1. 概述
在自动化工业分拣过程中,图像的匹配是非常重要的一环,要求一定的实时性和很高的准确率。在目前的工业分拣中,常采用模板匹配的方法。但是工件的平移和旋转等位置的不确定性给模板匹配带来了很大的困难。因此,研究一种可以快速准确进行匹配,忽略位置光线带来的干扰的匹配算法是非常的必要的。
国外Bourret采用多尺度算法进行边缘检测和边缘闭合,对获得的边缘特征模拟退火算法极小化分割函数来完成图像的匹配 [1] 。国内梁勇等人使用特征点匹配的方法进行工件的边缘匹配,但由于工件的几何形状简单,特征点的信息不足,常使得匹配的结果不够准确,且该算法只解决了图像的平移问题 [2] 。华中科技大学的张学军在图像匹配过程中采用了支持向量机(SVM)的判决功能,解决了匹配只能用单一特征作为判别条件的缺陷。使用最小二乘支持向量机对已有的数据进行分类训练,然后用训练好的向量机检测目标 [3] 。刘健庄、谢维信等人使用Hausdorff距离作为度量图像相似度的标准,使用遗传算法进行检查,该方法取得了一定的效果但是常规遗传算法的局部寻优效果不好,受参数影响非常大且容易产生早熟情况,且Hausdorff距离的计算时间较长,降低了工件分拣的效率 [4] 。中国科技大学与中科院合肥智能机械研究所合作研究了基于机器视觉的瑕疵工件检测系统 [5] ,该系统采用图像处理及模式匹配的方法识别工件,可以通过与模版对比,识别出做工有瑕疵不能在工业生产中使用的工件,并将其分拣出来,该系统在工业生产线上具有很好的实用性。为了避免参数影响和早熟的情况,该算法采用线性搜索的方法,增加了计算的时间。
本文基于中科大研究的瑕疵工件匹配系统中采用的模板匹配思想基础上提出了一种可忽略工件几何变换的图像识别系统并且改进了线性搜索方法,即利用局部敏感哈希算法对工件图像进行处理,最终可以快速高效的识别匹配工件类型,应用于自动化流水作业中图像处理阶段。在获得了工件图像的特征向量之后,需要提取模板的特征向量进行存储,对采集到的新的工件图像进行迅速的匹配。这里可以使用特征向量之间的欧氏距离作为两个工件的相似性度量,欧氏距离越小则代表两个图片越相似,欧氏距离小于设定的阀值,则代表两工件属于同一类别。而在特征库非常庞大的情况下,为快速有效匹配计算欧氏距离并排序,本文采用局部敏感哈希算法进行相似特征的快速搜索。考虑到本文所使用的特征向量长度仅为8,因此本文用之前提取的特征向量建立了大小为4 * 8的哈希表,即指有四张哈希表,每个表有八个桶。因此,本文主要介绍在提取出特征向量之后进行迅速匹配的方法。
2. 基于局部敏感哈希存储提取的工件图像特征
为方便匹配时可以快速的进行检索,使用哈希算法进行提取的工件图像特征的存储,在获得需要匹配的向量后直接对其进行投影即可找到相似的向量。但是由于传统的哈希算法在投影过后不能保证距离不变,因此需要对传统哈希进行改进,改变其投影的哈希函数,使其投影过后的元素距离不变,也即采用局部敏感哈希算法。为此先给出几个定义:
桶:Hash又被翻译为“散列”,是把任意长度的输入转变为一个固定长度的输出。采取映射的办法。其中映射方法又被称之为散列算法,输出被称为散列值,即桶。
Hash桶的性质:如果两个输入的元素经过映射后所在的桶不同,那么这两个元素一定不相同。而如果映射后在同一桶中,则说明两元素有可能相同但并不是一定相同。
如图1所示,传统哈希算法不具有距离不变性,即经过映射以后,原本距离很近的两个元素可能被分在距离较远的两个桶中,也即映射后桶的距离不能代表原输入的两个元素的距离;而locality-sensitive hashing(局部敏感哈希)简称LSH,则是一种保距算法 [6] 。
若定义
是x,y两元素之间的距离,则LSH的映射算法则需要满足以下两个条件,其中d1,d2是根据实际需要规定的值:
1) 若
,则两元素被映射到同一个桶中的概率,即
的概率至少为p1。
2) 若
,则两元素被映射到同一个桶中的概率,即
的概率至多为p2。
其中,d1是最大的相似距离,与d1的距离越小则映射到同一桶的概率就越大;d2是最小的相似距离,与d2的距离越大则映射到同一桶的概率就越小。
满足上述两个条件的哈希映射函数被称为-sensitive。
3. 工件特征的哈希表的生成
一般在快速寻找元素时会采取哈希算法,但是传统哈希算法并不能解决距离不变的问题,因此本论文采取了保距的局部敏感哈希算法。说明了局部敏感哈希算法的性质,不同的距离度量方法以及其相应的哈希映射函数,然后介绍了哈希表的生成方法和哈希函数族,并提供了在搜索过程中提高容错度与准确度的方法。
本文采用局部敏感哈希算法,建立多个哈希表存放工件模版的特征向量,然后用不同的哈希函数将需要查找的向量投影到不同的表中,再通过对不同桶的与或操作获得最终的相似向量。
图2给出了局部敏感哈希原理,
为其中一个样本,
为另一个样本,将两个样本经hash函数转换为0,1的sim Hash值,最后经汉明码计算,便可以用汉明码衡量两者的相似程度。
提取到的工件特征是一个1*8的向量,随机选取其中的六位,并设定其阀值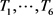 ,若某位的值大于该位阀值,则该位哈希值取1,否则取0。如工件特征向量为
,哈希函数选取其中的第1到6位,阀值设定为
,则其哈希值为001101。选取不同的位数,设定不同的阀值以生成多个哈希表以便提高准确度降低存储空间。
,若某位的值大于该位阀值,则该位哈希值取1,否则取0。如工件特征向量为
,哈希函数选取其中的第1到6位,阀值设定为
,则其哈希值为001101。选取不同的位数,设定不同的阀值以生成多个哈希表以便提高准确度降低存储空间。
图3给出了工件图像进处理的哈希表的生成的几个主要步骤:

Figure 1. Comparison of local sensitive Hash and traditional Hash
图1. 局部敏感哈希与传统哈希比较

Figure 2. The schematic diagram of LSH
图2. 局部敏感哈希原理图

Figure 3. The generation process of Hash table
图3. 哈希表生成过程
其中主要包括保距投影、哈希函数族映射和哈希表。下面分别介绍相应的工作内容。
3.1. 保距投影
本文为了减少存储空间,对哈希函数做了一定的改进。首先对传统的欧式空间进行投影,将其转变为方便比较计算的汉明空间且要求投影过后距离不变。其投影的具体实现方法如下:
对于任意一点
,
,P为d维的原始空间,其投影函数为:
(1)
表示一个由x个1,
个0构成的序列。为了减少存储空间,本文定义
是指当
时,其指为1,反之为0.其中t时根据特征库范围设定的阀值。在投影过后,对于任意两点
,
,dH表示在汉明空间下的两点之间的汉明距离。
汉明距离小的两个向量,在经过汉明距离的哈希映射函数映射过后,映射到同一个桶中的概率更大。而为了增强搜索能力,增大汉明距较小的两个向量的冲突概率,使用多个哈希表。
3.2. 哈希函数和哈希表的形成
接下来需要对获得的汉明空间下的向量进行映射,同样需要保证映射过后在同一桶中的元素其原始数据也是相近的。而且为了增加冲突率提高搜索效率使用多个表相应的也就需要使用多个哈希函数。本文使用的具体哈希函数如下:
对于d维空间,定义
,取L个I的子集,子集的长度相同均为i,分别记为
,定义
是p在I上的投影,也即I中每个数值作为位置索引,取p对应位置的值并串联起来。
对于L个子集,建立L个哈希表。对于
,记
。对汉明空间中的点采用该映射函数映射到不同的桶中。哈希函数族以及其映射结果如表1所示。
4. 工件的图像匹配
在搜索时,可以迅速找出哈希表中与当前工件图像的特征向量欧式距离最短的向量,进而得到工件的类型,对工件进行快速的分类。

Table 1. Hash function and Hash table
表1. 哈希函数与映射后的哈希表

Figure 4. The flow chart of image matching
图4. 图像匹配流程图
图像匹配过程即寻找与该特征向量距离最为相近的向量,然后获得其图像信息。具体的匹配步骤如图4所示。
4.1. 与或操作
在经过哈希函数族进行映射以后,会获得几个表中桶的编号,根据桶中的元素数量,以及为了保证投影过后元素的邻近概率和错误率,本文采取与、或操作进行平衡,具体做法如下:
1) 与操作
从哈希函数族中挑出k个哈希映射函数,当且仅当k个
均成立时,才会被投影到相同的桶内。这种操作大幅度降低了分配在同一桶中但向量不邻近的概率,但是一定程度上降低了找到邻近数据的概率。
2) 或操作
从哈希函数族中挑出k个哈希映射函数,只要在k个
中有一个成立,就会被投影到相同的桶内。这种操作一定程度上提高了找到邻近数据的概率,但是也在一定程度上提高了分配在同一桶中但向量不邻近的概率
4.2. 桶内排序
桶内排序即对距离进行排序。距离是用来度量两个向量之间相似度的参数,距离越大则相似度越低,距离越小则相似度越高。而向量的距离之间有不同的表示方法,具体有以下几种:
1) jaccard距离
jaccard相似度是指两集合交集的元素个数比上两集合并集的元素个数,具体公式如下:
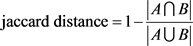 (2)
(2)
2) 夹角距离
夹角距离指两个向量之间的夹角越小则表示其距离越近。也可以理解为使用了一个随机的超平面对原始的数据空间进行划分,而每个数据在被投影后都会落到超频面的某一侧,认为投影后落在同侧的数据有很大可能是相邻的,也即原始数据之间的夹角很小。
3) 欧几里得距离
欧几里得距离又称欧氏距离,是常用的衡量D维空间内两个点之间的距离的方式,其表达式为:
 (3)
(3)
考虑到算法的时间复杂度以及精确度,本文选择欧几里得距离作为向量之间相似度的度量。
5. 主要函数的实现
本文哈希表的生成涉及到以下几个主要函数:
1) lsh函数,用户调用该函数,并传入哈希表中表的个数l和桶的个数k以及原始数据空间的维数d和原始数据varagin便可以得到映射过后的哈希表
2) lshfunc函数,创造随机的哈希函数族,在lsh函数中被调用。
3) lshprep函数,创建l个哈希表,被给每个哈希表设置其哈希函数。
4) lshins函数,在lsh函数中被调用,将原始数据通过上述lshfunc函数获得的哈希函数族映射到哈希表中。且为了减少占用的内存,这里表中并不存储特征向量,只存储特征向量在向量库中的索引值。
5) lshlookup函数是局部敏感哈希的查询代码,其中传入参数temp_T是当前工件的特征向量,Patches是模板特征库,T1是已经建立好的哈希表,函数可以返回与temp_T投影在同一桶中的特征向量的个数,以及其在特征库中的索引。
6) lsh (l, k, d, x, varargin)函数调用lshfunc生成函数族,然后使用lshprep创建哈希表,调用lshins进行投影,其核心代码较为简单,这里不做赘述。
7) lshfunc函数,按照用户传入的桶的个数随机选取几个维度,给这些维度设置一个阀值t,hash函数为x(d) ≥ t。
其中,lshins函数作为映射函数非常重要,传入参数为lshprep已创建好的哈希表和原始数据,由于函数只给数据创建索引但不存储,因此原始数据不能删除以便后期追溯。该函数的流程图如图5所示。
6. 实验测试
6.1. 图像匹配
本文算法的实现是基于MATLAB进行开发的。本文共采集了100种工件的模板,建立了4 * 8的哈希表,并对这些工件做出一些几何变换如平移、缩放、旋转等,对新产生的工件进行搜索匹配,观察是否能准确的对工件进行分类。
本文采用canny算法提取工件检索数据库(如图6)中的每个工件的轮廓,然后选择其中一种工件,利用图像的仿色变换得到处理后的扭曲工件边缘(如图7所示);将扭曲的工件边缘图像重新放到数据库中。图6右下角的图片就是提取的钥匙轮廓。
最后利用LSH算法在数据库检索选择的图像,其中LSH算法测试的核心部分如下:

LSH检索器得出的检索结果如图8所示。即选择图7仿射变换后的工件轮廓为测试集,通过LSH算
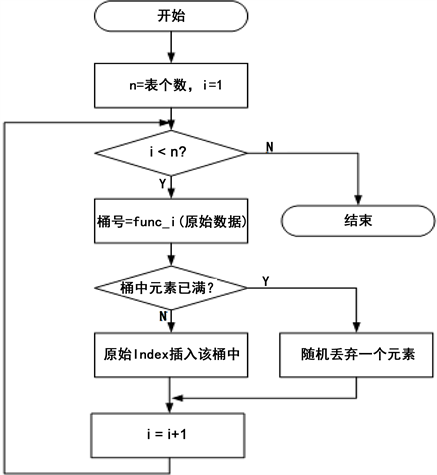
Figure 5. The flow chart of lshins function.
图5. lshins函数流程图
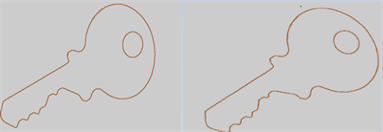
Figure 7. The Edge of the original workpiece and the one after affine transformation.
图7. 原始工件轮廓与仿射变换后的工件轮廓

Figure 8. The retrieval result of LSH
图8. LSH得到的检索结果
法得到检索集内的原始工件轮廓。
为了更进一步地检验改进的LSH检索器的检索效果,本文采用了Cross –Correlation的相关性计算方法,计算公式如下:
(4)
其中,mx为工件轮廓x坐标和的平均值,my为工件轮廓y坐标和的平均值。
通过9次轮廓迭代检测和相关度检测实验,可以得出改进后的LSH检索器的检索工件相关度为93.6%,测试结果如图9所示。
6.2. 特征存储
在系统运行之前,先调用SAVE函数采集100张图片的特征向量,每个工件图像提取其36个不同方向上的特征向量,生成一个大小为3600 * 8的模板特征库,之后运行系统。在系统界面生成过程中,预先加载了特征向量库并且对其进行投影映射生成4 * 8的哈希表以便后期使用。在openbutton_Callback函数中,调用文件系统打开图像文件,由用户选择需要匹配的工件图像,显示该图像并提取图像的特征向量。在searchbutton_Callback函数中,对该特征向量进行映射,然后提取出在同一桶内的特征向量,计算出其欧氏距离最短的一个,然后显示该图片。系统的整体运作流程如图10所示。
7. 实验结果
采用工业生产中不同形状的钥匙以及齿轮作为特征库,对工件图像进行匹配分类,当工件发生位移时、旋转时和缩放时进行匹配。实验表明,本系统可以有效的解决图像的几何变换,对于平移、旋转、缩放过后的工件图像均有较好的识别效果,且搜索速度大幅提升。而对于模板中没有的工件,则在搜索中可能不能找出其视觉上相似的图片。在实际工件流水线中,需要耗时的步骤有提取当前工件图像的特征向量和搜索图像,由于边缘方向直方图的计算量较大,特征向量提取约需要1 ms,搜索时间仅需0.05 ms,能够有效应用于实际生产当中。
8. 结论
本文基于边缘方向直方图作为工件特征向量,采取局部敏感哈希算法匹配图像,相对于传统的哈希,此算法既可以迅速的找到目标所在的位置,又保证了投影过后位置相邻的元素其原始数据也非常相近。正好满足图像匹配的需要,而且耗时很短。
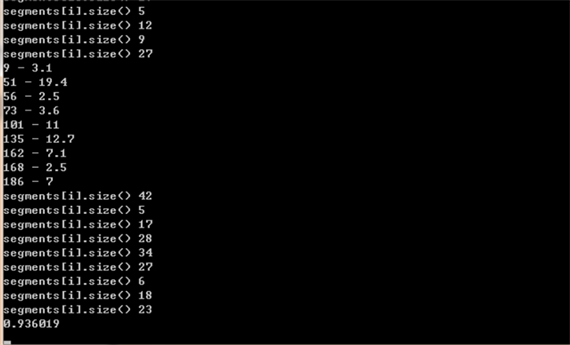
Figure 9. The correlation of real workpiece edge map and the one retrieved by LSH method
图9. 测试工件轮廓与LSH检索轮廓的相关度测试
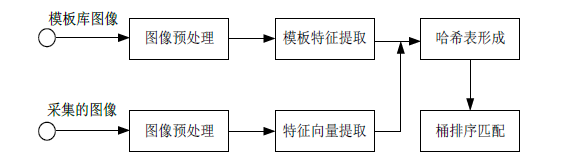
Figure 10. The overall flow chart of this retrieval system
图10. 系统整体流程图
本文有效解决了在实际操作中工件位置变化和光线不同等情况给识别带来的困难,提高了搜索的速度,但是还存在一些不足,比如:在局部敏感哈希算法中对模板进行投影时,如果一个桶中的元素数已经满了,本文采取了随机抛弃一个元素的做法,对结果造成了一定的误差。可以尝试采取二级哈希表的做法,也即在桶满了以后,在桶中占用一个元素的位置另建一个桶。此外,本文仅考虑了对图像匹配速度要求不是很高但对精度要求非常高的情况,对于另外一种情况,即需要较快的识别速度,且只需要对工件大类进行分拣的情况,可以使用边缘特征点运行机器学习算法,这种方法可以大大提高匹配速度,且在数据比较多的时候,精准度也会有所提高。
基金项目
16ZXHLGX00250、15ZXHLGX00360、15ZXHLGX00380、15ZXDSGX00090。