1. 引言
现实世界中的很多系统都可以用复杂网络模型来描述,复杂网络成为了跨学科的研究热点和研究复杂系统的重要方法。社会网络是复杂网络中的一类,反映了社会成员及其相互关系。随着互联网技术的迅猛发展,人们的生活方式呈现互联网交际、互联网消费、互联网金融或理财等特征,许多的虚拟社会网络不断出现,如社交网(人人网、Facebook)、微博(新浪微博、Twitter)、电子商务网(淘宝、京东、亚马逊)、微信平台等,这些虚拟社会网络聚集了大量用户 [1]。用户处在网络虚拟空间中,却在真实的共享信息和知识、讨论热点事件、交流情感及购物感受、分享生活等,他们是信息的浏览者和接受者,也是互联网信息资源的提供者和传播者,是商品的供应者和潜在的消费者。研究这些用户形成的复杂社会网络具有现实的意义及商业应用的价值,而社会网络中用户的大量社会行为数据被保存在网络空间中,为研究这些大规模社会网络创造了很好的条件。社会网络研究近些年受到了国内外研究者的广泛关注,其中社会网络中社区结构研究更是被多个学科领域所重点关注,并进行了深入探讨和研究,取得了丰硕的成果。但由于社会网络是复杂的且规模庞大的,所以社区检测仍然是有困难的,人们依然在不断的创新并提出新的社区检测的算法。经典的社区检测算法一般是面向结构的分析方法,但随着社会网络分析研究的不断深入,更多的学者提出将社会网络作为一个智能网络系统,网络中的节点作为智能的社会个体,提出了一些基于社会主体(个体)行为的方法,这样的方法分析出的社区结构,是网络中的智能个体,在不断选择和协调的过程中形成的,符合真实社会网络的实质。本文提出的基于合作博弈的社区检测算法,属于一种基于社会个体行为的方法。本文在文献 [2] 提出的合作博弈模型及高效计算Shapley值迭代公式的基础上,展开研究工作,提出了一种以个体理性为核心的合作博弈的社区检测算法,算法是基于网络中个体在不断根据自身利益的抉择及协调的过程中实现社区的检测,算法能够自动确定最终社区划分个数且具有较好的社区检测效果及时间效率。
2. 相关工作
社区检测一直是复杂网络研究领域的热点问题。随着人们对复杂网络中社区检测问题深入而广泛的研究,研究者们提出了很多社区检测算法。其中GN算法 [3] 是目前进行网络社区检测的常用算法,该算法在中小规模的网络中能较好地检测社区。
近年来,研究者们提出了一些较新的算法,如Zhao [4] 等人提出了基于主题为导向的社区划分方法;Shi [5] 等提出了多目标社区检测的算法,其实质是利用计算模块度的公式建立两个函数,将社区检测问题转化了函数最优化问题;Tasgin [6] [7] 等提出了利用遗传算法来完成社区检测,达到了较好的结果;Ahn [8] 等提出了边相似度划分社区的方法,该方法能够找出重叠社区,也称之为边社区;Chen [9] 等人提出了利用社区形成博弈发现社区的算法,其主要的思想是将社区动态形成过程描述成一个策略博弈过程(社区形成博弈),并基于Newman模块度函数提出了一个增益函数和一个损耗函数来反映和衡量一个节点加入社区的得失,在这样的博弈框架下一个社区被解释成一个博弈平衡,由于一个节点可以选择多个社区,因此Chen的算法可以发现重叠社区;Zhou [2] 等人建立了合作博弈社区检测模型,提出了高效计算Shapley值的迭代公式,并设计了一种合作博弈的凝聚层次聚类算法(GAMEHC算法),该算法主要思想是联盟之间相互合作,计算合作带给联盟的收益增量
,并每次取出增量最大的联盟之间的合作,作为一次决策,重复上述决策过程直到所有节点成为一个社区,终止算法。该算法主要是基于合作博弈的方法而Chen等人采用的是策略博弈,是一种非合作博弈的方法。合作博弈是一种强调团体理性的博弈,且个体贡献的收益在团体中被最大化,这符合实际社区以收益最大化形成社区是一致的。社区形成过程近似于合作博弈形成联盟的过程,只是如何构建合作博弈模型,如何分配收,而非合作博弈尽管在实际社区中仍然存在,但难以体现群体形成过程和原因。因此,在文献 [2] 基础上提出本文基于合作博弈的社区检测算法。
3. 基于合作博弈的社区检测算法
本节将阐述本文合作博弈的社区检测算法,首先介绍了相关定义及定理,包括合作博弈模型的社区检测模型定义和高效计算Shapley值的迭代公式定理,然后阐述了本文算法的初检测算法和社区调整算法,最后给出了本文合作博弈的社区检测算法伪代码并分析了算法时间复杂度。
3.1. 相关定义及定理
定义1 [2] 合作博弈的社区检测模型。若
是复杂网络中所有节点的集合,
是复杂网络的邻接矩阵,如果节点
与节点
之间存在边,则
,否则,
,则合作博弈的社区检测模型为
,
是联盟博弈参与节点。合作博弈的特征函数
定义为如下公式:
(1)
其中,
为节点
的度,若
,则
。
,因此
。
为
的子集(联盟)获得的“收益”。这个收益代表着联盟中所有关联的节点的边际贡献的总和。
定理1 [2] 高效计算Shapley值公式。给出社区检测合作博弈模型
,
,
,则
和
在联盟
中的Shapley值计算公式如下:
(2)
其中,
为节点
的度,若
,则
,
同理。
3.2. 初检测算法
合作博弈主要强调的是群体理性,但这种群体理性依然是以个体理性为基础的。因此本文算法首先以个体理性为核心,进行初步检测,再以群体理性做社区调整。初检测算法主要思想是将网络中所有的节点作为合作博弈参与者,每一个节点都观察网络中局势的变化,寻求使得自身收益(Shapley值)最大的节点或簇合作。为保证公平性每一轮决策中,每个节点只有一次机会作出选择。每一个节点作出决策后得到的局势称为策略环境,节点通过多轮决策,当所有节点在某个策略环境下获得Shapley值都不再增大时停止初检测。
初检测算法具体步骤如下:
1) 初始数据为网络
的拓扑结构,即邻接矩阵
。
2) 定义动态集合
,初始化为N个独立节点联盟;初始化一个集合
,其元素为网络中的n个节点,且固定不变。
称为当前策略环境。
3) 设置标识布尔型数组Flag[N],对应每一个节点。标识每一个节点在当前策略环境下合作,获得的SH值是否增大了。
4) 置每个Flag[i] = false,默认值全都为false。
5) 依次循环
当中的每一个节点,与当前集合
中的不包含自身的其他联盟合作,根据
公式计算获得的SH值,若能获得SH值大于在原来联盟中的SH值,则选择退出原来联盟加入使其获得更大SH值的联盟合作,并设置对应节点Flag[i]为True;若不能,则不做任何操作。
6) 判断
中节点是否循环结束,若结束求表达式Flag[0] or Flag[1] or … or Flag[N]的值,如果表达式为True(表示存在任意一个或多个节点的SH值增大了),跳转执行步骤4、5,否则退出算法,返回初步检测结果
(表示所有节点的SH值都没有增大,达到SH平衡)。
3.3. 社区调整算法
根据初检测算法,会得到一些不合理、无意的小簇,这些簇不具有社区的典型特征——社区内部连接紧密,社区之间连接稀疏(一般社区内部边>社区外部边),即不可以称之为社区。为了解决该问题,使得最终社区检测结果中的簇具有明显的社区结构,设计了调整这些小簇的社区调整算法。通过调整最终将网络划分成了多个具有明显社区特征的社区。社区调整算法步骤如下:
1) 计算簇
的内部边为
,外部边为
。
2) 若
,计算社区
与其他各簇之间的连接边数,找出与
连接边数最大的簇
。
3) 将
与
进行合并。
该社区调整方案的合理性可以基于合作博弈的群体理性得到解释。假如簇
与
进行合并,由公式(2)可得,簇
中每个节点
的SH值增量为
,由此得簇
与
合并时,社区
所有节点的SH值增量的总和为
,若要使得
最大,可以近似的看成与
连接边最多的簇
,可以使得
最大。
3.4. 基于合作博弈的社区检测算法
基于合作博弈的社区检测算法(Community Detection based on Cooperative Game,简写为CDCG)分为初检测和社区调整两个步骤,在本章3.2和3.3节已经分别详细阐述了两个算法的步骤,本节给出算法CDCG伪代码描述。
算法CDCG伪代码描述:
输入:
,//网络中节点的集合
,//网络的邻接矩阵
输出:
(1)
;
(2)
;//定义一个集合
(3)
(4)
;
(5)
(6)
;
//初始化联盟,将一个节点作为一个联盟
(7)
//仍然存在节点在其他联盟中能获得较大值
(7.1)
;
(7.2)
//测试每一个节点加入各社区,获得最大SH值则加入
(7.2.1)
(7.2.2)
{
;
;
//如果节点SH值增大,给标识赋值true
}
//或者直接将该点从
中去除。
//end 7.2
/*end 7
(8)
;//社区调整
(9)
//输出最终社区划分
时间复杂度分析:
若在网络中有
个节点,在算法中
循环是算法主要的时间耗费,步骤7.1时间复杂性为
;步骤7.2,
中元素个数为
;
中最坏情况也
个元素;因此时间复杂性最坏情况为
。若执行
轮决策,可以使得每一个节点的SH值不再增大,则步骤7的时间复杂度约为
。步骤8的时间复杂度最坏情况为
。因此,本文合作博弈社区检测算法时间复杂度为
,其中
。
3.5. 优化剪枝策略
CDCG算法主要时间耗费在初检测过程,但该过程存在冗余计算与比较。因此,为了更好的提高算法的时间效率,根据初检测算法执行策略,定义了无贡献节点和已归属节点。无贡献节点是指一个节点与其合作的对象(节点或簇)无任何连接边。该节点不会对其自身及合作对象产生SH值贡献,可以进行剪枝。已归属节点是指一个节点的度已经全部存在于一个簇中时,它SH值已经不会再增大。因此,该节点已经不需要参加下一轮决策,可以进行剪枝。
在3.5.1节与3.5.2节分别给出了无贡献节点和已归属节点的形式化定义,给出了无贡献节点剪枝与已归属节点剪枝的伪代码描述。
3.5.1. 无贡献节点剪枝
定义2 无贡献节点
网络邻接矩阵
,存在节点
和当前联盟
,若任意的
均为0,则称
为联盟
的无贡献节点。
无贡献节点剪枝方法伪代码描述:
/*
为当前节点,
为当前联盟,
为邻接矩阵*/
;
//判断是否有边相连
;
;
{
;}
{
;}
3.5.2. 已归属节点剪枝
定义3 已归属节点
网络邻接矩阵
,存在节点
属于联盟
,设节点
在整个网络中的度为
,且节点
在
内的度为
,若
,则称节点
为已归属节点。
证明:存在网络
,其邻接矩阵为
,
表示节点
在网络中的度。若有节点
属于联盟
,
表示节点
在
内的度。
Þ节点
仅与
内的节点有连接,则当有任意节点
加入当前联盟
,根据
Þ节点
的SH值不再变化且达到最大。
Þ节点
为已归属节点。
已归属节点剪枝方法伪代码描述:
//
为当前节点,
为联盟,
为邻接矩阵
;
;
;
{
;}
{
;}
4. 实验分析
本文将从算法社区检测的效果、时间效率等方面对本文所提算法进行评估。算法采用的编程语言为C#,开发平台:Microsoft Visual Studio 2010;实验使用的计算机配置:Intel(R)Core(TM) i3
-2330M
CPU @ 2.20 GHz,
4G
内存;64位操作系统:Windows7操作系统;
4.1. 实验数据
1) 128个节点的ad hoc网络。该网络在多篇文章中作为典型基准网络 [2] [10] - [12],用于验证社区检测算法的有效性。它主要特点是已知社团结构,具体构造如下:选取n = 128个节点,分成4个社团,每个社团包含32个节点,网络的平均度为16,
为某节点与属于其它社团节点之间连接的期望值,
越大社区结构越模糊,通过控制参数
,观察社区划分情况。
社区检测的准确性用归一化互信息(Normalized Mutual Information, NMI)来衡量 [11]。归一化互信息定义如下:
为实际的社区划分,
为算法得出的社区划分,NMI(X,Y)表示算法得出的社区划分结果与实际社区划分之间的相似程度,取值范围为0~1,其值越大算法所得的社区结构与真实社去结构越接近,NMI = 1表示所得结果与真实社区划分完全一致。NMI=0时表示算法得到的划分与真实划分完全不同。公式中的
为一个模糊矩阵,其中行对应真实社区,列对应算法找到的社区。
中的一个元素
表示出现在找到的社团
中的真实社团
中的节点数目。
为真实社区的数目,
为算法找到的社区的数目。
2) 空手道俱乐部网络。这个网络是由Zachary [13] 在观察一所美国大学空手道俱乐部成员之间的社会联系而构建的。由于俱乐部的管理者和主教练之间发生争吵,于是俱乐部分裂成两个小俱乐部。在空手道俱乐部网络中有34个节点,每个节点表示俱乐部中的一个成员。在文献 [13] 中,Zachary给出了该网络自然划分如图3所示,白色和黑色分别代表不同的社区。这个网络广泛地应用于验证网络社区检测的算法。
3) 海豚网络。海豚网络是由Lusseau [14] 对62只尖嘴海豚之间的频繁联系所构成的无向社会网络。这个网络有62个节点,被广泛认同的GN-2社区划分如图8所示。该网络也广泛地应用于验证网络社区检测的算法。
4) LFR基准网络 [15]。LFR基准网络是一种构造的现实主义的网络,能够用于研究社区结构,被广泛应用于测试社区检测算法的性能。LFR基准网络的特点是节点度和社团规模的非均匀性,它能根据用户指定的分布生成更接近真实情况的网络。这里分布不仅包括网络中节点度的分布,而且包括各个社区中节点数的分布。文献 [15] 给出了LFR基准网络构造算法,源程序来源于Santo Fortunat的网站: https://sites.google.com/site/santofortunato/inthepress2。
LFR基准网络:LRF(N, k, maxk, mu, minc, maxc),其中参数N为节点个数,k为平均度,maxk为最大度,mu为节点外部/总度数,minc为最小社区中节点个数,maxc为最大社区中节点个数。调整参数N变化网络的规模,固定其他各参数变量得到不同规模的网络。本文实验中将利用该模型构建不同规模的网络对比算法的时间效率。
4.2. 实验分析
1) 128个节点的ad hoc网络。通过控制Zout,从1变化到8,比较了GN算与本文算法NMI值的变化,如图1所示。由于该网络生成具有随机性,对于每个Zout本文重复做了100次实验,各数值是100次重复试验的平均值。由图可以看出当Zout从1增加8时,该模拟网络社团结构由清晰变得模糊,所以NMI曲线呈现递减趋势。本算法在Zout = 1~4正确划分准确率为100%,Zout ³ 5之后,准确性开始下降,随着Zout值的增大,其下降的速度要快于GN算法。GN算法Zout ³ 6之后,准确性才开始下降。因此本文算法在社区结构比较明显的网络中,检测效果较好。
2) 空手道俱乐部网络。运用该网络比较了本文算法初检测的社区效果与社区调整后的社区效果,比较了GN算法与本文算法的社区检测的结果。从图2与图4看出,初检测结果出现了规模小的、不合理的社区,在社区调整后得到了较为合理的社区划分。观察比较图3与图4,本文算法在空手道俱乐部网络中划分效果与自然划分有所区别,将{5,6,7,11,17}作为了一个单独的社区划分,节点10划分错误,其他各节点的划分均与实际社区划分一致。与GN算法比较,本文算法划分成了3个社区,GN算法划分成了2个社区,如图5所示。本文算法划分成3个社区,具有合理性。若从模块度(
值)的角度网络自然划分时
值为:0.365;GN算法划分最大
值为:0.353;本文算法划分结果的
值为:0.396。从以上
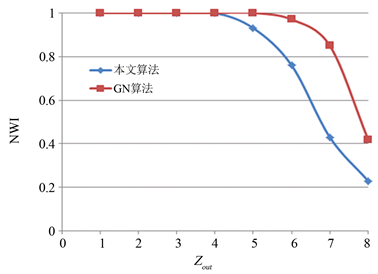
Figure 1. Comparison of community detection accuracy
图1. 社区检测准确度比较

Figure 2. Effect of initial detection of the community
图2. 初检测的社区效果

Figure 3. Natural division of the Karate Club network [13]
图3. 空手道俱乐部网络的自然划分 [13]

Figure 4. The effect of community adjusted community
图4. 社区调整后社区效果
分析知,本文在俱乐部网络中社区划分效果良好,且算法结束得到确定的社区个数。
3) 海豚网络。运用该网络比较了本文算法在初检测的社区效果与社区调整后的社区效果;比较了本文算法与GN算法-2社区状态下的社区检测效果。观察图6与图7,可知在初检测结果中由于一些边缘节点及形成闭合回路的节点,造成了一些小的簇出现,在社区调整后,很好的将这些簇进行了归属。从图7和图8对比知,仅有节点8,节点20与GN算法-2社区情况下划分不同,说明本文算法在海豚网络中社区划分效果良好。
4) LRF随机基准网络。
图9利用LRF基准网络,随机生成了网络中节点个数分别为100,200,300,400,500,600的数据集,比较了GN算法、与本文算法的时间效率。随机生成LRF基准网络采用参数列表如下:
保持其他参数不变,改变网络规模N,随机生成不同规模的LRF基准网络。由于GN算法与本文算法在网络中节点个数相同的情况下运行时间差异较大,为更好的比较二者之间的时间效率,将实际运行时间取以10为底的对数进行处理,该函数为单调递增函数,不会使曲线趋势发生变化,且直观的反映数

Figure 5. GN algorithm-maximum Modularity of community detection effect [2]
图5. GN算法–最大模块度时的社区效果 [2]

Figure 6. Effect of initial detection of the community
图6. 初检测的社区效果
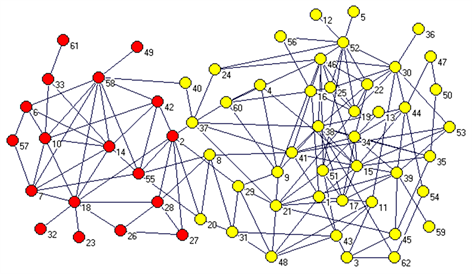
Figure 7. The effect of community adjusted community
图7. 社区调整后社区效果

Figure 8. GN algorithm-effect of The Dolphin network is divided two community
图8. GN算法–海豚网划分为2个社区的效果
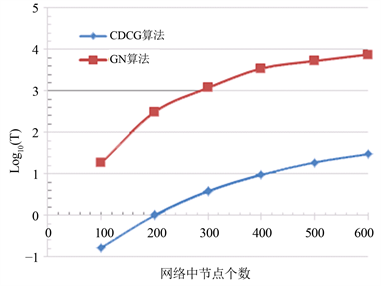
Figure 9. Efficiency comparison of GN algorithm and CDCG algorithm
图9. GN算法与本文算法时间效率比较

Figure 10. Time effect of pruning CDCG algorithm
图10. 带剪枝算法运行时间效果
量级区别。图9中横坐标为网络规模,纵坐标为log10(T),T为算法实际运行时间。从图9可以看到,GN算法、本文算法随着网络中节点数目的不断增大,算法运行时间呈上升趋势,但本文算法运行时间明显优于GN算法且在相同网络规模下是数量级的差距。说明随着网络规模的增大有较好的时间效率。
图10利用LRF基准网络,随机生成了网络中节点个数分别为1000, 2000, 3000, 4000, 5000的数据集,比较了不带剪枝合作博弈检测算法与带剪枝算法时间的效率。LRF基准网络采用参数列表如下:
由图10可以看出,随着网络规模的增大,算法的运行时间呈上升趋势。带剪枝的算法具有一定的剪枝效果。但节点规模较小时,剪枝效果不明显。当节点的平均度不发生变化时,增大网络的规模,无贡献节点就会增多,且随着算法的执行有更多的节点很快找到联盟归属,因此,带剪枝的算法会在节点平均度不变时,网络规模越大,剪枝效果越明显。但如果网络规模的增大,节点平均度数增加,可能将不会有明显剪枝效果。
5. 总结
本文探索了一种在社会个体行为基础上的合作博弈的社区检测算法,该算法由初检测和社区调整两部分组成。首先,介绍了文中采用的合作博弈的特征函数及高效计算Shapley值公式,其次,根据合作博弈中个体理性为核心设计了初检测算法,在初检测算法结果的基础上,利用社区内部连接紧密,社区之间连接稀疏的特征,判断出不合理、无意的小簇,设计调整算法。为了更好的提高算法效率,提出了无贡献节点剪枝策略及归属节点剪枝策略。最后,编程实现了基于合作博弈的社区检测算法,通过实验分析验证了本文算法具有较好社区检测效果及时间效率。
基金项目
国家自然科学基金(61262069)。
[1] 孟小峰, 余力 (2011) 用社会化方法计算社会. 中国计算机学会通讯, 7, 25-30.
[2] Zhou, L.H., Cheng, C., Lv, K. and Chen, H.M. (2013) Using coalitional games to detect communities in social networks. Web-Age Information Management, Springer, Berlin, 326-331.
[3] Girvan, M. and Newman, M.E.J. (2002) Community structure in social and biological networks. Proceedings of the National Academy of Sciences, 99, 7821.
[4] Zhao, Z.Y., Feng, S.Z., Wang, Q., Huang, Z.X., Williams, G.J. and Fan, J.P. (2012) Topic oriented community detection through social objects and link analysis in social networks. Knowledge-Based Systems, 26, 164-173.
[5] Shi, C., Yan, Z.Y., Cai, Y.N. and Wu, B. (2012) Multi-objective community detection in complex networks. Applied Soft Computing, 850-859.
[6] Tasgin, M., Herdagdelen, A. and Bingol, H. (2007) Community detection in complex networks using genetic algorithms.
[7] Pizzuti, C. (2009) A multi-objective genetic algorithm for community detection in networks. The 21st IEEE International Conference on Tools with Artificial Intelligence.
[8] Ahn, Y.-Y., Bagrow, J.P. and Lehmann, S. (2010) Link communities reveal multiscale complexity in networks. Nature, 466, Article ID: 09182.
[9] Chen, W., Liu, Z.M., Sun, X.R. and Wang, Y.J. (2011) Community detection in social networks through community formation games. Proceedings of IJCAI, 3, 2576-2581.
[10] Fortunato, S. (2010) Community detection in graphs. Physics Reports, 486, 75-174.
[11] Danon, L., Diaz-Guilera, A., Duch, J. and Arenas, A. (2005) Comparing community structure identification. Journal of Statistical Mechanics: Theory and Experiment, Article ID: P09008.
[12] Newman, M.E.J. and Girvan, M. (2004) Finding and evaluating community structure in networks. Physical Review E, 69, Article ID: 026113.
[13] Zachary, W.W. (1977) An information flow model for conflict and fission in small groups. Journal of Anthropological Research, 33, 452-473.
[14] Lusseau, D. and Newman, M.E.J. (2004) Identifying the role that animals play in their social networks. Proceedings of the Royal Society, 271, 477-481.
[15] Lancichinetti, A., Fortunato, S. and Radicchi, F. (2008) Benchmark graphs for testing community detection algorithms. Physical Review E, 78, Article ID: 046110.
NOTES
*通讯作者。