;
a2=0;
a3=0;
a4=0;
a5=0;
forn=1:272
ifE(n)==i
ifE(n+1)==j
a1=a1+1;
end
end
f1(i,j)=a1;
end
forn=1:271
ifE(n)==i
ifE(n+2)==j
a2=a2+1;
end
end
f2(i,j)=a2;
end
forn=1:270
ifE(n)==i
ifE(n+3)==j
a3=a3+1;
end
end
f3(i,j)=a3;
end
forn=1:269
ifE(n)==i
ifE(n+4)==j
a4=a4+1;
end
end
f4(i,j)=a4;
end
forn=1:268
ifE(n)==i
ifE(n+5)==j
a5=a5+1;
end
end
f5(i,j)=a5;
end
end
end
f1
fori=1:5
forj=1:5
p1(i,j)=f1(i,j)/sum(f1(i,:));
p2(i,j)=f2(i,j)/sum(f2(i,:));
p3(i,j)=f3(i,j)/sum(f3(i,:));
p4(i,j)=f4(i,j)/sum(f4(i,:));
p5(i,j)=f5(i,j)/sum(f5(i,:));
end
end
p1,p2,p3,p4,p5
forn=1:5
a1=0;
a2=0;
fori=1:5
a1=a1+f1(i,n);
forj=1:5
a2=a2+f1(i,j);
end
end
S(n)=a1/a2;
end
S
fori=1:5
forj=1:5
x_tjl(i,j)=2*f1(i,j)*abs(log(p1(i,j))-log(S(j)));
end
end
x_tjl(4,4)=0
x_tjl=sum(x_tjl(:));
x_bzl=32;
ifx_tjl>x_bzl
disp('该序列符合马氏性')
elsex_tjl
disp('不能对该序列用马尔科夫模型')
end
E_jun=sum(E(1,:))/length(E);
forn=1:5
a1=0;
a2=0;
fort=1:(length(E)-n)
a1=a1+(E(t)-E_jun)*(E(t+n)-E_jun);
a2=a2+(E(t)-E_jun)^2;
end
r(n)=a1/a2;
end
r
forn=1:5
a3=0;
fort=1:5
a3=a3+r(t);
end
w(n)=r(n)/a3;
end
w
k=325
K(1,:)=p5(E(k-5),:);
K(2,:)=p4(E(k-4),:);
K(3,:)=p3(E(k-3),:);
K(4,:)=p2(E(k-2),:);
K(5,:)=p1(E(k-1),:);
K
fori=1:5
a1=0;
forj=1:5
a1=a1+K(j,i)*w(6-j);
end
P(i)=a1;
end
P