1. 引言
建筑物作为一种重要的地理空间信息要素,是人们主要的活动场所,在城市规划与建设、居住环境、交通管理、房地产以及灾害损失评估等领域占有极为重要的地位 [1] [2] 。车载激光扫描系统能够在高速移动状态下获取道路及两侧建筑物、树木等地物表面的三维激光点云,含有空间三维几何信息和激光强度信息,内容丰富、点位精度高,已成为空间数据快速获取的一种重要手段 [3] 。利用三维激光点云分割分类技术,从中提取和识别建筑物等各类地物目标,是国内外众多学者研究的方向,也是城市场景三维重建、各领域应用需求的技术前提 [4] 。但激光点云数据采集成本相对较高,数据量大,处理起来比较耗时,缺乏属性、语义信息,且具有不连续性和不完整性。随着无人驾驶的蓬勃发展,能获取的MLS点云数据量会越来越大,实现高效、高精度的建筑物目标提取是激光点云信息挖掘的必然要求。
对于激光点云数据中的多目标提取,其中包括建筑物立面提取,有一类方法是先对点云数据进行分割。因此国内外学者对点云数据分割做了大量的研究工作,并取得了一定的研究成果。T. Varady等最早给出了点云分割的定义 [5] :点云数据分割就是要将整幅点云分割为多个子区域,每个区域对应于一个自然表面,并且要保证每个子区域只包含采集自某一特定自然曲面上的扫描点。文献 [6] 采用RANSAC算法对建筑物点云进行分割,该算法对数据要求较为严格,且仅能有效提取垂直于地面的平面建筑物点云,无法提取复杂建筑物立面。文献 [7] 利用生成的点云特征图像,采用阈值分割、轮廓提取与跟踪等手段提取图像分割的建筑物目标的边界,从而确定边界内部点云数据,实现快速目标分类与提取,但由于只使用高度信息,低矮墙面容易被漏提,建筑物附近高度相当的树木容易被错分。文献 [8] 通过生成点云深度图像,将最优分割的寻找问题转化为蚁群的最优路径寻找问题,可以实现较为复杂建筑物的提取,但由于遮挡问题,需要进行错误点剔除工作,也就是位于建筑物前方的树木、街灯、行人、停靠车辆等遮挡物剔除。文献 [9] 同样利用点云生成特征图像,然后基于支持向量机(Support Vector Machine, SVM)对建筑物立面网格进行粗提取,最后使用网格属性(形状系数、网格面积、最大高程)对粗提取结果进行过滤,可有效避免文献 [7] 中存在的问题,但是该算法仅在较为规则的建筑物立面提取上结果有效。文献 [10] 通过法向量和距离约束对点云进行分割,然后利用建筑物立面的几何先验知识进行特征提取,建筑立面的提取效果取决于分割效果的好坏,分割效果需要反复尝试才能确定最优的分割参数。文献 [11] [12] 首先利用“维数特征”方法确定每个扫描点的最佳邻域,进而计算得到每个扫描点精确的局部几何特征(法向量、主方向、维数特征),然后基于“维数特征”对扫描点进行粗分类,并设置相应的生长准则对不同类别的扫描数据分别进行分割,最后实现了对建筑物立面区域进行精确提取,并且可提取较复杂的建筑物立面,但是计算量较大。综上,目前直接对车载点云建筑物提取方法存在的主要问题是:1)地物遮挡及先验知识不足导致的错分漏提;2)大数据量特征计算和聚类的计算导致计算复杂度高、耗时长。
随着传感器、物联网与云计算的快速发展,志愿者地理信息(Volunteered Geographic Information, VGI),又称众源地理数据,不断兴起,其中影响力较大的主要有Open Street Map (OSM),Waze,Wikimapia,Google Map Maker,Foursquare,以及国内的新浪微博、大众点评等社交与生活服务类网站 [13] 。与传统地理信息采集和更新方式相比,众源地理空间数据内容丰富,可表达元素拓扑关系,更新速度快,具有丰富的属性和语义信息,成本低廉、可免费获取和使用,成为近年来国际地理信息科学领域的研究热点。虽然目前常见的VGI数据缺乏三维信息,并不能全面表达地物信息,但建筑物目标在OSM数据中,具有明确的位置和完整的轮廓范围,MLS数据也具有相应的位置信息,理论上可与其建立起对应关系。因此融合OSM数据和LiDAR点云数据进行建筑物目标的提取,可以实现优势互补,建立位置精准、关系正确、几何细节和属性信息丰富,方便快速更新的城市三维模型,为后续应用提供数据支撑。因此本文提出融合这两种数据的建筑物提取方法,流程如下图1所示。
2. OSM数据和MLS数据预处理
VGI数据大部分来自于没有经验的非专业人士,数据采集设备精度不一,且创建编辑过程中所用用比例尺也有所差别,具有数据质量各异、分布不均匀、冗余而又不完整、缺少统一规范等问题 [14] [15] [16] 。VGI数据中影响最大、意义深远的数据平台是Open Street Map (简称OSM),OSM试图通过志愿者的努力建立一个公共版权的世界范围的街区图,供大众免费使用。下图2是本文对OSM及MLS数据的预处理过程。
由于OSM数据质量不具有全局一致性,但在一定范围内的质量差异可以忽略,因此对于大范围的MLS数据,本文采取按轨迹长度分段处理。基于当前MLS数据的空间范围,可从Open Street Map网站直接获取最新的OSM数据,该数据为XML格式,通过相互关联的几何要素(Nodes, Ways, Relations)和属性要素(tags)来描述地面实体目标,采用的是WGS84椭球参考系,无投影坐标系。本文先利用空间数据转换处理系统Feature Manipulate Engine,简称FME,将OSM数据转换为shape格式的二维矢量地图数据后,再统一OSM-shp数据与MLS数据的地理参考系,最后分别根据MLS数据的采集轨迹信息和OSM属性数据中的“building”关键字选取关键OSM路网和建筑物polygon,用于后续操作。
3. OSM数据和MLS数据的联合处理方法
3.1. OSM与MLS的叠加
众源地理数据形式是二维矢量地图数据,具有对象化的特性和复杂的拓扑关系,而三维激光点云是一系列带有三维信息和强度信息的离散点集,无对象化的概念,这种二维与三维数据的配准存在一定难度。又由于第2章所述众源数据存在的问题,使得OSM数据和点云数据的配准精度难以保证。经过数据预处理工作,OSM和MLS数据已处于相同的地理参考之下,但由于投影变换是由控制点近似或统一参数求得,在考虑到OSM数据与MLS数据的绝对定位误差的前提下,仍需要在提取区域内进行局部的精
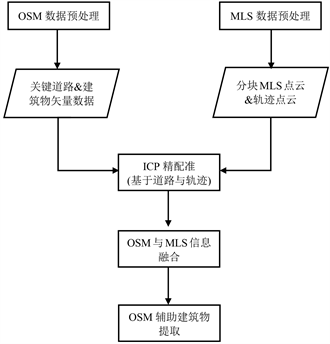
Figure 1. Framework of the proposed method
图1. 方法流程图
细配准。因此文本结合研究目标,根据实际需求,将配准问题适当简化,提出适用于当下研究问题的配准方法,即转化为MLS轨迹点集与OSM道路点集的二维配准问题。
OSM数据提供了建筑物的粗略边界轮廓,为确定OSM数据与点云数据中建筑物立面的对应关系,本文利用MLS的轨迹数据建立OSM数据与MLS数据的正确叠加,并利用迭代最近邻点算法(Iterative Closest Point,简称ICP)求得两份数据之间的变换参数。经典的ICP算法的目标函数为:
(1)
(2)
其中,k是匹配点的数量;mi为目标点ni为匹配点;R和T为变换参数,在本文中由于是二维的位姿变换,所以R为θ构成的旋转矩阵,T为x和y坐标的偏移量。但轨迹和路网之间的匹配,利用点到点之间的关系建立变换并不精确。一方面采样函数无法保证在两种轨迹相同的位置进行采样;另一方面点到点的ICP算法并没有用到轨迹之间节点的相关性。所以本文采用了基于点到线距离约束的ICP版本,算法流程图如下图3所示。
首先,为参考点集构建搜索树,此处的参考点集为车载数据轨迹点。接着针对每一个待配准点集内的点,搜索在参考点集对应的线段,由最近邻点及其上/下一点构成。然后对每一个匹配点线建立约束方程,最终利用Levenberg-Marquardt算法 [17] 对目标函数进行求解。点到线的ICP目标函数建模如下:

Figure 3. Flow diagram of ICP registration
图3. ICP配准流程图
(3)
构建约束方程的Jacobian矩阵并利用LM算法进行求解。LM算法的迭代形式如下式。迭代收敛后,利用得到的变换参数对OSM的建筑物矢量数据进行变换。
(4)
MLS 轨迹点集与 OSM 道路点集的二维配准结果如图4所示。
3.2. OSM数据辅助建筑物提取
众源地理数据具有几何信息和语义信息,理论上可以从空间上和语义上为激光点云分割分类、目标提取提供先验知识,且在建立匹配关系之后,可将其语义信息赋给点云,最终得到具有丰富语义信息的三维模型。对于有明确范围的建筑物目标来说,可以在点云数据中得到其候选区域,代替直接从数据量巨大的三维点云中提取,可极大地缩小其搜索范围。
对存在误差的两种数据源进行信息融合,为了的到更加准确可靠的结果,本文采用贝叶斯信息融合方法,利用概率的方法对两种数据源进行建模和融合。首先本文利用OSM数据与LiDAR数据初步融合给出似然概率。顾及到OSM数据本身的误差,在融合时设置了两重缓冲区,作为建筑物点云的候选区域。在第一重缓冲区范围内,认为其概率与OSM图斑内一致,在第二重缓冲区内其概率随距离的增大递减,这里的概率为先验概率,公式如下:
(5)
 (a)配准前
(a)配准前 (b)配准后
(b)配准后
Figure 4. Comparision of before and after ICP registration—the red points are of MLS trajectory
图4. OSM数据配准前后对比——红色为MLS轨迹点
其中d定义为点云到OSM图斑的距离,在图斑内时该值为0,BOSM定义为由OSM数据所推测点属于建筑物。
然后是建筑物提取,本文用的是组合基于点特征、对象特征和基于规则的分类方法并利用先验知识设计多层次策略进行分割分类的针对建筑物的提取方法 [12] 。其流程如下图5所示,首先去除地面点,利用文献 [18] 中提到的方法,去除道路,人行道和其他地面数据;然后利用无监督学习方法对非地面点云构建多尺度超体素模型;再以超体素模型为基础,对场景进行分割;接着计算每一个分割对象的显著性测度;最后通过设计面向城市场景语义知识的分割分类规则实现建筑物的提取。
最后,将得到的建筑物点赋予初始概率0.9,再以数据点的概率进行邻域平滑。最后利用贝叶斯公式融合两者,由于两种概率的获取方式相互独立,故有如下公式:
(6)
其中A定义为假设点属于建筑物,BEXT定义为由3.1方法所推测点属于建筑物。
4. 实验与分析
实验中MLS数据采用Paris-Lille-3D benchmark [19] ,该数据的地理参考为:WGS84椭球坐标系和Lambert RGF93投影坐标系,具体信息描述见表1。LiDAR数据带有轨迹数据,并已按车载轨迹分段。
本文取了两块实验区域(Lille2和Paris部分区域),分别利用文献 [12] 中提到的建筑物提取方法(Yang et al., 2015)以及本文提出的利用OSM数据辅助建筑物提取的方法对实验区域做了建筑物提取实验。并记录了各实验数据集对照组和实验组的时间效率,精确度(Precision),准确率(Accuracy),召回率(Recall),交并比(IoU),见下表2、表3各项指标的计算公式如下:

Figure 5. Flow diagram of building extraction method
图5. 建筑物提取方法流程

Table 1. The information of MLS dateset
表1. MLS数据集描述信息
Table 2. Result of building extraction for Lille 2 dataset
表2. Lille 2数据实验结果评价指标对比
Table 3. Result of building extraction for Paris dataset
表3. Paris数据实验结果评价指标对比
FN: False Negative,被判定为非建筑物点,但事实上是建筑物点。
FP: False Positive,被判定为建筑物点,但事实上是非建筑物点。
TN: True Negative,被判定为非建筑物点,事实上也是非建筑物点。
TP: True Positive,被判定为建筑物点,事实上也是建筑物点。
从Lille 2数据集中分别截取三块区域(如上图6所标记)的提取结果,如下图7~图9所示。其中图8、9分别为本文方法所避免的误提取和漏提取现象的两个个示例。
Lille 2数据的非地面点中,建筑物点占52%,道路两侧均有建筑物及低矮植被分布,路面上有汽车停靠,还有部分形态类似于建筑物立面的篱笆等地物分布。由表2,本文方法相比于Yang et al., 2015方法:处理时间减少了约50%,由于本文方法利用配准后的VGI数据,有效提供了建筑物候选区域,因而减少了近50%的数据处理量;精确度提升了3%、准确率提升了2%、交并比提升了2%,这是由于数据中的篱笆(如图7)和部分汽车(如图8)等被Yang et al.方法误提取,而本文方法有效避免了这类现象,使得FP数下降;召回率提升了0.3%,这是由于实验区域在Open Street Map上的数据比较完备,且因为使用了贝叶斯信息融合的方法避免了少量如图9所示的漏提取问题,在此基础上,也很好地验证了本文方法对建筑物提取有效,即在提高效率的同时,也较好地避免了误提取问题,并对漏提取问题有所改善。
Paris数据的非地面点中,建筑物点占36%,道路一侧主要分布着建筑物,另一侧主要是排列整齐的行道树,场景较为简单(如图10所示)。由表3,本文方法相比于Yang et al., 2015方法:处理时间减少了约93%,效果显著,一方面由于该数据建筑物密度较小,用本文方法大大减少了处理数据量,另一方面由于该数据场景较为简单,各建筑物之间分隔明显,采用了分治策略,使得效率更高;精确度提升了16%、准确率提升了7%、交并比提升了15%,同理,主要是由于现有方法将道路另一侧的行道树误提取(如图11),且行道树点约占非地面点的18%,而本文有效避免了此问题的发生,所以效果提升明显;召回率几乎没有下降,再次验证了上述方法的有效性。

Figure 6. Original Lille 2 dataset (Colorized by height)
图6. Lille 2原始数据-按高程赋色
 (a)真值
(a)真值  (b)本文方法
(b)本文方法  (c) Yang et al., 2015方法
(c) Yang et al., 2015方法
Figure 7. Example 1: result of Lille 2 dataset (Colorized by height)
图7. Lille 2数据集示例1:提取结果(按高程赋色)

Figure 8. Example 2: result of Yang’s method in Lille 2 dataset (Colorized by height)
图8. Lille 2数据集示例2:Yang et al.方法提取结果(按高程赋色)。说明:此处为篱笆,为Yang et al.方法的误提取,本文方法未出现此结果。
 (a)真值
(a)真值 (b)本文方法
(b)本文方法
Figure 9. Example 3: result of Lille 2 dataset (Colorized by height)
图9. Lille 2数据集示例3:本文方法提取结果(按高程赋色)。说明:此处Yang et al., 2015方法漏提取,所以无图。

Figure 10. Original Paris dataset (Colorized by height)
图10. Paris原始数据(按高程赋色)
 (a)真值
(a)真值  (b)本文方法
(b)本文方法 (c) Yang et al., 2015方法
(c) Yang et al., 2015方法
Figure 11. Result of Lille 2 dataset (Colorized by height)
图11. Paris数据集提取结果对比(按高程赋色)
总体而言,经实验验证:本文方法在时间效率上有较大提升,且提升效果跟场景内的建筑物密度成反比;当OSM数据较为完备的情况下,该方法在保证召回率不受影响的基础上,能有效避免误提取和漏提取的问题,从而提升分类的精确度、准确率及交并比。
5. 结论
本文提出了一套融合OSM数据和MLS点云建筑物快速提取的方法流程,选取较好的现有建筑物提取方法进行了对照实验验证。实验结果表明,通过OSM数据的辅助,大大提高了现有点云建筑物提取方法的效率和精度,尤其适用于建筑物密度较小的场景,可以实现三维建筑物点云的快速提取,为建立位置精准、关系正确、几何细节和属性信息丰富(例如:POI信息,建筑物用途等)的城市三维模型,及后续应用提供了有效的数据支撑。而且,本文方法可以有效改善现有方法的误提取问题,避免形态近似于建筑物的其他地物的影响。但是,该方法对OSM数据的完整度和精确度有一定的依赖性,在OSM数据缺失的情况下可能会导致漏提取问题。
NOTES
*通讯作者。