1. 引言
公路运输是国民经济的基础性和服务性产业,是合理配置资源、提高经济运行质量和效率的重要基础,具有基础性和先导性的作用。客运量是衡量公路运输发展程度的重要指标,可用于反映社会经济发展现状和人民生活水平。目前,客运量预测方法已达300多种,归纳起来大体分为定性预测和定量预测两类。常用的定量预测方法有指数平滑法、回归分析法、弹性系数法、灰色系统法、组合法等;定性预测方法有运输市场调查法、德尔菲法和类推法等 [1] 。
本文主要采用回归分析法对公路客运量进行回归分析和预测。世界上任何事物的产生和发展都是由一定的原因引出一定的结果。当一个变量(因变量)同其它一些因素(自变量)之间存在着某种因果关系的时候,我们就可以按照一定的方式建立反映这些关系的数学模型,然后根据自变量在未来的变化来计算因变量的变化,这就是因果关系预测。建立因果关系预测常采用的方法就是回归分析法,该方法是利用过去的历史资料,从中分析找出事物发展的内在联系,确定事物的自变量和应变量,以及它们之间的相关关系,建立数学方程式,一般称其为回归方程 [2] 。
2. 变量的选取
公路客运量主要受到经济发展水平、经济结构、人口及其构成、居民收入与消费水平、旅游业发展状况、运输网络结构等因素的影响。本文主要选取总人口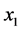 、国内生产总值
、国内生产总值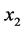 、工农业总产值
、工农业总产值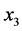 、民用载客汽车拥有量
、民用载客汽车拥有量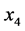 作为自变量,公路客运量
作为自变量,公路客运量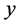 作为因变量建立模型。
作为因变量建立模型。
3. 数据
1981~2015年我国公路客运量、总人口、国内生产总值、工农业总产值、民用载客汽车拥有量数据见表1。
4. 公路客运量与各自变量的多元回归模型
社会经济现象是复杂的,通常一种社会经济现象与许多种现象相联系。一种社会经济现象与多种现象相联系的最简单形式,是一个被解释变量与多个解释变量的线性关系 [3] [4] 。

Table 1. Data of highway passenger volume, total population and gross domestic product, gross output value of industry and agriculture, civil passenger car ownership in 1981-2015
表1. 1981~2015年我国公路客运量、总人口、国内生产总值、工农业总产值、民用载客汽车拥有量数据
注:本表数据来自于《中国统计年鉴》,Wind资讯
基本原理:多元线性回归原理 [5] 。
设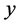 是一个可观测的随机变量,它受到
是一个可观测的随机变量,它受到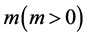 个随机变量因素
个随机变量因素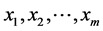 和随机误差
和随机误差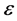 的影响。若
的影响。若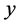 与
与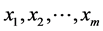 有如下线性关系:
有如下线性关系:
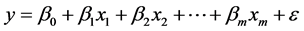 (1)
(1)
该模型即为多元线性回归模型,其中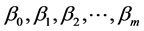 是固定的未知参数,称为回归系数;
是固定的未知参数,称为回归系数;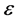 是均值为0、方差为
是均值为0、方差为 的随机变量;
的随机变量;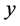 称为被解释变量;
称为被解释变量;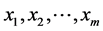 被称为解释变量。
被称为解释变量。
对于总体 的n组观测值
的n组观测值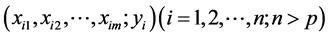 应满足上述线性关系,即
应满足上述线性关系,即
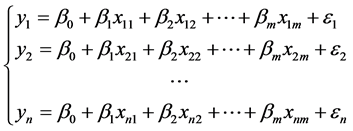 (2)
(2)
其中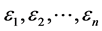 相互独立,且设
相互独立,且设 ,记
,记
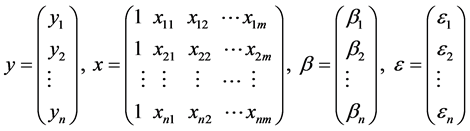
则可用矩阵形式表示为 [6] :
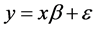
其中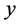 称为观测向量;
称为观测向量;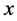 称为设计矩阵;
称为设计矩阵;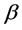 称为待估计向量;
称为待估计向量;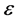 是不可观测的n维随机向量,它的分量相互独立,假定
是不可观测的n维随机向量,它的分量相互独立,假定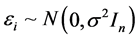 。
。
4.1. 多元线性回归模型
为了确定公路客运量与总人口、国内生产总值、工业生产总值、民用载客汽车拥有量之间的关系,首先建立四元线性回归模型 [7] 。
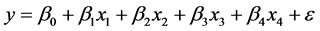 (3)
(3)
在MATLAB中对公路客运量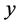 和总人口
和总人口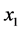 、国内生产总值
、国内生产总值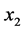 、工业生产总值
、工业生产总值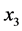 、民用载客汽车拥有量
、民用载客汽车拥有量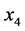 进行拟合可得回归系数、系数置信区间与统计量见表2。
进行拟合可得回归系数、系数置信区间与统计量见表2。
Table 2. Coefficients, confidence intervals and statistics of regression models
表2. 回归模型的系数、系数置信区间与统计量
因此回归模型为
 (4)
(4)
回归模型中的各系数经济学意义解释: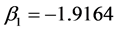 表示在其他条件不变的情况下,总人口每增加1万人公路客运总量会减少1.9164万人,这与事实不符合说明模型不是最优模型,有待改进;
表示在其他条件不变的情况下,总人口每增加1万人公路客运总量会减少1.9164万人,这与事实不符合说明模型不是最优模型,有待改进;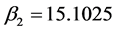 表示在其他条件不变的情况下,国内生产总值每增加1亿元公路客运量增加15.1025万人;
表示在其他条件不变的情况下,国内生产总值每增加1亿元公路客运量增加15.1025万人;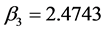 表示在其他条件不变的情况下,工农业总产值每增加1万元公路客运总量增加2.4743万人;
表示在其他条件不变的情况下,工农业总产值每增加1万元公路客运总量增加2.4743万人;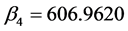 表示在其他条件不变的情况下,民用载客汽车拥有量每增加1万辆公路客运总量增加606.9620万人。
表示在其他条件不变的情况下,民用载客汽车拥有量每增加1万辆公路客运总量增加606.9620万人。
回归模型(4)的可决系数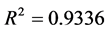 ,
,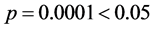 ,因此建立的回归模型有意义。
,因此建立的回归模型有意义。
但由于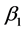 和
和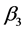 的置信区间包含零点,所以所建立的回归模型不是最优模型,下面对模型进行改进。
的置信区间包含零点,所以所建立的回归模型不是最优模型,下面对模型进行改进。
4.2. 模型的进一步改进
下面对模型进行进一步改进。
得到图形如图1所示,发现有两个异常点,剔除异常点后,重新建模。
仍有异常点继续剔除,直到没有异常点为止。剔除过程如图2~5。
删除异常点后,由残差图5可得此时没有异常点,改进回归模型系数、系数置信区间与统计量见表3。
故改进后的多元回归模型为:
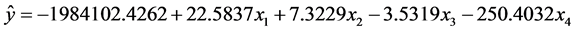 (5)
(5)
将表2与表3加以比较,可以发现,可决系数从0.9336提高到0.9954,F统计量从98.3696提高到1137.7580,删除异常点后的模型每个参数的置信区间进一步缩小,由此可知改进后的模型显著性提高。但是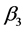 、
、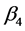 的置信区间仍包含零故模型不是最优模型,再对模型的做进一步改进。
的置信区间仍包含零故模型不是最优模型,再对模型的做进一步改进。
4.3. 改进后的模型与参考文献结果的比较
利用参考文献中的逐步回归法对模型检验然后再与参考文献中的结果作比较。
逐步回归基本原理:在逐步回归中,每当向模型中加入一个变量后,就对原来模型中的变量在新模型下再进行一次向后剔除的检查,直至所有已经在模型中的变量都不能被剔除,而且所有在模型外的变量都不能被加入,过程就终止 [8] 。
逐步回归模型的基本形式为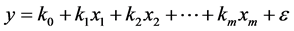 。其中,
。其中,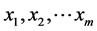 为需求影响因子,
为需求影响因子,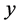 为需求量,
为需求量,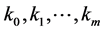 为回归参数,
为回归参数,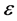 为误差变量,表示除
为误差变量,表示除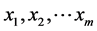 对
对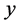 的线性影响之外,其他随机因素对的影响 [9] 。
的线性影响之外,其他随机因素对的影响 [9] 。
由表3知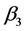 、
、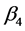 的置信区间包含0,下面采用逐步回归从各个自变量中挑选变量,建立更优回归模型,逐步回归过程见图6~8。
的置信区间包含0,下面采用逐步回归从各个自变量中挑选变量,建立更优回归模型,逐步回归过程见图6~8。
由图8最后得到回归方程(蓝色行是被保留的有效行,红色行表示被剔除的变量):
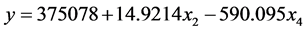 (6)
(6)
回归方程中录用了原始变量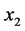 和
和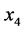 。
。
图8中显示了模型参数分别为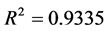 ,修正
,修正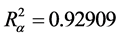 ,
,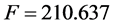 ,与显著性概率相关的
,与显著性概率相关的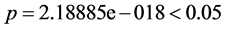 ,残差均方RMSE = 238490 (在逐步回归中,均方残差逐渐减小)。
,残差均方RMSE = 238490 (在逐步回归中,均方残差逐渐减小)。
综上所述,相关参考文献中总人口是唯一的有效变量,其它3个变量即国内生产总值、工农业总产值、客车保有量被剔除。而本文中的逐步回归剔除了农业生产总值和总人口拥有量,选取的变量是国内
Table 3. Coefficients, confidence intervals and statistics of improved regression model
表3. 改进回归模型的系数、系数置信区间与统计量
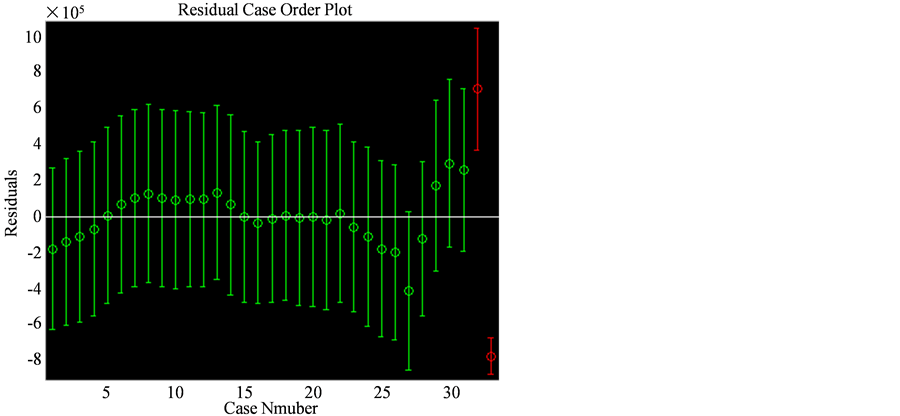
Figure 1. Schematic diagram of residual error
图1. 残差示意图
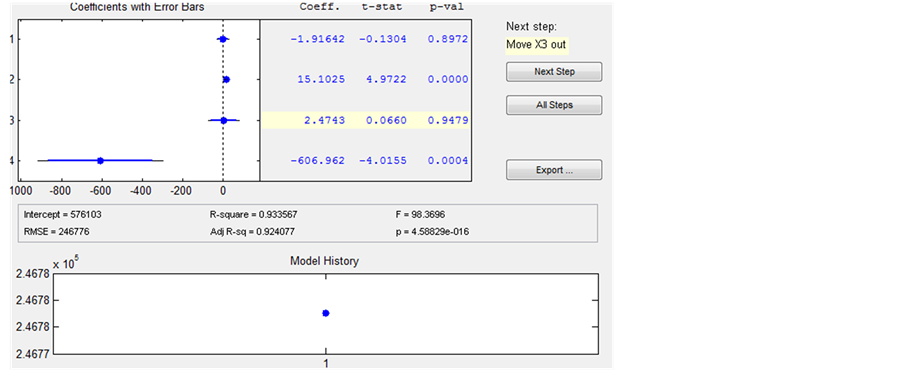
Figure 6. Stepwise regression process I
图6. 逐步回归过程之一
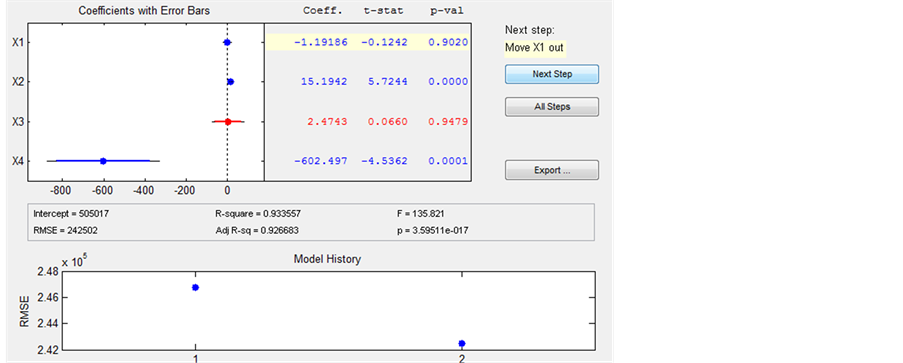
Figure 7. Stepwise regression process II
图7. 逐步回归过程之二

Figure 8. Stepwise regression process III
图8. 逐步回归过程之三
Table 4. Five year value of each index
表4. 各项指标五年数值
Table 5. Compared with the original data values, the fitted value of highway passenger trans- port volume in recent five years
表5. 近五年公路客运量拟合值与原数据对比
生产总值和民用载客汽车。参考文献中选取的是总人口,这是因为我国是一个人口多大国,所以这项变量与公路客运量紧密相连。
5. 模拟实验
为了验证模型的合理性,选取2011~2015年的国内生产总值、民用载客汽车对公路客运量做实证分析,数据如下表4。
5.1. 多元线性回归方程实证分析
将近五年的国内生产总值,民用载客汽车数值带入方程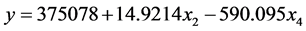 中,得出2011~2015年的客运量,结果与原数据作对比,如表5。
中,得出2011~2015年的客运量,结果与原数据作对比,如表5。
5.2. 预测结果的分析
二元一次模型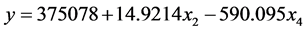 的拟合值与实际值相对误差较小,说明该模型预测公路客运量较为精确。这是因为载客汽车的多少对公路客运总量有着直接的影响,也进一步说明了该模型的实际应用意义。综上可选择民用载客汽车与公路客运量的回归模型来预测公路客运量 [10] 。
的拟合值与实际值相对误差较小,说明该模型预测公路客运量较为精确。这是因为载客汽车的多少对公路客运总量有着直接的影响,也进一步说明了该模型的实际应用意义。综上可选择民用载客汽车与公路客运量的回归模型来预测公路客运量 [10] 。